 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label natural language processing to identify diagnosis and procedure codes from MIMIC-III inpatient notes
Mar 17, 2020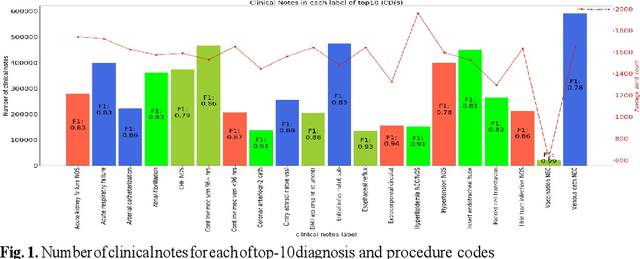
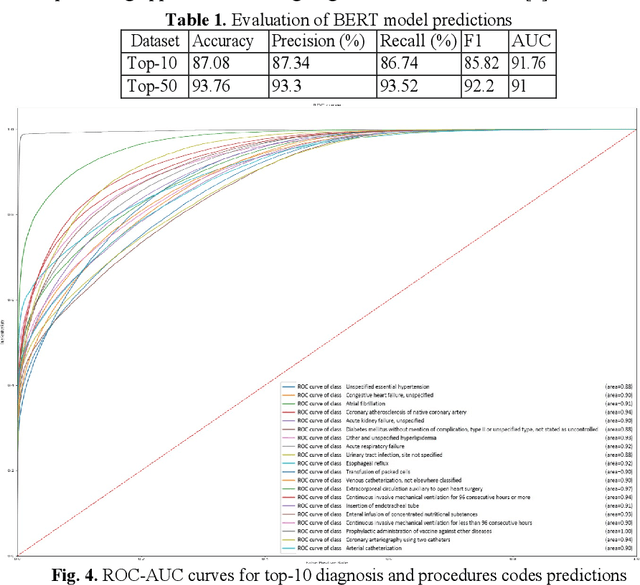
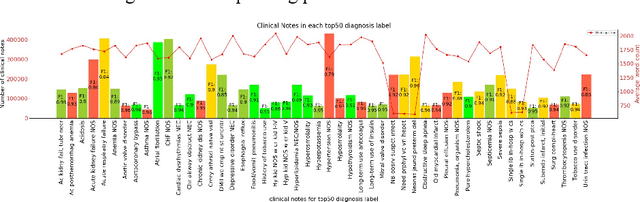
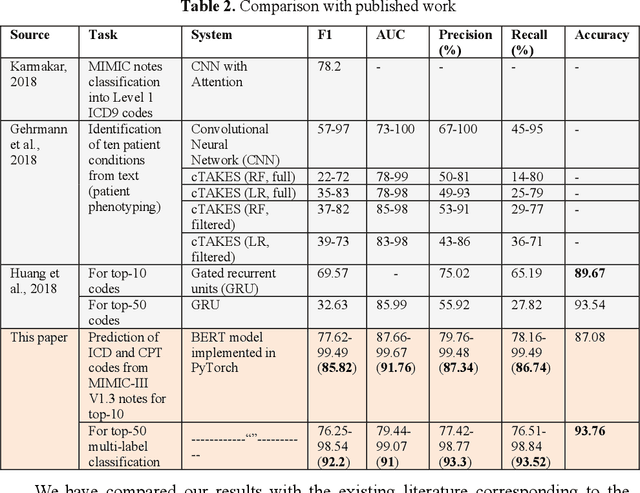
In the United States, 25% or greater than 200 billion dollars of hospital spending accounts for administrative costs that involve services for medical coding and billing. With the increasing number of patient records, manual assignment of the codes performed is overwhelming, time-consuming and error-prone, causing billing errors. Natural language processing can automate the extraction of codes/labels from unstructured clinical notes, which can aid human coders to save time, increase productivity, and verify medical coding errors. Our objective is to identify appropriate diagnosis and procedure codes from clinical notes by performing multi-label classification. We used de-identified data of critical care patients from the MIMIC-III database and subset the data to select the ten (top-10) and fifty (top-50) most common diagnoses and procedures, which covers 47.45% and 74.12% of all admissions respectively. We implemented state-of-the-art Bidirectional Encoder Representations from Transformers (BERT) to fine-tune the language model on 80% of the data and validated on the remaining 20%. The model achieved an overall accuracy of 87.08%, an F1 score of 85.82%, and an AUC of 91.76% for top-10 codes. For the top-50 codes, our model achieved an overall accuracy of 93.76%, an F1 score of 92.24%, and AUC of 91%. When compared to previously published research, our model outperforms in predicting codes from the clinical text. We discuss approaches to generalize the knowledge discovery process of our MIMIC-BERT to other clinical notes. This can help human coders to save time, prevent backlogs, and additional costs due to coding errors.