 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvivable Robotic Control through Guided Bayesian Policy Search with Deep Reinforcement Learning
Jun 29, 2021
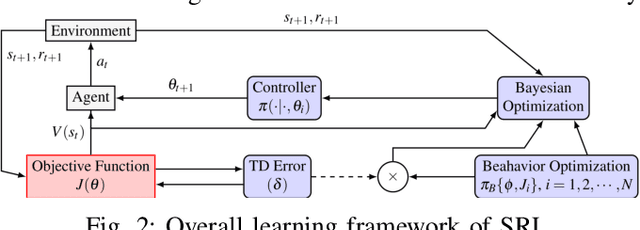
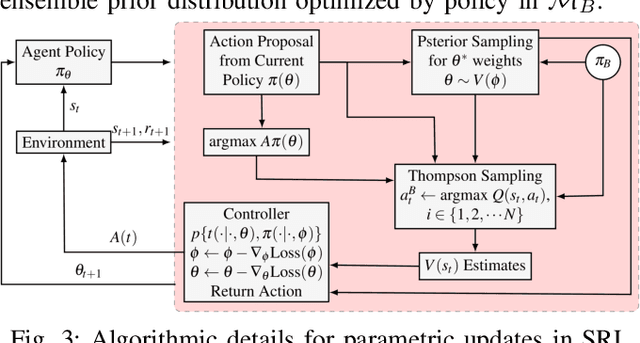

Many robot manipulation skills can be represented with deterministic characteristics and there exist efficient techniques for learning parameterized motor plans for those skills. However, one of the active research challenge still remains to sustain manipulation capabilities in situation of a mechanical failure. Ideally, like biological creatures, a robotic agent should be able to reconfigure its control policy by adapting to dynamic adversaries. In this paper, we propose a method that allows an agent to survive in a situation of mechanical loss, and adaptively learn manipulation with compromised degrees of freedom -- we call our method Survivable Robotic Learning (SRL). Our key idea is to leverage Bayesian policy gradient by encoding knowledge bias in posterior estimation, which in turn alleviates future policy search explorations, in terms of sample efficiency and when compared to random exploration based policy search methods. SRL represents policy priors as Gaussian process, which allows tractable computation of approximate posterior (when true gradient is intractable), by incorporating guided bias as proxy from prior replays. We evaluate our proposed method against off-the-shelf model free learning algorithm (DDPG), testing on a hexapod robot platform which encounters incremental failure emulation, and our experiments show that our method improves largely in terms of sample requirement and quantitative success ratio in all failure modes. A demonstration video of our experiments can be viewed at: https://sites.google.com/view/survivalrl
Survivable Hyper-Redundant Robotic Arm with Bayesian Policy Morphing
Oct 20, 2020

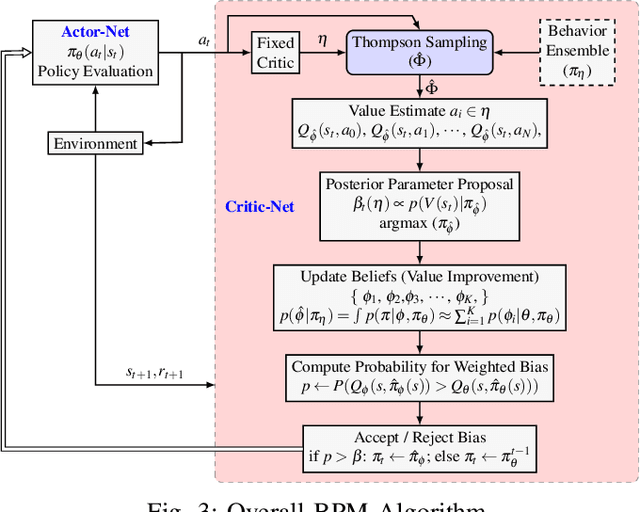

In this paper we present a Bayesian reinforcement learning framework that allows robotic manipulators to adaptively recover from random mechanical failures autonomously, hence being survivable. To this end, we formulate the framework of Bayesian Policy Morphing (BPM) that enables a robot agent to self-modify its learned policy after the diminution of its maneuvering dimensionality. We build upon existing actor-critic framework, and extend it to perform policy gradient updates as posterior learning, taking past policy updates as prior distributions. We show that policy search, in the direction biased by prior experience, significantly improves learning efficiency in terms of sampling requirements. We demonstrate our results on an 8-DOF robotic arm with our algorithm of BPM, while intentionally disabling random joints with different damage types like unresponsive joints, constant offset errors and angular imprecision. Our results have shown that, even with physical damages, the robotic arm can still successfully maintain its functionality to accurately locate and grasp a given target object.
Real-World Modeling of a Pathfinding Robot Using Robot Operating System
Feb 27, 2018



This paper presents a practical approach towards implementing pathfinding algorithms on real-world and low-cost non- commercial hardware platforms. While using robotics simulation platforms as a test-bed for our algorithms we easily overlook real- world exogenous problems that are developed by external factors. Such problems involve robot wheel slips, asynchronous motors, abnormal sensory data or unstable power sources. The real-world dynamics tend to be very painful even for executing simple algorithms like a Wavefront planner or A-star search. This paper addresses designing techniques that tend to be robust as well as reusable for any hardware platforms; covering problems like controlling asynchronous drives, odometry offset issues and handling abnormal sensory feedback. The algorithm implementation medium and hardware design tools have been kept general in order to present our work as a serving platform for future researchers and robotics enthusiast working in the field of path planning robotics.