 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of Regulatory Networks Through Temporally Sparse Data
Jul 21, 2022


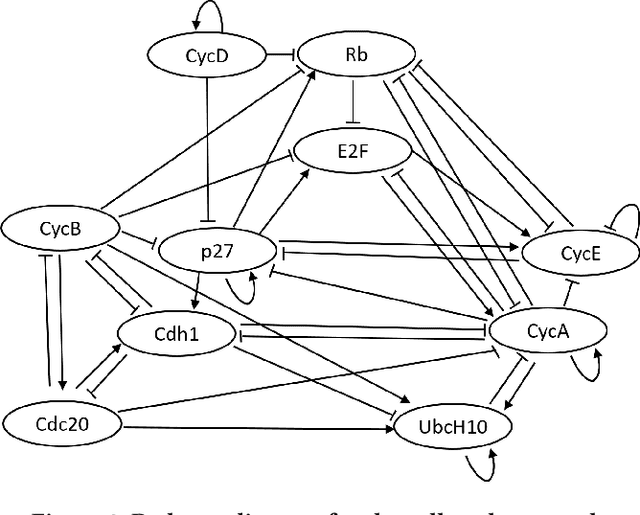
A major goal in genomics is to properly capture the complex dynamical behaviors of gene regulatory networks (GRNs). This includes inferring the complex interactions between genes, which can be used for a wide range of genomics analyses, including diagnosis or prognosis of diseases and finding effective treatments for chronic diseases such as cancer. Boolean networks have emerged as a successful class of models for capturing the behavior of GRNs. In most practical settings, inference of GRNs should be achieved through limited and temporally sparse genomics data. A large number of genes in GRNs leads to a large possible topology candidate space, which often cannot be exhaustively searched due to the limitation in computational resources. This paper develops a scalable and efficient topology inference for GRNs using Bayesian optimization and kernel-based methods. Rather than an exhaustive search over possible topologies, the proposed method constructs a Gaussian Process (GP) with a topology-inspired kernel function to account for correlation in the likelihood function. Then, using the posterior distribution of the GP model, the Bayesian optimization efficiently searches for the topology with the highest likelihood value by optimally balancing between exploration and exploitation. The performance of the proposed method is demonstrated through comprehensive numerical experiments using a well-known mammalian cell-cycle network.
Action Quality Assessment using Transformers
Jul 20, 2022


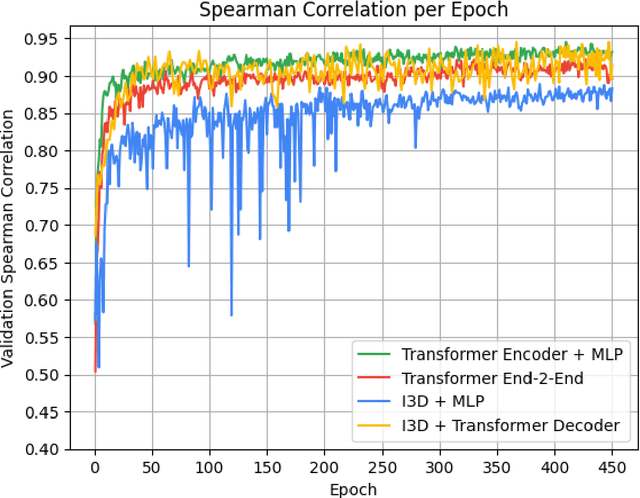
Action quality assessment (AQA) is an active research problem in video-based applications that is a challenging task due to the score variance per frame. Existing methods address this problem via convolutional-based approaches but suffer from its limitation of effectively capturing long-range dependencies. With the recent advancements in Transformers, we show that they are a suitable alternative to the conventional convolutional-based architectures. Specifically, can transformer-based models solve the task of AQA by effectively capturing long-range dependencies, parallelizing computation, and providing a wider receptive field for diving videos? To demonstrate the effectiveness of our proposed architectures, we conducted comprehensive experiments and achieved a competitive Spearman correlation score of 0.9317. Additionally, we explore the hyperparameters effect on the model's performance and pave a new path for exploiting Transformers in AQA.
JUSTICE: A Benchmark Dataset for Supreme Court's Judgment Prediction
Dec 06, 2021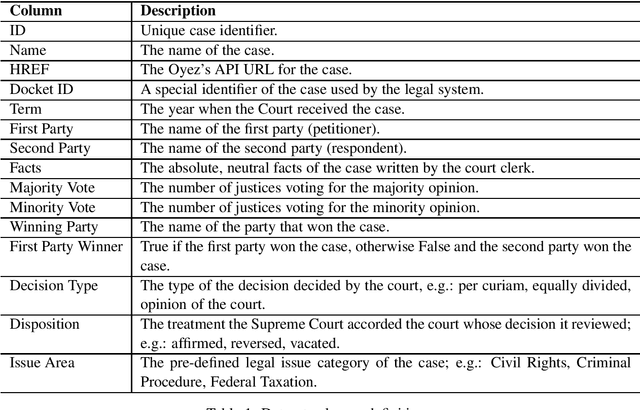



Artificial intelligence is being utilized in many domains as of late, and the legal system is no exception. However, as it stands now, the number of well-annotated datasets pertaining to legal documents from the Supreme Court of the United States (SCOTUS) is very limited for public use. Even though the Supreme Court rulings are public domain knowledge, trying to do meaningful work with them becomes a much greater task due to the need to manually gather and process that data from scratch each time. Hence, our goal is to create a high-quality dataset of SCOTUS court cases so that they may be readily used in natural language processing (NLP) research and other data-driven applications. Additionally, recent advances in NLP provide us with the tools to build predictive models that can be used to reveal patterns that influence court decisions. By using advanced NLP algorithms to analyze previous court cases, the trained models are able to predict and classify a court's judgment given the case's facts from the plaintiff and the defendant in textual format; in other words, the model is emulating a human jury by generating a final verdict.