 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpeditious Saliency-guided Mix-up through Random Gradient Thresholding
Dec 17, 2022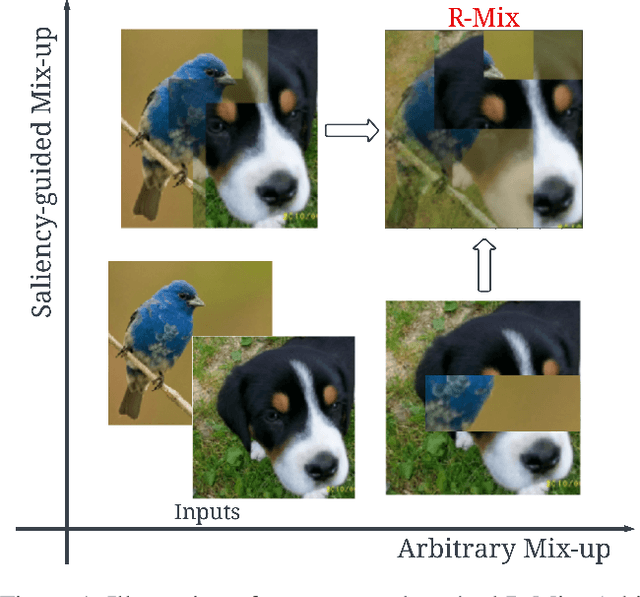



Mix-up training approaches have proven to be effective in improving the generalization ability of Deep Neural Networks. Over the years, the research community expands mix-up methods into two directions, with extensive efforts to improve saliency-guided procedures but minimal focus on the arbitrary path, leaving the randomization domain unexplored. In this paper, inspired by the superior qualities of each direction over one another, we introduce a novel method that lies at the junction of the two routes. By combining the best elements of randomness and saliency utilization, our method balances speed, simplicity, and accuracy. We name our method R-Mix following the concept of "Random Mix-up". We demonstrate its effectiveness in generalization, weakly supervised object localization, calibration, and robustness to adversarial attacks. Finally, in order to address the question of whether there exists a better decision protocol, we train a Reinforcement Learning agent that decides the mix-up policies based on the classifier's performance, reducing dependency on human-designed objectives and hyperparameter tuning. Extensive experiments further show that the agent is capable of performing at the cutting-edge level, laying the foundation for a fully automatic mix-up. Our code is released at [https://github.com/minhlong94/Random-Mixup].