 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-aCortex: An Ultra-Compact Energy-Efficient Neurocomputing Platform Based on Commercial 3D-NAND Flash Memories
Aug 07, 2019
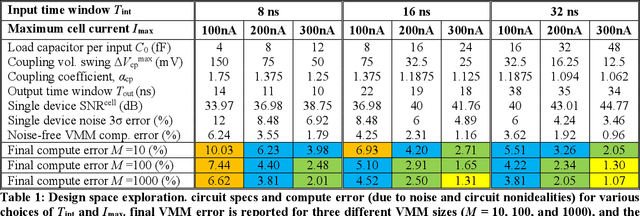

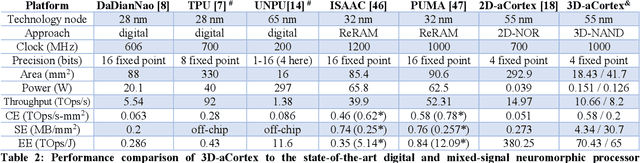
The first contribution of this paper is the development of extremely dense, energy-efficient mixed-signal vector-by-matrix-multiplication (VMM) circuits based on the existing 3D-NAND flash memory blocks, without any need for their modification. Such compatibility is achieved using time-domain-encoded VMM design. Our detailed simulations have shown that, for example, the 5-bit VMM of 200-element vectors, using the commercially available 64-layer gate-all-around macaroni-type 3D-NAND memory blocks designed in the 55-nm technology node, may provide an unprecedented area efficiency of 0.14 um2/byte and energy efficiency of ~10 fJ/Op, including the input/output and other peripheral circuitry overheads. Our second major contribution is the development of 3D-aCortex, a multi-purpose neuromorphic inference processor that utilizes the proposed 3D-VMM blocks as its core processing units. We have performed rigorous performance simulations of such a processor on both circuit and system levels, taking into account non-idealities such as drain-induced barrier lowering, capacitive coupling, charge injection, parasitics, process variations, and noise. Our modeling of the 3D-aCortex performing several state-of-the-art neuromorphic-network benchmarks has shown that it may provide the record-breaking storage efficiency of 4.34 MB/mm2, the peak energy efficiency of 70.43 TOps/J, and the computational throughput up to 10.66 TOps/s. The storage efficiency can be further improved seven-fold by aggressively sharing VMM peripheral circuits at the cost of slight decrease in energy efficiency and throughput.
Improving Noise Tolerance of Mixed-Signal Neural Networks
Apr 02, 2019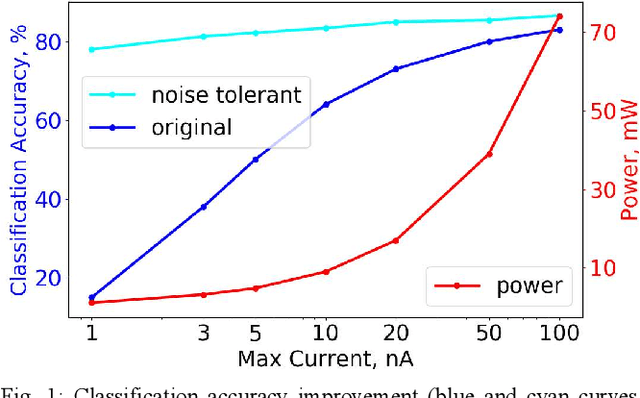
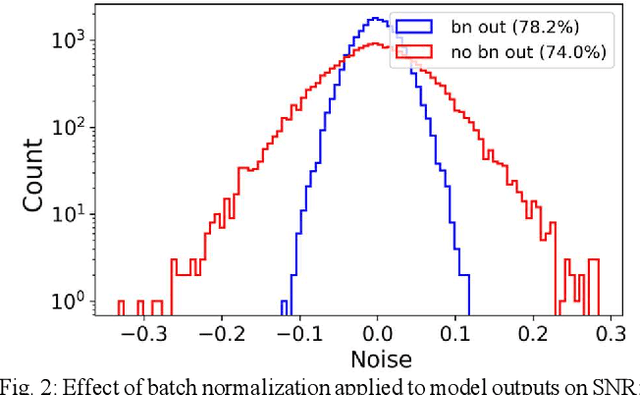
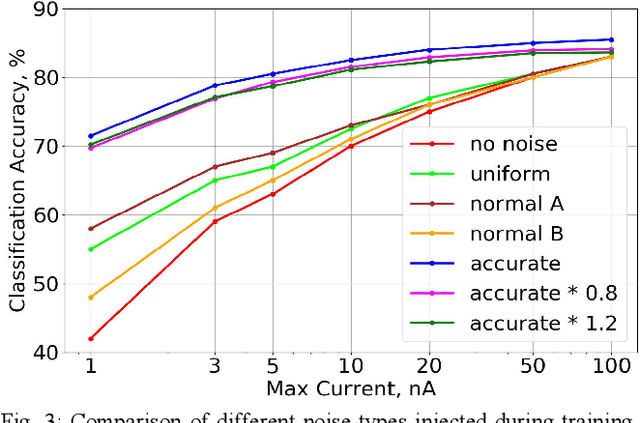
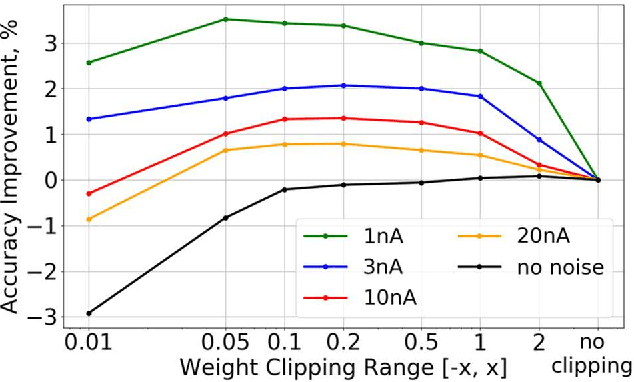
Mixed-signal hardware accelerators for deep learning achieve orders of magnitude better power efficiency than their digital counterparts. In the ultra-low power consumption regime, limited signal precision inherent to analog computation becomes a challenge. We perform a case study of a 6-layer convolutional neural network running on a mixed-signal accelerator and evaluate its sensitivity to hardware specific noise. We apply various methods to improve noise robustness of the network and demonstrate an effective way to optimize useful signal ranges through adaptive signal clipping. The resulting model is robust enough to achieve 80.2% classification accuracy on CIFAR-10 dataset with just 1.4 mW power budget, while 6 mW budget allows us to achieve 87.1% accuracy, which is within 1% of the software baseline. For comparison, the unoptimized version of the same model achieves only 67.7% accuracy at 1.4 mW and 78.6% at 6 mW.
Fast and Efficient Skin Detection for Facial Detection
Jan 19, 2017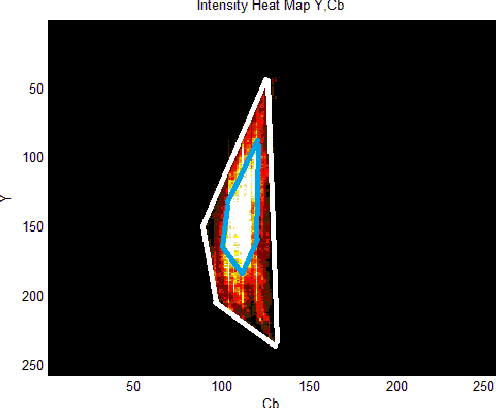
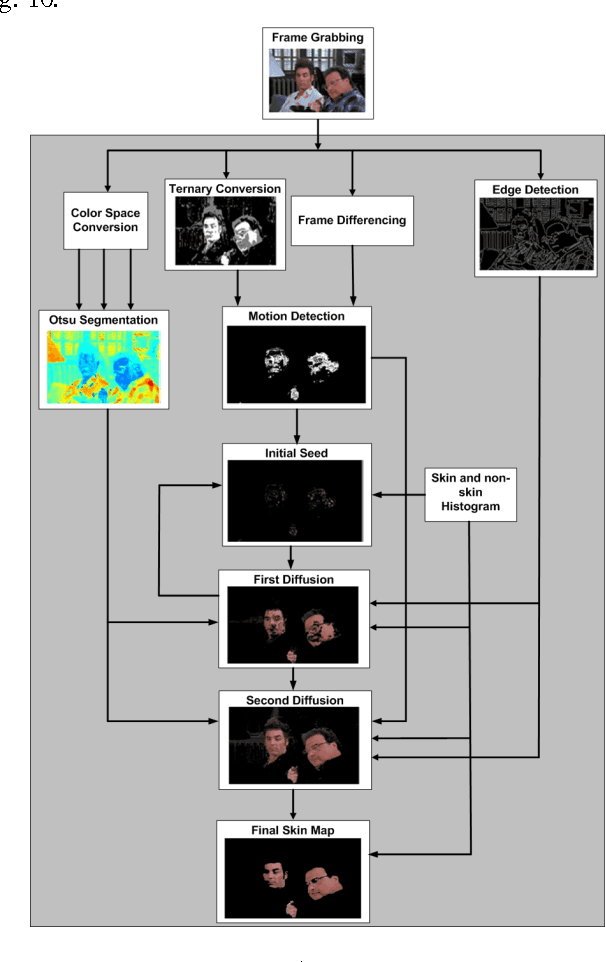


In this paper, an efficient skin detection system is proposed. The algorithm is based on a very fast efficient pre-processing step utilizing the concept of ternary conversion in order to identify candidate windows and subsequently, a novel local two-stage diffusion method which has F-score accuracy of 0.5978 on SDD dataset. The pre-processing step has been proven to be useful to boost the speed of the system by eliminating 82% of an image in average. This is obtained by keeping the true positive rate above 98%. In addition, a novel segmentation algorithm is also designed to process candidate windows which is quantitatively and qualitatively proven to be very efficient in term of accuracy. The algorithm has been implemented in FPGA to obtain real-time processing speed. The system is designed fully pipeline and the inherent parallel structure of the algorithm is fully exploited to maximize the performance. The system is implemented on a Spartan-6 LXT45 Xilinx FPGA and it is capable of processing 98 frames of 640*480 24-bit color images per second.
High Performance Novel Skin Segmentation Algorithm for Images With Complex Background
Jan 19, 2017



Skin Segmentation is widely used in biometric applications such as face detection, face recognition, face tracking, and hand gesture recognition. However, several challenges such as nonlinear illumination, equipment effects, personal interferences, ethnicity variations, etc., are involved in detection process that result in the inefficiency of color based methods. Even though many ideas have already been proposed, the problem has not been satisfactorily solved yet. This paper introduces a technique that addresses some limitations of the previous works. The proposed algorithm consists of three main steps including initial seed generation of skin map, Otsu segmentation in color images, and finally a two-stage diffusion. The initial seed of skin pixels is provided based on the idea of ternary image as there are certain pixels in images which are associated to human complexion with very high probability. The Otsu segmentation is performed on several color channels in order to identify homogeneous regions. The result accompanying with the edge map of the image is utilized in two consecutive diffusion steps in order to annex initially unidentified skin pixels to the seed. Both quantitative and qualitative results demonstrate the effectiveness of the proposed system in compare with the state-of-the-art works.