 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Locally Executable AI System for Improving Preoperative Patient Communication: A Multi-Domain Clinical Evaluation
Oct 02, 2025Patients awaiting invasive procedures often have unanswered pre-procedural questions; however, time-pressured workflows and privacy constraints limit personalized counseling. We present LENOHA (Low Energy, No Hallucination, Leave No One Behind Architecture), a safety-first, local-first system that routes inputs with a high-precision sentence-transformer classifier and returns verbatim answers from a clinician-curated FAQ for clinical queries, eliminating free-text generation in the clinical path. We evaluated two domains (tooth extraction and gastroscopy) using expert-reviewed validation sets (n=400/domain) for thresholding and independent test sets (n=200/domain). Among the four encoders, E5-large-instruct (560M) achieved an overall accuracy of 0.983 (95% CI 0.964-0.991), AUC 0.996, and seven total errors, which were statistically indistinguishable from GPT-4o on this task; Gemini made no errors on this test set. Energy logging shows that the non-generative clinical path consumes ~1.0 mWh per input versus ~168 mWh per small-talk reply from a local 8B SLM, a ~170x difference, while maintaining ~0.10 s latency on a single on-prem GPU. These results indicate that near-frontier discrimination and generation-induced errors are structurally avoided in the clinical path by returning vetted FAQ answers verbatim, supporting privacy, sustainability, and equitable deployment in bandwidth-limited environments.
Addressee and Response Selection for Multilingual Conversation
Aug 12, 2018



Developing conversational systems that can converse in many languages is an interesting challenge for natural language processing. In this paper, we introduce multilingual addressee and response selection. In this task, a conversational system predicts an appropriate addressee and response for an input message in multiple languages. A key to developing such multilingual responding systems is how to utilize high-resource language data to compensate for low-resource language data. We present several knowledge transfer methods for conversational systems. To evaluate our methods, we create a new multilingual conversation dataset. Experiments on the dataset demonstrate the effectiveness of our methods.
Interpretable Adversarial Perturbation in Input Embedding Space for Text
May 08, 2018


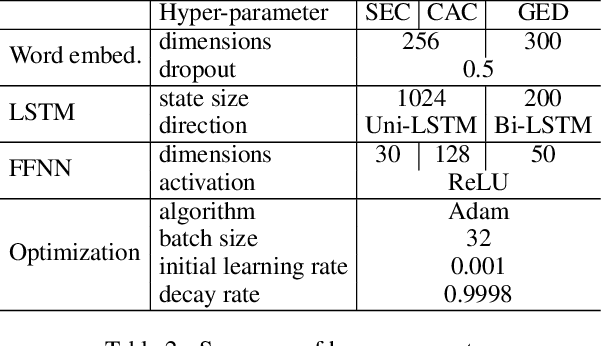
Following great success in the image processing field, the idea of adversarial training has been applied to tasks in the natural language processing (NLP) field. One promising approach directly applies adversarial training developed in the image processing field to the input word embedding space instead of the discrete input space of texts. However, this approach abandons such interpretability as generating adversarial texts to significantly improve the performance of NLP tasks. This paper restores interpretability to such methods by restricting the directions of perturbations toward the existing words in the input embedding space. As a result, we can straightforwardly reconstruct each input with perturbations to an actual text by considering the perturbations to be the replacement of words in the sentence while maintaining or even improving the task performance.
* 8 pages, 4 figures
Ensemble of Neural Classifiers for Scoring Knowledge Base Triples
Apr 05, 2017

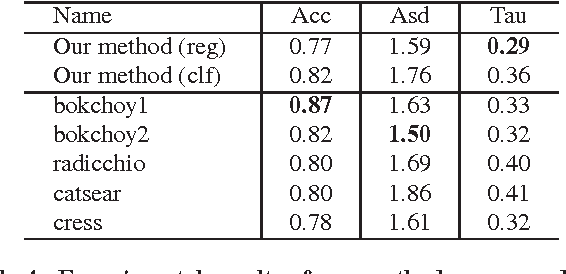
This paper describes our approach for the triple scoring task at the WSDM Cup 2017. The task required participants to assign a relevance score for each pair of entities and their types in a knowledge base in order to enhance the ranking results in entity retrieval tasks. We propose an approach wherein the outputs of multiple neural network classifiers are combined using a supervised machine learning model. The experimental results showed that our proposed method achieved the best performance in one out of three measures (i.e., Kendall's tau), and performed competitively in the other two measures (i.e., accuracy and average score difference).