 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO-Finder: A Registration-Free Wearable System for Assisting Users in Finding Lost Objects via Hand-Held Object Discovery
Feb 12, 2021
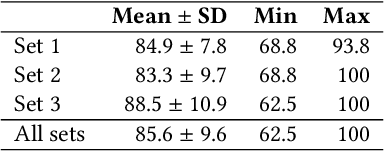

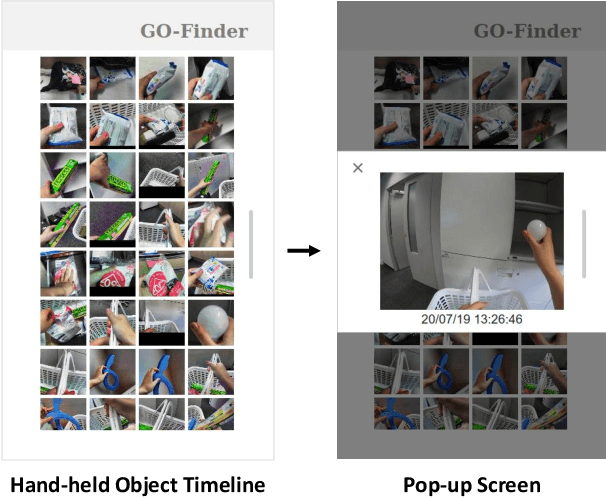
People spend an enormous amount of time and effort looking for lost objects. To help remind people of the location of lost objects, various computational systems that provide information on their locations have been developed. However, prior systems for assisting people in finding objects require users to register the target objects in advance. This requirement imposes a cumbersome burden on the users, and the system cannot help remind them of unexpectedly lost objects. We propose GO-Finder ("Generic Object Finder"), a registration-free wearable camera based system for assisting people in finding an arbitrary number of objects based on two key features: automatic discovery of hand-held objects and image-based candidate selection. Given a video taken from a wearable camera, Go-Finder automatically detects and groups hand-held objects to form a visual timeline of the objects. Users can retrieve the last appearance of the object by browsing the timeline through a smartphone app. We conducted a user study to investigate how users benefit from using GO-Finder and confirmed improved accuracy and reduced mental load regarding the object search task by providing clear visual cues on object locations.
Uncovering Why Deep Neural Networks Lack Robustness: Representation Metrics that Link to Adversarial Attacks
Jun 20, 2019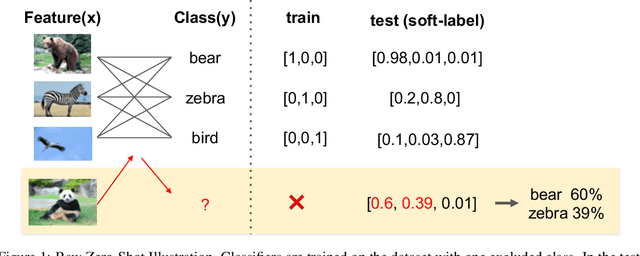

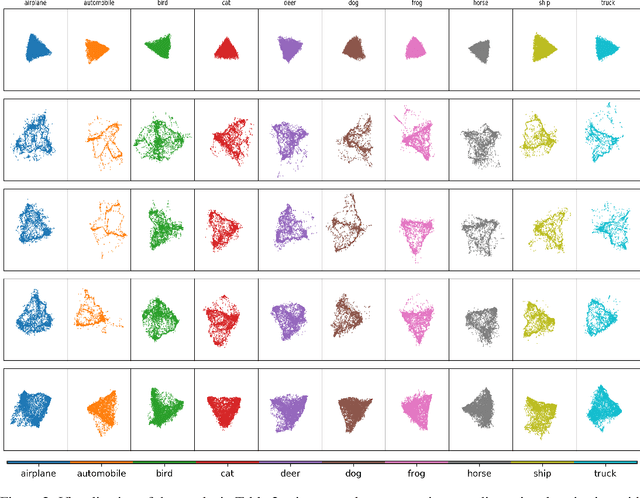
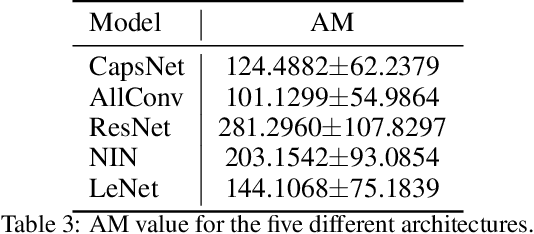
Neural networks have been shown vulnerable to adversarial samples. Slightly perturbed input images are able to change the classification of accurate models, showing that the representation learned is not as good as previously thought. To aid the development of better neural networks, it would be important to evaluate to what extent are current neural networks' representations capturing the existing features. Here we propose a test that can evaluate neural networks using a new type of zero-shot test, entitled Raw Zero-Shot. This test is based on the principle that some features are present on unknown classes and that unknown classes can be defined as a combination of previous learned features without learning bias. To evaluate the soft-labels of unknown classes, two metrics are proposed. One is based on clustering validation techniques (Davies-Bouldin Index) and the other is based on soft-label distance of a given correct soft-label. Experiments show that such metrics are in accordance with the robustness to adversarial attacks and might serve as a guidance to build better models as well as be used in loss functions to improve the models directly. Interestingly, the results suggests that dynamic routing networks such as CapsNet have better representation while some DNNs might be trading off representation quality for accuracy. Code available at http://bit.ly/RepresentationMetrics.