 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPENCE: A Syntactic Probe for Detecting Contamination in NL2SQL Benchmarks
Apr 20, 2026Large language models (LLMs) have achieved strong performance on natural language to SQL (NL2SQL) benchmarks, yet their reported accuracy may be inflated by contamination from benchmark queries or structurally similar patterns seen during training. We introduce SPENCE (Syntactic Probing and Evaluation of NL2SQL Contamination Effects), a controlled syntactic probing framework for detecting and quantifying such contamination. SPENCE systematically generates syntactic variants of test queries for four widely used NL2SQL datasets-Spider, SParC, CoSQL, and the newer BIRD benchmark. We use SPENCE to evaluate multiple high-capacity LLMs under execution-based scoring. For each model, we measure changes in execution accuracy across increasing levels of syntactic divergence and quantify rank sensitivity using Kendall's tau with bootstrap confidence intervals. By aligning these robustness trends with benchmark release dates, we observe a clear temporal gradient: older benchmarks such as Spider exhibit the strongest negative values and thus the highest likelihood of training leakage, whereas the more recent BIRD dataset shows minimal sensitivity and appears largely uncontaminated. Together, these findings highlight the importance of temporally contextualized, syntactic-probing evaluation for trustworthy NL2SQL benchmarking.
When Vision-Language Models Judge Without Seeing: Exposing Informativeness Bias
Apr 20, 2026The reliability of VLM-as-a-Judge is critical for the automatic evaluation of vision-language models (VLMs). Despite recent progress, our analysis reveals that VLM-as-a-Judge often pays limited attention to the image when making decisions. Instead, they often blindly favor the more informative answer, even when they can recognize it conflicts with the image content. We call this problem informativeness bias, which significantly undermines judge reliability. To address it, we propose BIRCH (Balanced Informativeness and CoRrectness with a Truthful AnCHor), a judging paradigm that first corrects inconsistencies with the image content in candidate answers, and then compares the answers against this corrected version. This shifts the judge's focus from informativeness to image-grounded correctness. Experiments on multiple models and benchmarks show that BIRCH reduces informativeness bias by up to 17%, resulting in performance gains of up to 9.8%. Our work reveals an overlooked but fundamental flaw in current VLM-as-a-Judge systems and highlights the need for more principled designs.
Evaluating NL2SQL via SQL2NL
Sep 04, 2025Robust evaluation in the presence of linguistic variation is key to understanding the generalization capabilities of Natural Language to SQL (NL2SQL) models, yet existing benchmarks rarely address this factor in a systematic or controlled manner. We propose a novel schema-aligned paraphrasing framework that leverages SQL-to-NL (SQL2NL) to automatically generate semantically equivalent, lexically diverse queries while maintaining alignment with the original schema and intent. This enables the first targeted evaluation of NL2SQL robustness to linguistic variation in isolation-distinct from prior work that primarily investigates ambiguity or schema perturbations. Our analysis reveals that state-of-the-art models are far more brittle than standard benchmarks suggest. For example, LLaMa3.3-70B exhibits a 10.23% drop in execution accuracy (from 77.11% to 66.9%) on paraphrased Spider queries, while LLaMa3.1-8B suffers an even larger drop of nearly 20% (from 62.9% to 42.5%). Smaller models (e.g., GPT-4o mini) are disproportionately affected. We also find that robustness degradation varies significantly with query complexity, dataset, and domain -- highlighting the need for evaluation frameworks that explicitly measure linguistic generalization to ensure reliable performance in real-world settings.
Interpreting a Machine Learning Model for Detecting Gravitational Waves
Feb 15, 2022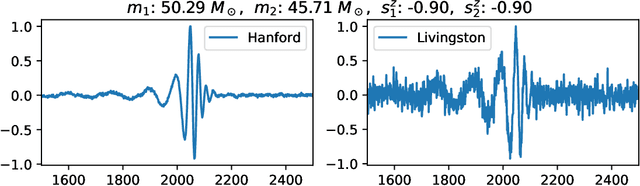
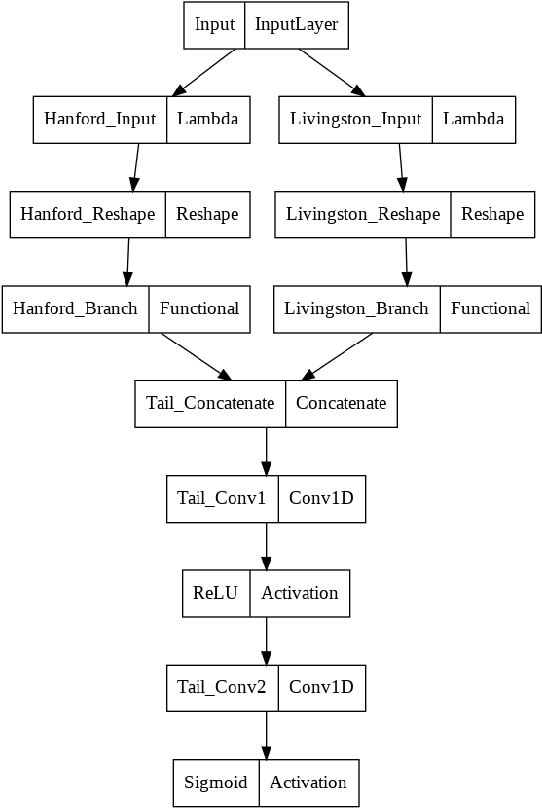
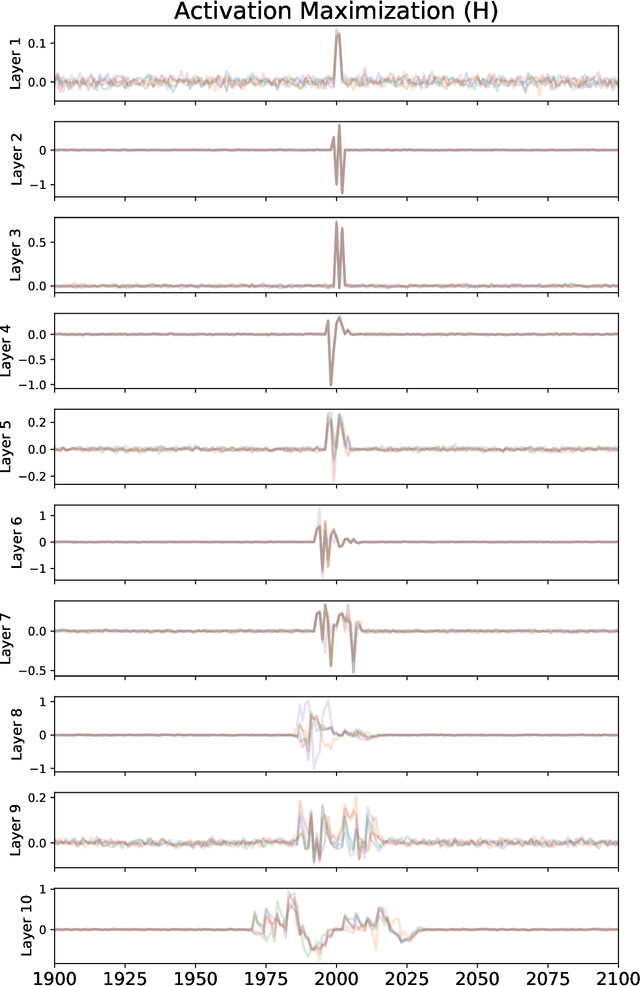
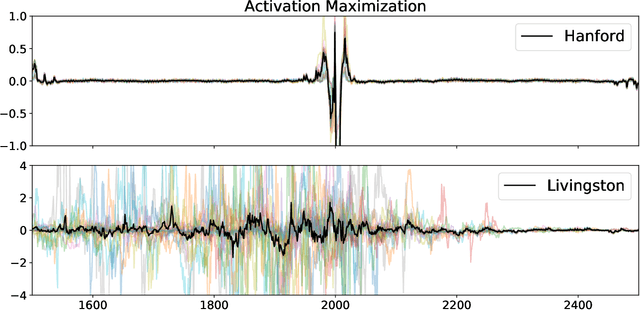
We describe a case study of translational research, applying interpretability techniques developed for computer vision to machine learning models used to search for and find gravitational waves. The models we study are trained to detect black hole merger events in non-Gaussian and non-stationary advanced Laser Interferometer Gravitational-wave Observatory (LIGO) data. We produced visualizations of the response of machine learning models when they process advanced LIGO data that contains real gravitational wave signals, noise anomalies, and pure advanced LIGO noise. Our findings shed light on the responses of individual neurons in these machine learning models. Further analysis suggests that different parts of the network appear to specialize in local versus global features, and that this difference appears to be rooted in the branched architecture of the network as well as noise characteristics of the LIGO detectors. We believe efforts to whiten these "black box" models can suggest future avenues for research and help inform the design of interpretable machine learning models for gravitational wave astrophysics.