 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-aCortex: An Ultra-Compact Energy-Efficient Neurocomputing Platform Based on Commercial 3D-NAND Flash Memories
Aug 07, 2019
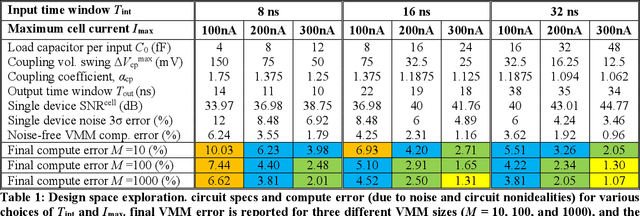

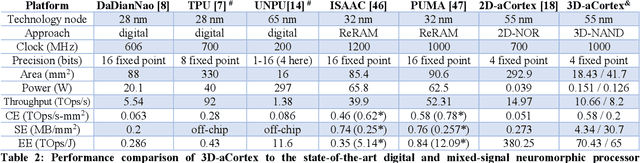
The first contribution of this paper is the development of extremely dense, energy-efficient mixed-signal vector-by-matrix-multiplication (VMM) circuits based on the existing 3D-NAND flash memory blocks, without any need for their modification. Such compatibility is achieved using time-domain-encoded VMM design. Our detailed simulations have shown that, for example, the 5-bit VMM of 200-element vectors, using the commercially available 64-layer gate-all-around macaroni-type 3D-NAND memory blocks designed in the 55-nm technology node, may provide an unprecedented area efficiency of 0.14 um2/byte and energy efficiency of ~10 fJ/Op, including the input/output and other peripheral circuitry overheads. Our second major contribution is the development of 3D-aCortex, a multi-purpose neuromorphic inference processor that utilizes the proposed 3D-VMM blocks as its core processing units. We have performed rigorous performance simulations of such a processor on both circuit and system levels, taking into account non-idealities such as drain-induced barrier lowering, capacitive coupling, charge injection, parasitics, process variations, and noise. Our modeling of the 3D-aCortex performing several state-of-the-art neuromorphic-network benchmarks has shown that it may provide the record-breaking storage efficiency of 4.34 MB/mm2, the peak energy efficiency of 70.43 TOps/J, and the computational throughput up to 10.66 TOps/s. The storage efficiency can be further improved seven-fold by aggressively sharing VMM peripheral circuits at the cost of slight decrease in energy efficiency and throughput.
Biologically Inspired Spiking Neurons : Piecewise Linear Models and Digital Implementation
Dec 16, 2012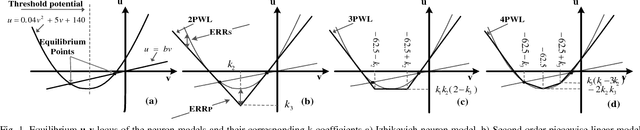
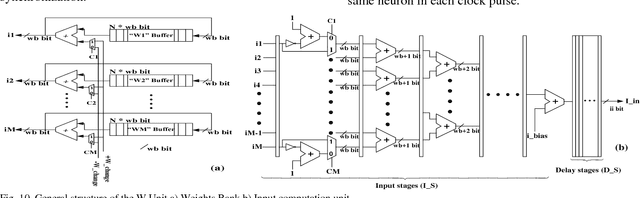

There has been a strong push recently to examine biological scale simulations of neuromorphic algorithms to achieve stronger inference capabilities. This paper presents a set of piecewise linear spiking neuron models, which can reproduce different behaviors, similar to the biological neuron, both for a single neuron as well as a network of neurons. The proposed models are investigated, in terms of digital implementation feasibility and costs, targeting large scale hardware implementation. Hardware synthesis and physical implementations on FPGA show that the proposed models can produce precise neural behaviors with higher performance and considerably lower implementation costs compared with the original model. Accordingly, a compact structure of the models which can be trained with supervised and unsupervised learning algorithms has been developed. Using this structure and based on a spike rate coding, a character recognition case study has been implemented and tested.
* 14 pages, 16 figures