 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cost-Aware Mechanism for Optimized Resource Provisioning in Cloud Computing
Sep 20, 2023Due to the recent wide use of computational resources in cloud computing, new resource provisioning challenges have been emerged. Resource provisioning techniques must keep total costs to a minimum while meeting the requirements of the requests. According to widely usage of cloud services, it seems more challenging to develop effective schemes for provisioning services cost-effectively; we have proposed a novel learning based resource provisioning approach that achieves cost-reduction guarantees of demands. The contributions of our optimized resource provisioning (ORP) approach are as follows. Firstly, it is designed to provide a cost-effective method to efficiently handle the provisioning of requested applications; while most of the existing models allow only workflows in general which cares about the dependencies of the tasks, ORP performs based on services of which applications comprised and cares about their efficient provisioning totally. Secondly, it is a learning automata-based approach which selects the most proper resources for hosting each service of the demanded application; our approach considers both cost and service requirements together for deploying applications. Thirdly, a comprehensive evaluation is performed for three typical workloads: data-intensive, process-intensive and normal applications. The experimental results show that our method adapts most of the requirements efficiently, and furthermore the resulting performance meets our design goals.
Dynamic Pricing of Applications in Cloud Marketplaces using Game Theory
Sep 20, 2023

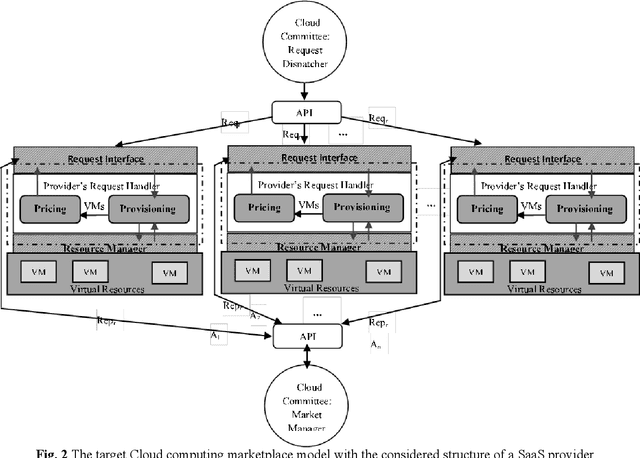
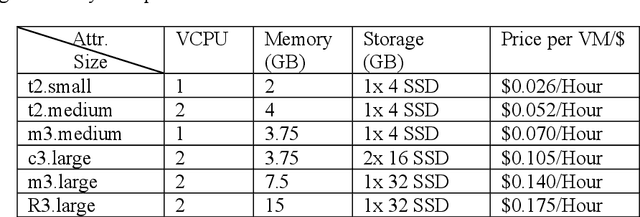
The competitive nature of Cloud marketplaces as new concerns in delivery of services makes the pricing policies a crucial task for firms. so that, pricing strategies has recently attracted many researchers. Since game theory can handle such competing well this concern is addressed by designing a normal form game between providers in current research. A committee is considered in which providers register for improving their competition based pricing policies. The functionality of game theory is applied to design dynamic pricing policies. The usage of the committee makes the game a complete information one, in which each player is aware of every others payoff functions. The players enhance their pricing policies to maximize their profits. The contribution of this paper is the quantitative modeling of Cloud marketplaces in form of a game to provide novel dynamic pricing strategies; the model is validated by proving the existence and the uniqueness of Nash equilibrium of the game.
New intelligent defense systems to reduce the risks of Selfish Mining and Double-Spending attacks using Learning Automata
Jul 02, 2023



In this paper, we address the critical challenges of double-spending and selfish mining attacks in blockchain-based digital currencies. Double-spending is a problem where the same tender is spent multiple times during a digital currency transaction, while selfish mining is an intentional alteration of a blockchain to increase rewards to one miner or a group of miners. We introduce a new attack that combines both these attacks and propose a machine learning-based solution to mitigate the risks associated with them. Specifically, we use the learning automaton, a powerful online learning method, to develop two models, namely the SDTLA and WVBM, which can effectively defend against selfish mining attacks. Our experimental results show that the SDTLA method increases the profitability threshold of selfish mining up to 47$\%$, while the WVBM method performs even better and is very close to the ideal situation where each miner's revenue is proportional to their shared hash processing power. Additionally, we demonstrate that both methods can effectively reduce the risks of double-spending by tuning the $Z$ Parameter. Our findings highlight the potential of SDTLA and WVBM as promising solutions for enhancing the security and efficiency of blockchain networks.
VDHLA: Variable Depth Hybrid Learning Automaton and Its Application to Defense Against the Selfish Mining Attack in Bitcoin
Feb 15, 2023

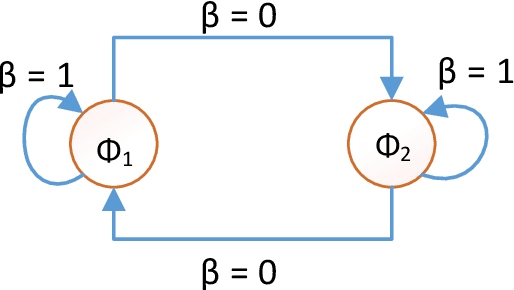

Learning Automaton (LA) is an adaptive self-organized model that improves its action-selection through interaction with an unknown environment. LA with finite action set can be classified into two main categories: fixed and variable structure. Furthermore, variable action-set learning automaton (VASLA) is one of the main subsets of variable structure learning automaton. In this paper, we propose VDHLA, a novel hybrid learning automaton model, which is a combination of fixed structure and variable action set learning automaton. In the proposed model, variable action set learning automaton can increase, decrease, or leave unchanged the depth of fixed structure learning automaton during the action switching phase. In addition, the depth of the proposed model can change in a symmetric (SVDHLA) or asymmetric (AVDHLA) manner. To the best of our knowledge, it is the first hybrid model that intelligently changes the depth of fixed structure learning automaton. Several computer simulations are conducted to study the performance of the proposed model with respect to the total number of rewards and action switching in stationary and non-stationary environments. The proposed model is compared with FSLA and VSLA. In order to determine the performance of the proposed model in a practical application, the selfish mining attack which threatens the incentive-compatibility of a proof-of-work based blockchain environment is considered. The proposed model is applied to defend against the selfish mining attack in Bitcoin and compared with the tie-breaking mechanism, which is a well-known defense. Simulation results in all environments have shown the superiority of the proposed model.
Nik Defense: An Artificial Intelligence Based Defense Mechanism against Selfish Mining in Bitcoin
Jan 26, 2023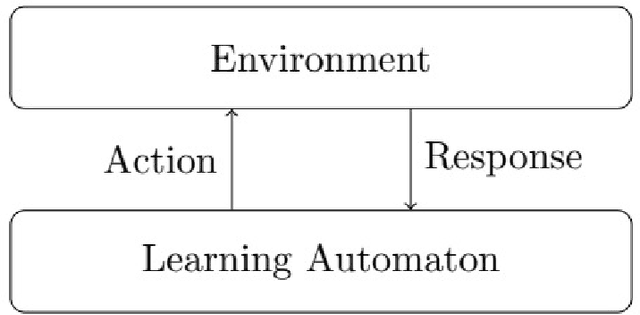



The Bitcoin cryptocurrency has received much attention recently. In the network of Bitcoin, transactions are recorded in a ledger. In this network, the process of recording transactions depends on some nodes called miners that execute a protocol known as mining protocol. One of the significant aspects of mining protocol is incentive compatibility. However, literature has shown that Bitcoin mining's protocol is not incentive-compatible. Some nodes with high computational power can obtain more revenue than their fair share by adopting a type of attack called the selfish mining attack. In this paper, we propose an artificial intelligence-based defense against selfish mining attacks by applying the theory of learning automata. The proposed defense mechanism ignores private blocks by assigning weight based on block discovery time and changes current Bitcoin's fork resolving policy by evaluating branches' height difference in a self-adaptive manner utilizing learning automata. To the best of our knowledge, the proposed protocol is the literature's first learning-based defense mechanism. Simulation results have shown the superiority of the proposed mechanism against tie-breaking mechanism, which is a well-known defense. The simulation results have shown that the suggested defense mechanism increases the profit threshold up to 40\% and decreases the revenue of selfish attackers.
Solving Minimum Vertex Cover Problem Using Learning Automata
Nov 28, 2013



Minimum vertex cover problem is an NP-Hard problem with the aim of finding minimum number of vertices to cover graph. In this paper, a learning automaton based algorithm is proposed to find minimum vertex cover in graph. In the proposed algorithm, each vertex of graph is equipped with a learning automaton that has two actions in the candidate or non-candidate of the corresponding vertex cover set. Due to characteristics of learning automata, this algorithm significantly reduces the number of covering vertices of graph. The proposed algorithm based on learning automata iteratively minimize the candidate vertex cover through the update its action probability. As the proposed algorithm proceeds, a candidate solution nears to optimal solution of the minimum vertex cover problem. In order to evaluate the proposed algorithm, several experiments conducted on DIMACS dataset which compared to conventional methods. Experimental results show the major superiority of the proposed algorithm over the other methods.
Finding a Maximum Clique using Ant Colony Optimization and Particle Swarm Optimization in Social Networks
Nov 28, 2013


Interaction between users in online social networks plays a key role in social network analysis. One on important types of social group is full connected relation between some users, which known as clique structure. Therefore finding a maximum clique is essential for some analysis. In this paper, we proposed a new method using ant colony optimization algorithm and particle swarm optimization algorithm. In the proposed method, in order to attain better results, it is improved process of pheromone update by particle swarm optimization. Simulation results on popular standard social network benchmarks in comparison standard ant colony optimization algorithm are shown a relative enhancement of proposed algorithm.
Tracking Extrema in Dynamic Environment using Multi-Swarm Cellular PSO with Local Search
Jul 31, 2013



Many real-world phenomena can be modelled as dynamic optimization problems. In such cases, the environment problem changes dynamically and therefore, conventional methods are not capable of dealing with such problems. In this paper, a novel multi-swarm cellular particle swarm optimization algorithm is proposed by clustering and local search. In the proposed algorithm, the search space is partitioned into cells, while the particles identify changes in the search space and form clusters to create sub-swarms. Then a local search is applied to improve the solutions in the each cell. Simulation results for static standard benchmarks and dynamic environments show superiority of the proposed method over other alternative approaches.
* 8 pages, 3 figures