 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-QHAR: Throughput-Optimized for Quantized Human Action Recognition on The Edge
Nov 04, 2023Accelerating Human Action Recognition (HAR) efficiently for real-time surveillance and robotic systems on edge chips remains a challenging research field, given its high computational and memory requirements. This paper proposed an integrated end-to-end HAR scalable HW/SW accelerator co-design based on an enhanced 8-bit quantized Two-Stream SimpleNet-PyTorch CNN architecture. Our network accelerator was trained on UCF101 and UCF24 datasets and implemented on edge SoC-FPGA. Our development uses partially streaming dataflow architecture to achieve higher throughput versus network design and resource utilization trade-off. We also fused all convolutional, batch-norm, and ReLU operations into a single homogeneous layer and utilized the Lucas-Kanade motion flow method to enable a high parallelism accelerator design and optimized on-chip engine computing.Furthermore, our proposed methodology achieved nearly 81% prediction accuracy with an approximately 24 FPS real-time inference throughput at 187MHz on ZCU104, which is 1.7x - 1.9x higher than the prior research. Lastly, the designed framework was benchmarked against several hardware chips for higher throughput and performance measurements and is now available as an open-source project on GitHub for training and implementation on edge platforms.
Hardware-Efficient Template-Based Deep CNNs Accelerator Design
Jul 21, 2022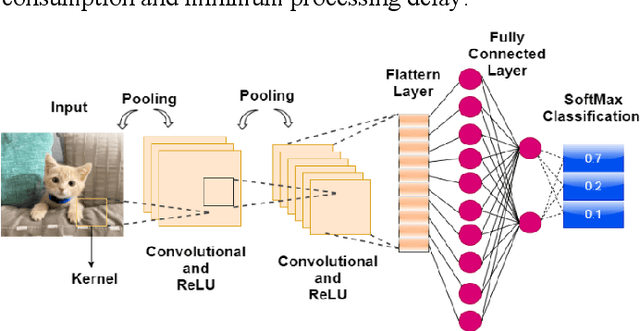

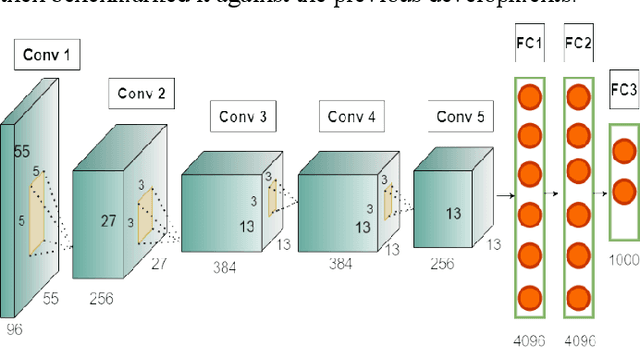
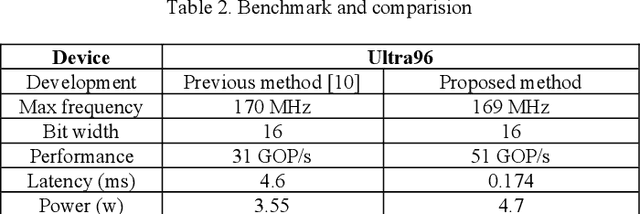
Acceleration of Convolutional Neural Network (CNN) on edge devices has recently achieved a remarkable performance in image classification and object detection applications. This paper proposes an efficient and scalable CNN-based SoC-FPGA accelerator design that takes pre-trained weights with a 16-bit fixed-point quantization and target hardware specification to generate an optimized template capable of achieving higher performance versus resource utilization trade-off. The template analyzed the computational workload, data dependency, and external memory bandwidth and utilized loop tiling transformation along with dataflow modeling to convert convolutional and fully connected layers into vector multiplication between input and output feature maps, which resulted in a single compute unit on-chip. Furthermore, the accelerator was examined among AlexNet, VGG16, and LeNet networks and ran at 200-MHz with a peak performance of 230 GOP/s depending on ZYNQ boards and state-space exploration of different compute unit configurations during simulation and synthesis. Lastly, our proposed methodology was benchmarked against the previous development on Ultra96 for higher performance measurement.
Hardware-Efficient Deconvolution-Based GAN for Edge Computing
Jan 18, 2022


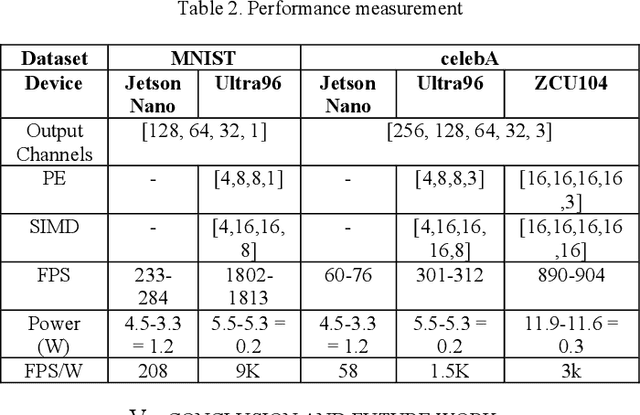
Generative Adversarial Networks (GAN) are cutting-edge algorithms for generating new data samples based on the learned data distribution. However, its performance comes at a significant cost in terms of computation and memory requirements. In this paper, we proposed an HW/SW co-design approach for training quantized deconvolution GAN (QDCGAN) implemented on FPGA using a scalable streaming dataflow architecture capable of achieving higher throughput versus resource utilization trade-off. The developed accelerator is based on an efficient deconvolution engine that offers high parallelism with respect to scaling factors for GAN-based edge computing. Furthermore, various precisions, datasets, and network scalability were analyzed for low-power inference on resource-constrained platforms. Lastly, an end-to-end open-source framework is provided for training, implementation, state-space exploration, and scaling the inference using Vivado high-level synthesis for Xilinx SoC-FPGAs, and a comparison testbed with Jetson Nano.