 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Quality Assessment using Transformers
Paper and Code
Jul 20, 2022


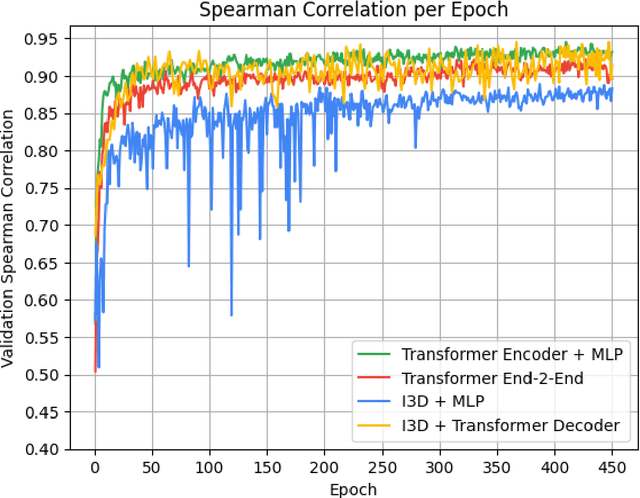
Action quality assessment (AQA) is an active research problem in video-based applications that is a challenging task due to the score variance per frame. Existing methods address this problem via convolutional-based approaches but suffer from its limitation of effectively capturing long-range dependencies. With the recent advancements in Transformers, we show that they are a suitable alternative to the conventional convolutional-based architectures. Specifically, can transformer-based models solve the task of AQA by effectively capturing long-range dependencies, parallelizing computation, and providing a wider receptive field for diving videos? To demonstrate the effectiveness of our proposed architectures, we conducted comprehensive experiments and achieved a competitive Spearman correlation score of 0.9317. Additionally, we explore the hyperparameters effect on the model's performance and pave a new path for exploiting Transformers in AQA.