 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Perceptual Enhancement for Medical Image Analysis
Mar 11, 2025Due to numerous hardware shortcomings, medical image acquisition devices are susceptible to producing low-quality (i.e., low contrast, inappropriate brightness, noisy, etc.) images. Regrettably, perceptually degraded images directly impact the diagnosis process and make the decision-making manoeuvre of medical practitioners notably complicated. This study proposes to enhance such low-quality images by incorporating end-to-end learning strategies for accelerating medical image analysis tasks. To the best concern, this is the first work in medical imaging which comprehensively tackles perceptual enhancement, including contrast correction, luminance correction, denoising, etc., with a fully convolutional deep network. The proposed network leverages residual blocks and a residual gating mechanism for diminishing visual artefacts and is guided by a multi-term objective function to perceive the perceptually plausible enhanced images. The practicability of the deep medical image enhancement method has been extensively investigated with sophisticated experiments. The experimental outcomes illustrate that the proposed method could outperform the existing enhancement methods for different medical image modalities by 5.00 to 7.00 dB in peak signal-to-noise ratio (PSNR) metrics and 4.00 to 6.00 in DeltaE metrics. Additionally, the proposed method can drastically improve the medical image analysis tasks' performance and reveal the potentiality of such an enhancement method in real-world applications. Code Available: https://github.com/sharif-apu/DPE_JBHI
DarkDeblur: Learning single-shot image deblurring in low-light condition
Mar 04, 2025

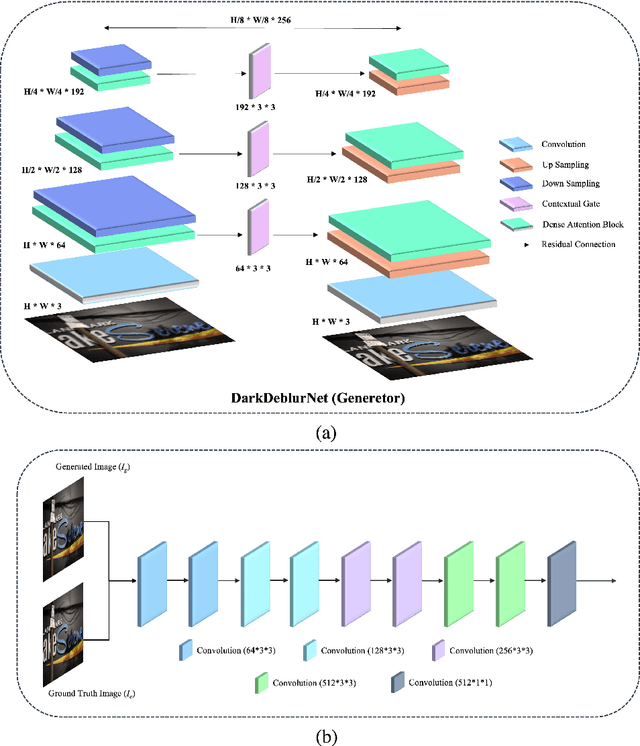
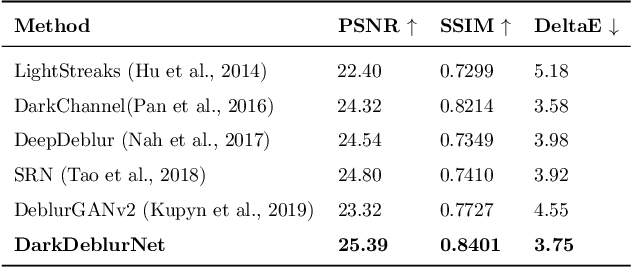
Single-shot image deblurring in a low-light condition is known to be a profoundly challenging image translation task. This study tackles the limitations of the low-light image deblurring with a learning-based approach and proposes a novel deep network named as DarkDeblurNet. The proposed DarkDeblur- Net comprises a dense-attention block and a contextual gating mechanism in a feature pyramid structure to leverage content awareness. The model additionally incorporates a multi-term objective function to perceive a plausible perceptual image quality while performing image deblurring in the low-light settings. The practicability of the proposed model has been verified by fusing it in numerous computer vision applications. Apart from that, this study introduces a benchmark dataset collected with actual hardware to assess the low-light image deblurring methods in a real-world setup. The experimental results illustrate that the proposed method can outperform the state-of-the-art methods in both synthesized and real-world data for single-shot image deblurring, even in challenging lighting environment.
SAGAN: Adversarial Spatial-asymmetric Attention for Noisy Nona-Bayer Reconstruction
Oct 19, 2021



Nona-Bayer colour filter array (CFA) pattern is considered one of the most viable alternatives to traditional Bayer patterns. Despite the substantial advantages, such non-Bayer CFA patterns are susceptible to produce visual artefacts while reconstructing RGB images from noisy sensor data. This study addresses the challenges of learning RGB image reconstruction from noisy Nona-Bayer CFA comprehensively. We propose a novel spatial-asymmetric attention module to jointly learn bi-direction transformation and large-kernel global attention to reduce the visual artefacts. We combine our proposed module with adversarial learning to produce plausible images from Nona-Bayer CFA. The feasibility of the proposed method has been verified and compared with the state-of-the-art image reconstruction method. The experiments reveal that the proposed method can reconstruct RGB images from noisy Nona-Bayer CFA without producing any visually disturbing artefacts. Also, it can outperform the state-of-the-art image reconstruction method in both qualitative and quantitative comparison. Code available: https://github.com/sharif-apu/SAGAN_BMVC21.
Beyond Joint Demosaicking and Denoising: An Image Processing Pipeline for a Pixel-bin Image Sensor
Apr 19, 2021

Pixel binning is considered one of the most prominent solutions to tackle the hardware limitation of smartphone cameras. Despite numerous advantages, such an image sensor has to appropriate an artefact-prone non-Bayer colour filter array (CFA) to enable the binning capability. Contrarily, performing essential image signal processing (ISP) tasks like demosaicking and denoising, explicitly with such CFA patterns, makes the reconstruction process notably complicated. In this paper, we tackle the challenges of joint demosaicing and denoising (JDD) on such an image sensor by introducing a novel learning-based method. The proposed method leverages the depth and spatial attention in a deep network. The proposed network is guided by a multi-term objective function, including two novel perceptual losses to produce visually plausible images. On top of that, we stretch the proposed image processing pipeline to comprehensively reconstruct and enhance the images captured with a smartphone camera, which uses pixel binning techniques. The experimental results illustrate that the proposed method can outperform the existing methods by a noticeable margin in qualitative and quantitative comparisons. Code available: https://github.com/sharif-apu/BJDD_CVPR21.
A Two-stage Deep Network for High Dynamic Range Image Reconstruction
Apr 19, 2021
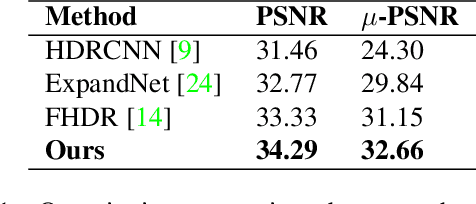


Mapping a single exposure low dynamic range (LDR) image into a high dynamic range (HDR) is considered among the most strenuous image to image translation tasks due to exposure-related missing information. This study tackles the challenges of single-shot LDR to HDR mapping by proposing a novel two-stage deep network. Notably, our proposed method aims to reconstruct an HDR image without knowing hardware information, including camera response function (CRF) and exposure settings. Therefore, we aim to perform image enhancement task like denoising, exposure correction, etc., in the first stage. Additionally, the second stage of our deep network learns tone mapping and bit-expansion from a convex set of data samples. The qualitative and quantitative comparisons demonstrate that the proposed method can outperform the existing LDR to HDR works with a marginal difference. Apart from that, we collected an LDR image dataset incorporating different camera systems. The evaluation with our collected real-world LDR images illustrates that the proposed method can reconstruct plausible HDR images without presenting any visual artefacts. Code available: https://github. com/sharif-apu/twostageHDR_NTIRE21.
BanglaLekha-Isolated: A Comprehensive Bangla Handwritten Character Dataset
Feb 22, 2017


Bangla handwriting recognition is becoming a very important issue nowadays. It is potentially a very important task specially for Bangla speaking population of Bangladesh and West Bengal. By keeping that in our mind we are introducing a comprehensive Bangla handwritten character dataset named BanglaLekha-Isolated. This dataset contains Bangla handwritten numerals, basic characters and compound characters. This dataset was collected from multiple geographical location within Bangladesh and includes sample collected from a variety of aged groups. This dataset can also be used for other classification problems i.e: gender, age, district. This is the largest dataset on Bangla handwritten characters yet.