 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Signature Verification using Deep Representation: A new Descriptor
Jun 24, 2018
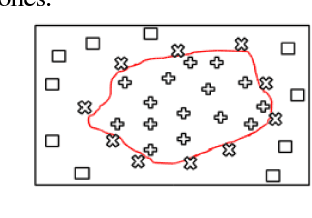
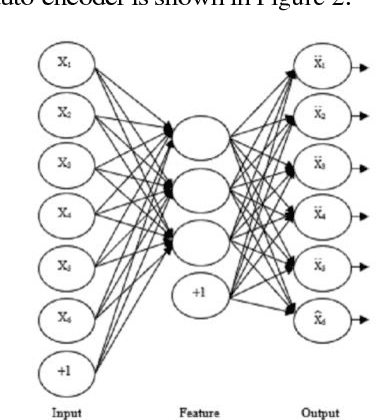
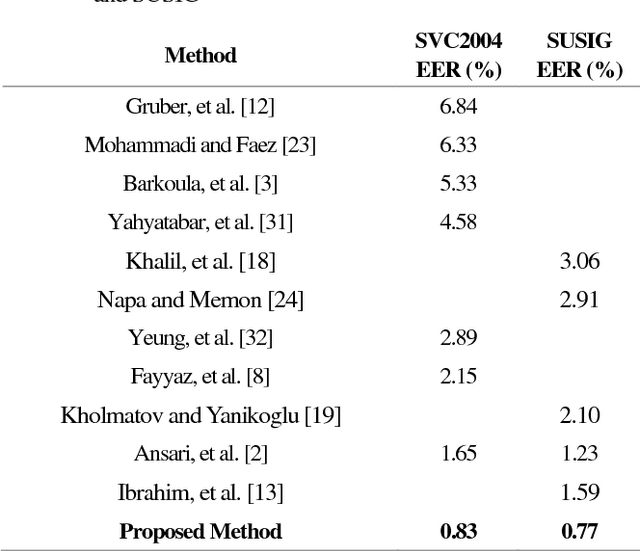
This paper presents an accurate method for verifying online signatures. The main difficulty of signature verification come from: (1) Lacking enough training samples (2) The methods must be spatial change invariant. To deal with these difficulties and modeling the signatures efficiently, we propose a method that a one-class classifier per each user is built on discriminative features. First, we pre-train a sparse auto-encoder using a large number of unlabeled signatures, then we applied the discriminative features, which are learned by auto-encoder to represent the training and testing signatures as a self-thought learning method (i.e. we have introduced a signature descriptor). Finally, user's signatures are modeled and classified using a one-class classifier. The proposed method is independent on signature datasets thanks to self-taught learning. The experimental results indicate significant error reduction and accuracy enhancement in comparison with state-of-the-art methods on SVC2004 and SUSIG datasets.
Semantic Video Segmentation: A Review on Recent Approaches
Jun 16, 2018
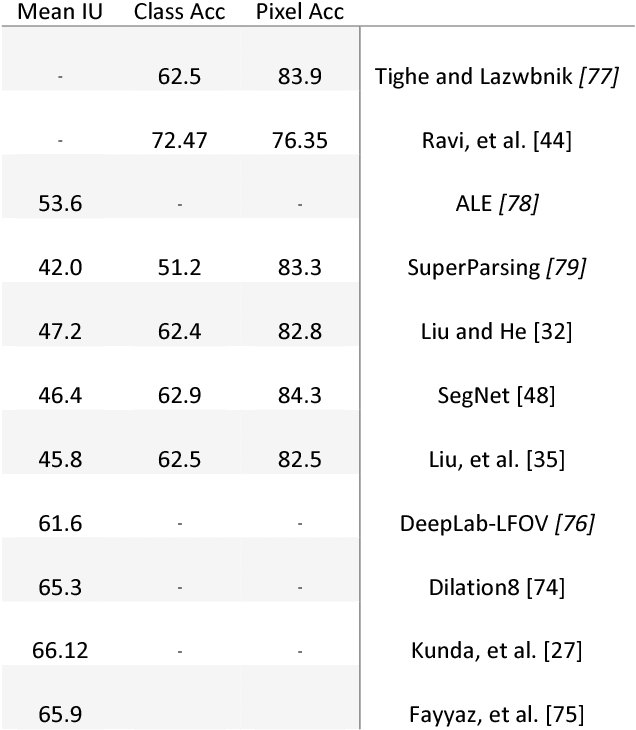

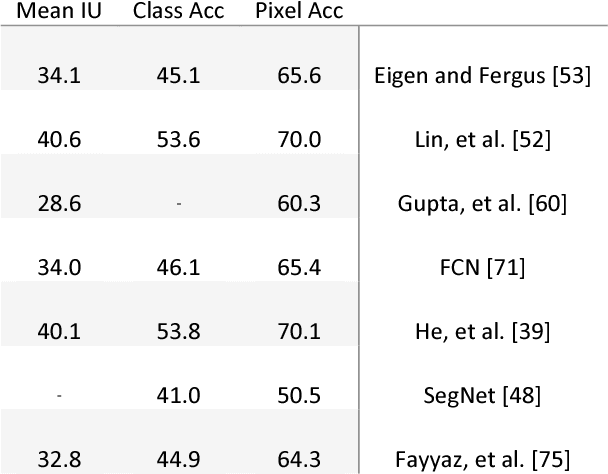
This paper gives an overview on semantic segmentation consists of an explanation of this field, it's status and relation with other vision fundamental tasks, different datasets and common evaluation parameters that have been used by researchers. This survey also includes an overall review on a variety of recent approaches (RDF, MRF, CRF, etc.) and their advantages and challenges and shows the superiority of CNN-based semantic segmentation systems on CamVid and NYUDv2 datasets. In addition, some areas that is ideal for future work have mentioned.
STFCN: Spatio-Temporal FCN for Semantic Video Segmentation
Sep 02, 2016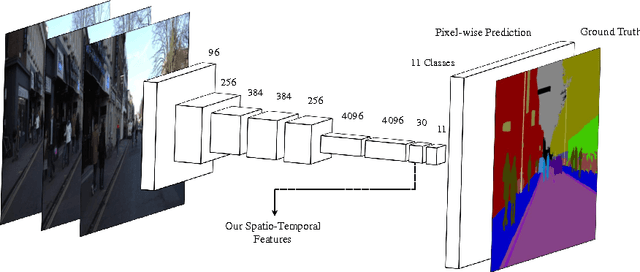

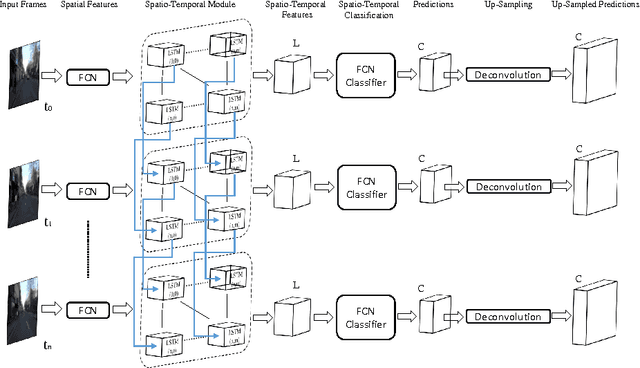

This paper presents a novel method to involve both spatial and temporal features for semantic video segmentation. Current work on convolutional neural networks(CNNs) has shown that CNNs provide advanced spatial features supporting a very good performance of solutions for both image and video analysis, especially for the semantic segmentation task. We investigate how involving temporal features also has a good effect on segmenting video data. We propose a module based on a long short-term memory (LSTM) architecture of a recurrent neural network for interpreting the temporal characteristics of video frames over time. Our system takes as input frames of a video and produces a correspondingly-sized output; for segmenting the video our method combines the use of three components: First, the regional spatial features of frames are extracted using a CNN; then, using LSTM the temporal features are added; finally, by deconvolving the spatio-temporal features we produce pixel-wise predictions. Our key insight is to build spatio-temporal convolutional networks (spatio-temporal CNNs) that have an end-to-end architecture for semantic video segmentation. We adapted fully some known convolutional network architectures (such as FCN-AlexNet and FCN-VGG16), and dilated convolution into our spatio-temporal CNNs. Our spatio-temporal CNNs achieve state-of-the-art semantic segmentation, as demonstrated for the Camvid and NYUDv2 datasets.
A Novel Approach For Finger Vein Verification Based on Self-Taught Learning
Aug 15, 2015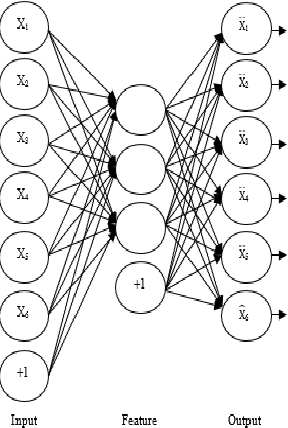
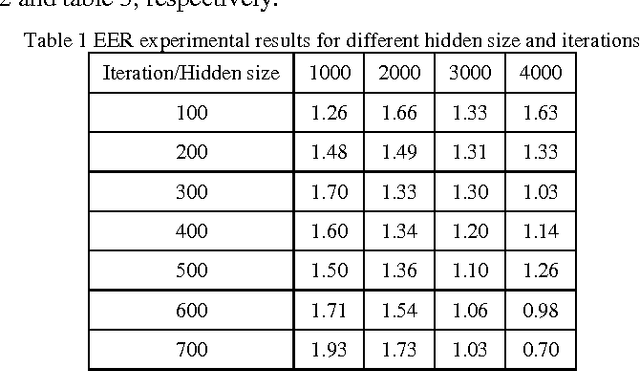
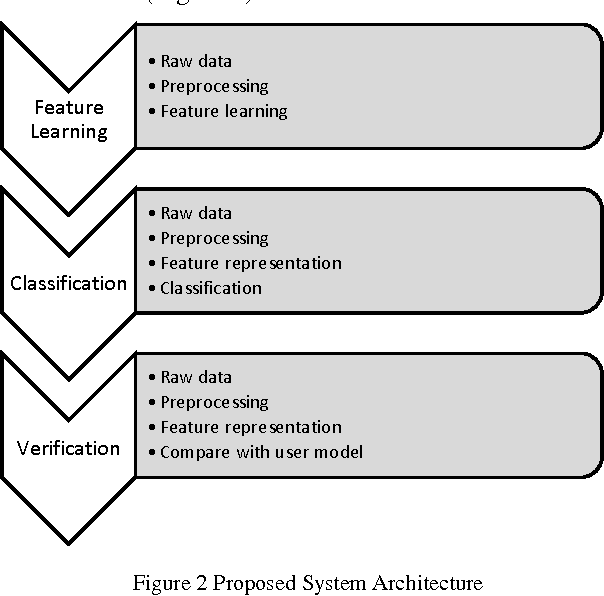
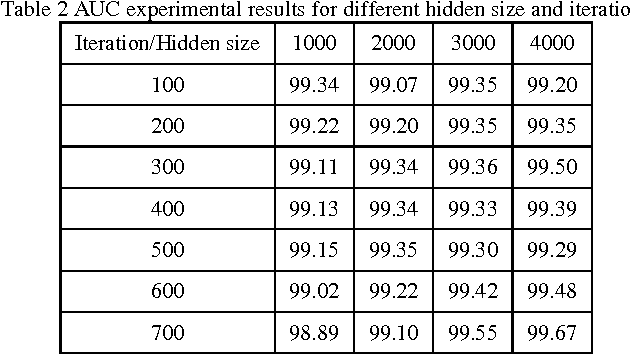
In this paper, we propose a method for user Finger Vein Authentication (FVA) as a biometric system. Using the discriminative features for classifying theses finger veins is one of the main tips that make difference in related works, Thus we propose to learn a set of representative features, based on autoencoders. We model the user finger vein using a Gaussian distribution. Experimental results show that our algorithm perform like a state-of-the-art on SDUMLA-HMT benchmark.