 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Embodiment Robotic Manipulation Synthesis via Guided Demonstrations through CycleVAE and Human Behavior Transformer
Mar 11, 2025Cross-embodiment robotic manipulation synthesis for complicated tasks is challenging, partially due to the scarcity of paired cross-embodiment datasets and the impediment of designing intricate controllers. Inspired by robotic learning via guided human expert demonstration, we here propose a novel cross-embodiment robotic manipulation algorithm via CycleVAE and human behavior transformer. First, we utilize unsupervised CycleVAE together with a bidirectional subspace alignment algorithm to align latent motion sequences between cross-embodiments. Second, we propose a casual human behavior transformer design to learn the intrinsic motion dynamics of human expert demonstrations. During the test case, we leverage the proposed transformer for the human expert demonstration generation, which will be aligned using CycleVAE for the final human-robotic manipulation synthesis. We validated our proposed algorithm through extensive experiments using a dexterous robotic manipulator with the robotic hand. Our results successfully generate smooth trajectories across intricate tasks, outperforming prior learning-based robotic motion planning algorithms. These results have implications for performing unsupervised cross-embodiment alignment and future autonomous robotics design. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/humanrobots/home.
APEX: Ambidextrous Dual-Arm Robotic Manipulation Using Collision-Free Generative Diffusion Models
Apr 02, 2024



Dexterous manipulation, particularly adept coordinating and grasping, constitutes a fundamental and indispensable capability for robots, facilitating the emulation of human-like behaviors. Integrating this capability into robots empowers them to supplement and even supplant humans in undertaking increasingly intricate tasks in both daily life and industrial settings. Unfortunately, contemporary methodologies encounter serious challenges in devising manipulation trajectories owing to the intricacies of tasks, the expansive robotic manipulation space, and dynamic obstacles. We propose a novel approach, APEX, to address all these difficulties by introducing a collision-free latent diffusion model for both robotic motion planning and manipulation. Firstly, we simplify the complexity of real-life ambidextrous dual-arm robotic manipulation tasks by abstracting them as aligning two vectors. Secondly, we devise latent diffusion models to produce a variety of robotic manipulation trajectories. Furthermore, we integrate obstacle information utilizing a classifier-guidance technique, thereby guaranteeing both the feasibility and safety of the generated manipulation trajectories. Lastly, we validate our proposed algorithm through extensive experiments conducted on the hardware platform of ambidextrous dual-arm robots. Our algorithm consistently generates successful and seamless trajectories across diverse tasks, surpassing conventional robotic motion planning algorithms. These results carry significant implications for the future design of diffusion robots, enhancing their capability to tackle more intricate robotic manipulation tasks with increased efficiency and safety. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/apex-dual-arm/home.
FPGA-QHAR: Throughput-Optimized for Quantized Human Action Recognition on The Edge
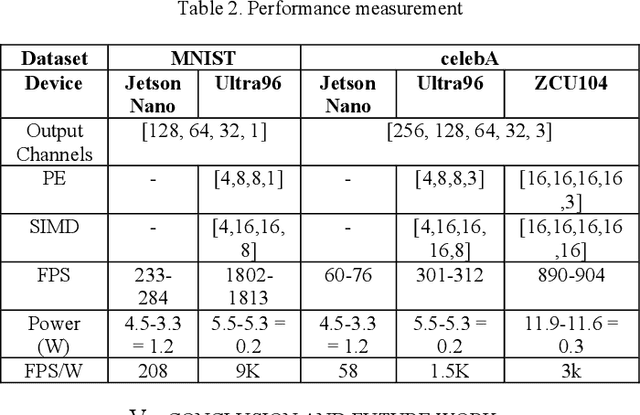
Nov 04, 2023Accelerating Human Action Recognition (HAR) efficiently for real-time surveillance and robotic systems on edge chips remains a challenging research field, given its high computational and memory requirements. This paper proposed an integrated end-to-end HAR scalable HW/SW accelerator co-design based on an enhanced 8-bit quantized Two-Stream SimpleNet-PyTorch CNN architecture. Our network accelerator was trained on UCF101 and UCF24 datasets and implemented on edge SoC-FPGA. Our development uses partially streaming dataflow architecture to achieve higher throughput versus network design and resource utilization trade-off. We also fused all convolutional, batch-norm, and ReLU operations into a single homogeneous layer and utilized the Lucas-Kanade motion flow method to enable a high parallelism accelerator design and optimized on-chip engine computing.Furthermore, our proposed methodology achieved nearly 81% prediction accuracy with an approximately 24 FPS real-time inference throughput at 187MHz on ZCU104, which is 1.7x - 1.9x higher than the prior research. Lastly, the designed framework was benchmarked against several hardware chips for higher throughput and performance measurements and is now available as an open-source project on GitHub for training and implementation on edge platforms.
RETRO: Reactive Trajectory Optimization for Real-Time Robot Motion Planning in Dynamic Environments
Oct 03, 2023Reactive trajectory optimization for robotics presents formidable challenges, demanding the rapid generation of purposeful robot motion in complex and swiftly changing dynamic environments. While much existing research predominantly addresses robotic motion planning with predefined objectives, emerging problems in robotic trajectory optimization frequently involve dynamically evolving objectives and stochastic motion dynamics. However, effectively addressing such reactive trajectory optimization challenges for robot manipulators proves difficult due to inefficient, high-dimensional trajectory representations and a lack of consideration for time optimization. In response, we introduce a novel trajectory optimization framework called RETRO. RETRO employs adaptive optimization techniques that span both spatial and temporal dimensions. As a result, it achieves a remarkable computing complexity of $O(T^{2.4}) + O(Tn^{2})$, a significant improvement over the traditional application of DDP, which leads to a complexity of $O(n^{4})$ when reasonable time step sizes are used. To evaluate RETRO's performance in terms of error, we conducted a comprehensive analysis of its regret bounds, comparing it to an Oracle value function obtained through an Oracle trajectory optimization algorithm. Our analytical findings demonstrate that RETRO's total regret can be upper-bounded by a function of the chosen time step size. Moreover, our approach delivers smoothly optimized robot trajectories within the joint space, offering flexibility and adaptability for various tasks. It can seamlessly integrate task-specific requirements such as collision avoidance while maintaining real-time control rates. We validate the effectiveness of our framework through extensive simulations and real-world robot experiments in closed-loop manipulation scenarios.
Intercepting A Flying Target While Avoiding Moving Obstacles: A Unified Control Framework With Deep Manifold Learning
Sep 27, 2022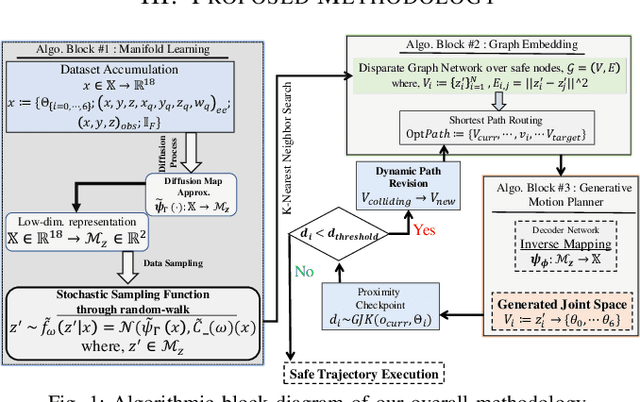
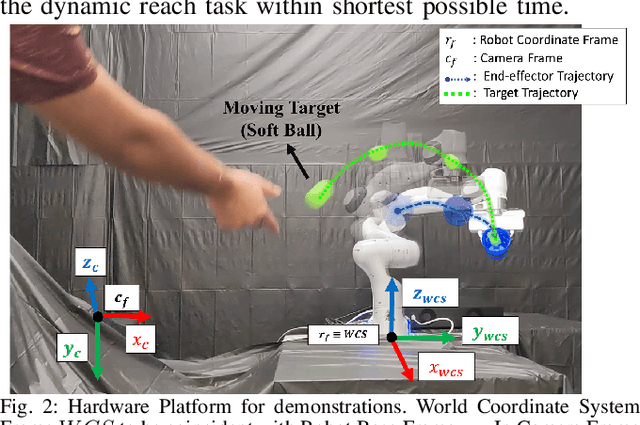
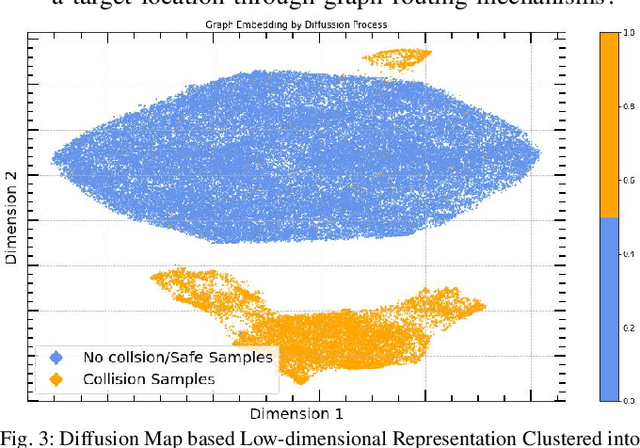
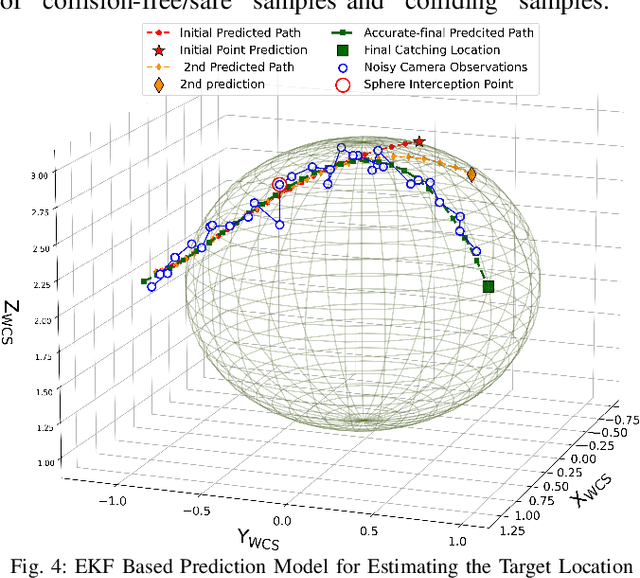
Real-time interception of a fast-moving object by a robotic arm in cluttered environments filled with static or dynamic obstacles permits only tens of milliseconds for reaction times, hence quite challenging and arduous for state-of-the-art robotic planning algorithms to perform multiple robotic skills, for instance, catching the dynamic object and avoiding obstacles, in parallel. This paper proposes an unified framework of robotic path planning through embedding the high-dimensional temporal information contained in the event stream to distinguish between safe and colliding trajectories into a low-dimension space manifested with a pre-constructed 2D densely connected graph. We then leverage a fast graph-traversing strategy to generate the motor commands necessary to effectively avoid the approaching obstacles while simultaneously intercepting a fast-moving objects. The most distinctive feature of our methodology is to conduct both object interception and obstacle avoidance within the same algorithm framework based on deep manifold learning. By leveraging a highly efficient diffusion-map based variational autoencoding and Extended Kalman Filter(EKF), we demonstrate the effectiveness of our approach on an autonomous 7-DoF robotic arm using only onboard sensing and computation. Our robotic manipulator was capable of avoiding multiple obstacles of different sizes and shapes while successfully capturing a fast-moving soft ball thrown by hand at normal speed in different angles. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/multirobotskill/home.
Non-Parametric Stochastic Policy Gradient with Strategic Retreat for Non-Stationary Environment
Mar 24, 2022



In modern robotics, effectively computing optimal control policies under dynamically varying environments poses substantial challenges to the off-the-shelf parametric policy gradient methods, such as the Deep Deterministic Policy Gradient (DDPG) and Twin Delayed Deep Deterministic policy gradient (TD3). In this paper, we propose a systematic methodology to dynamically learn a sequence of optimal control policies non-parametrically, while autonomously adapting with the constantly changing environment dynamics. Specifically, our non-parametric kernel-based methodology embeds a policy distribution as the features in a non-decreasing Euclidean space, therefore allowing its search space to be defined as a very high (possible infinite) dimensional RKHS (Reproducing Kernel Hilbert Space). Moreover, by leveraging the similarity metric computed in RKHS, we augmented our non-parametric learning with the technique of AdaptiveH- adaptively selecting a time-frame window of finishing the optimal part of whole action-sequence sampled on some preceding observed state. To validate our proposed approach, we conducted extensive experiments with multiple classic benchmarks and one simulated robotics benchmark equipped with dynamically changing environments. Overall, our methodology has outperformed the well-established DDPG and TD3 methodology by a sizeable margin in terms of learning performance.
Reactive Whole-Body Obstacle Avoidance for Collision-Free Human-Robot Interaction with Topological Manifold Learning
Mar 24, 2022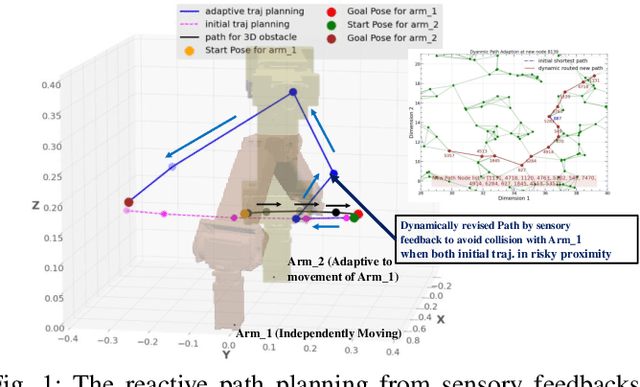

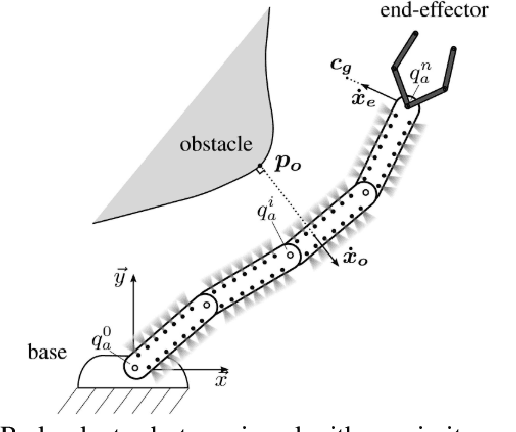

Safe collaboration between human and robots in a common unstructured environment becomes increasingly critical with the emergence of Industry 4.0. However, to accomplish safe, robust, and autonomous collaboration with humans, modern robotic systems must possess not only effective proximity perception but also reactive obstacle avoidance. Unfortunately, for most robotic systems, their shared working environment with human operators may not always be static, instead often dynamically varying and being constantly cluttered with unanticipated obstacles or hazards. In this paper, we present a novel methodology of reactive whole-body obstacle avoidance methodology that safeguards the human who enters the robot's workspace through achieving conflict-free human-robot interactions even in a dynamically constrained environment. Unlike existing Jacobian-type or geometric approaches, our proposed methodology leverages both topological manifold learning and latest deep learning advances, therefore can not only be readily generalized into other unseen problem settings, but also achieve high computing efficiency with concrete theoretical basis. Furthermore, in sharp contrast to the industrial cobot setting, our methodology allows a robotic arm to proactively avoid obstacles of arbitrary 3D shapes without direct contacting. To solidify our study, we implement and validate our methodology with a robotic platform consisting of dual 6-DoF robotic arms with optimized proximity sensor placement, both of which are capable of working collaboratively with different levels of interference. Specifically, one arm will perform reactive whole-body obstacle avoidance while achieving its pre-determined objective, with the other arm emulating the presence of a human collaborator with independent and potentially adversary movements.
Dynamically Avoiding Amorphous Obstacles with Topological Manifold Learning and Deep Autoencoding
Mar 24, 2022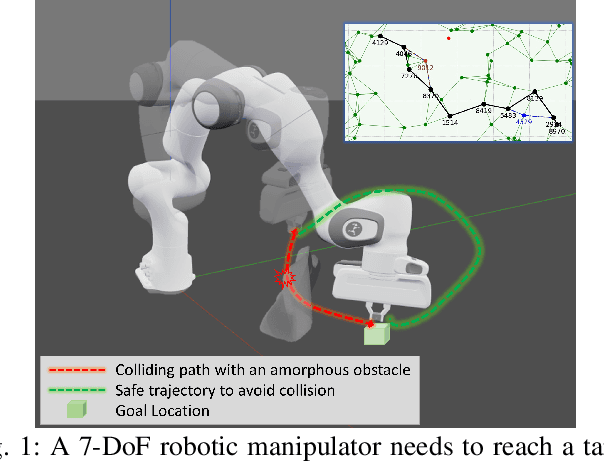
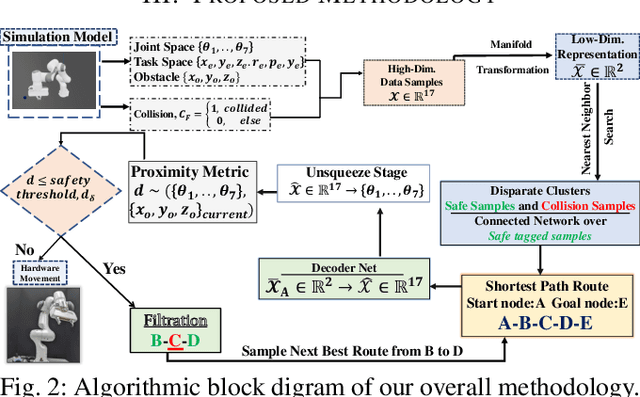

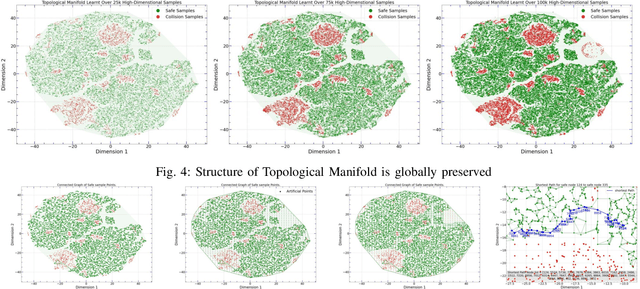
To achieve conflict-free human-machine collaborations, robotic agents need to skillfully avoid continuously moving obstacles while achieving collective objectives. Sometimes, these obstacles can even change their 3D shapes and forms simultaneously, hence being "amorphous". To this end, this paper formulates the problem of Dynamic Amorphous Obstacle Avoidance (DAO-A), where a robotic arm can dexterously avoid dynamically generated obstacles that constantly change their trajectories and their 3D forms. Specifically, we introduce a novel control strategy for robotic arms that leverages both topological manifold learning and latest deep learning advancements. We test our learning framework, using a 7-DoF robotic manipulator, in both simulation and physical experiments, where the robot satisfactorily learns and synthesizes realistic skills avoiding previously-unseen obstacles, while generating novel movements to achieve predefined motion objectives. Most notably, our learned methodology, once finalized, for a given robotic manipulator, can avoid any number of 3D obstacles with arbitrary and unseen moving trajectories, therefore it is universal, versatile, and completely reusable. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/daoa/home.
Hardware-Efficient Deconvolution-Based GAN for Edge Computing
Jan 18, 2022


Generative Adversarial Networks (GAN) are cutting-edge algorithms for generating new data samples based on the learned data distribution. However, its performance comes at a significant cost in terms of computation and memory requirements. In this paper, we proposed an HW/SW co-design approach for training quantized deconvolution GAN (QDCGAN) implemented on FPGA using a scalable streaming dataflow architecture capable of achieving higher throughput versus resource utilization trade-off. The developed accelerator is based on an efficient deconvolution engine that offers high parallelism with respect to scaling factors for GAN-based edge computing. Furthermore, various precisions, datasets, and network scalability were analyzed for low-power inference on resource-constrained platforms. Lastly, an end-to-end open-source framework is provided for training, implementation, state-space exploration, and scaling the inference using Vivado high-level synthesis for Xilinx SoC-FPGAs, and a comparison testbed with Jetson Nano.
Survivable Robotic Control through Guided Bayesian Policy Search with Deep Reinforcement Learning
Jun 29, 2021
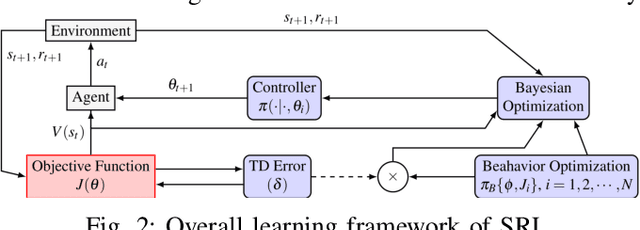
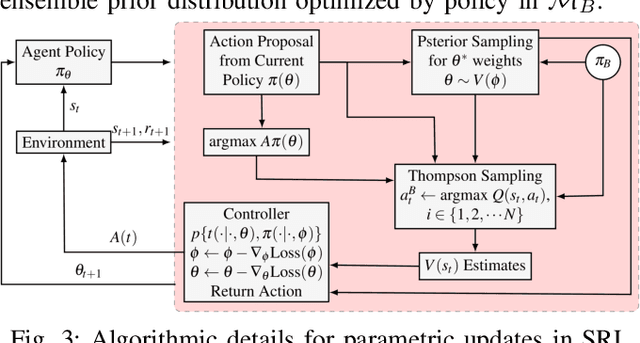

Many robot manipulation skills can be represented with deterministic characteristics and there exist efficient techniques for learning parameterized motor plans for those skills. However, one of the active research challenge still remains to sustain manipulation capabilities in situation of a mechanical failure. Ideally, like biological creatures, a robotic agent should be able to reconfigure its control policy by adapting to dynamic adversaries. In this paper, we propose a method that allows an agent to survive in a situation of mechanical loss, and adaptively learn manipulation with compromised degrees of freedom -- we call our method Survivable Robotic Learning (SRL). Our key idea is to leverage Bayesian policy gradient by encoding knowledge bias in posterior estimation, which in turn alleviates future policy search explorations, in terms of sample efficiency and when compared to random exploration based policy search methods. SRL represents policy priors as Gaussian process, which allows tractable computation of approximate posterior (when true gradient is intractable), by incorporating guided bias as proxy from prior replays. We evaluate our proposed method against off-the-shelf model free learning algorithm (DDPG), testing on a hexapod robot platform which encounters incremental failure emulation, and our experiments show that our method improves largely in terms of sample requirement and quantitative success ratio in all failure modes. A demonstration video of our experiments can be viewed at: https://sites.google.com/view/survivalrl