 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Generated Natural Language Meets Scaling Laws: New Explorations and Data Augmentation Methods
Jun 29, 2024With the ascent of large language models (LLM), natural language processing has witnessed enhancements, such as LLM-based data augmentation. Nonetheless, prior research harbors two primary concerns: firstly, a lack of contemplation regarding whether the natural language generated by LLM (LLMNL) truly aligns with human natural language (HNL), a critical foundational question; secondly, an oversight that augmented data is randomly generated by LLM, implying that not all data may possess equal training value, that could impede the performance of classifiers. To address these challenges, we introduce the scaling laws to intrinsically calculate LLMNL and HNL. Through extensive experiments, we reveal slight deviations (approximately 0.2 Mandelbrot exponent) from Mandelbrot's law in LLMNL, underscore a complexity advantage in HNL, and supplement an interpretive discussion on language style. This establishes a solid foundation for LLM's expansion. Further, we introduce a novel data augmentation method for few-shot text classification, termed ZGPTDA, which leverages fuzzy computing mechanisms driven by the conformity to scaling laws to make decisions about GPT-4 augmented data. Extensive experiments, conducted in real-world scenarios, confirms the effectiveness (improving F1 of Bert and RoBerta by 7-10%) and competitiveness (surpassing recent AugGPT and GENCO methods by about 2% accuracy on DeBerta) of ZGPTDA. In addition, we reveal some interesting insights, e.g., Hilberg's law and Taylor's law can impart more benefits to text classification, etc.
Will Sentiment Analysis Need Subculture? A New Data Augmentation Approach
Sep 01, 2023The renowned proverb that "The pen is mightier than the sword" underscores the formidable influence wielded by text expressions in shaping sentiments. Indeed, well-crafted written can deeply resonate within cultures, conveying profound sentiments. Nowadays, the omnipresence of the Internet has fostered a subculture that congregates around the contemporary milieu. The subculture artfully articulates the intricacies of human feelings by ardently pursuing the allure of novelty, a fact that cannot be disregarded in the sentiment analysis. This paper strives to enrich data through the lens of subculture, to address the insufficient training data faced by sentiment analysis. To this end, a new approach of subculture-based data augmentation (SCDA) is proposed, which engenders six enhanced texts for each training text by leveraging the creation of six diverse subculture expression generators. The extensive experiments attest to the effectiveness and potential of SCDA. The results also shed light on the phenomenon that disparate subculture expressions elicit varying degrees of sentiment stimulation. Moreover, an intriguing conjecture arises, suggesting the linear reversibility of certain subculture expressions. It is our fervent aspiration that this study serves as a catalyst in fostering heightened perceptiveness towards the tapestry of information, sentiment and culture, thereby enriching our collective understanding.
Exploring the law of text geographic information
Sep 01, 2023Textual geographic information is indispensable and heavily relied upon in practical applications. The absence of clear distribution poses challenges in effectively harnessing geographic information, thereby driving our quest for exploration. We contend that geographic information is influenced by human behavior, cognition, expression, and thought processes, and given our intuitive understanding of natural systems, we hypothesize its conformity to the Gamma distribution. Through rigorous experiments on a diverse range of 24 datasets encompassing different languages and types, we have substantiated this hypothesis, unearthing the underlying regularities governing the dimensions of quantity, length, and distance in geographic information. Furthermore, theoretical analyses and comparisons with Gaussian distributions and Zipf's law have refuted the contingency of these laws. Significantly, we have estimated the upper bounds of human utilization of geographic information, pointing towards the existence of uncharted territories. Also, we provide guidance in geographic information extraction. Hope we peer its true countenance uncovering the veil of geographic information.
Classification of hazard event via language fractal
Sep 12, 2022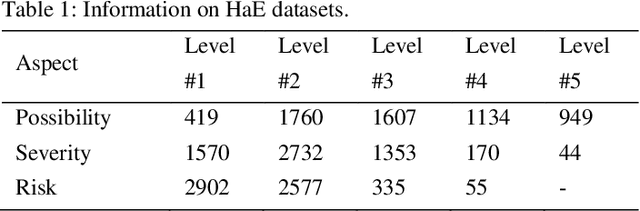
HAZOP is a safety paradigm undertaken to reveal hazards in industry, its report covers valuable hazard events (HaE). The research on HaE classification has much irreplaceable pragmatic values. However, no study has paid such attention to this topic. In this paper, we present a novel deep learning model termed DLF to explore the HaE classification through fractal method from the perspective of language. The motivation is that (1): HaE can be naturally regarded as a kind of time series; (2): the meaning of HaE is driven by word arrangement. Specifically, first we employ BERT to vectorize HaE. Then, we propose a new multifractal method termed HmF-DFA to calculate HaE fractal series by analyzing the HaE vector who is regarded as a time series. Finally, we design a new hierarchical gating neural network (HGNN) to process the HaE fractal series to accomplish the classification of HaE. We take 18 processes for case study. We launch the experiment on the basis of their HAZOP reports. Experimental results demonstrate that our DLF classifier is satisfactory and promising, the proposed HmF-DFA and HGNN are effective, and the introduction of language fractal into HaE is feasible. Our HaE classification system can serve HAZOP and bring application incentives to experts, engineers, employees, and other enterprises, which is conducive to the intelligent development of industrial safety. We hope our research can contribute added support to the daily practice in industrial safety and fractal theory.
Yes, DLGM! A novel hierarchical model for hazard classification
Sep 10, 2022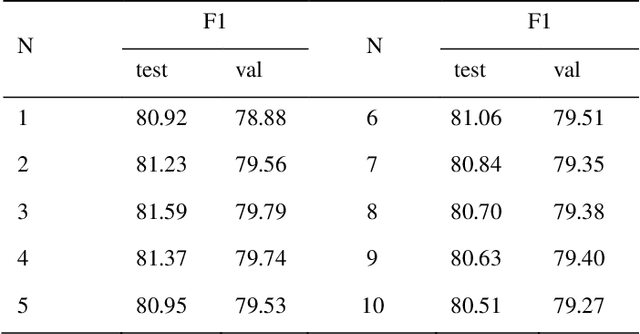
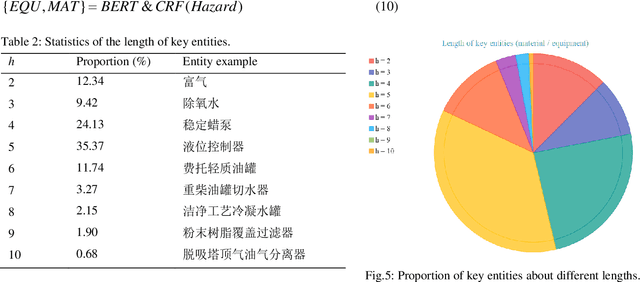

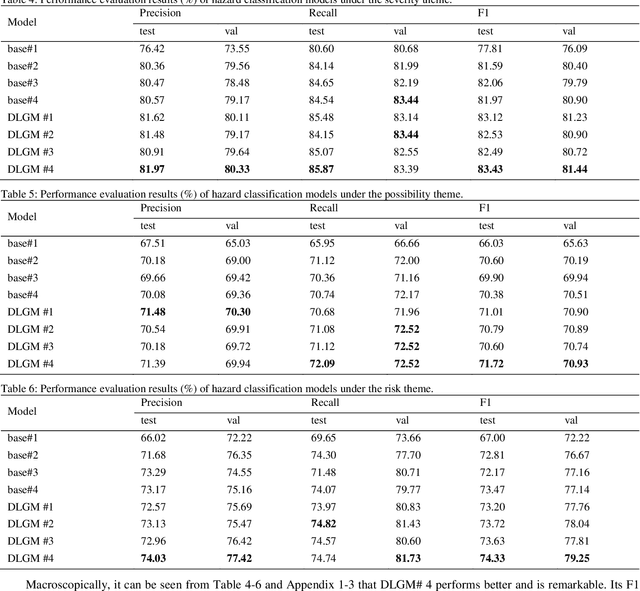
Hazards can be exposed by HAZOP as text information, and studying their classification is of great significance to the development of industrial informatics, which is conducive to safety early warning, decision support, policy evaluation, etc. However, there is no research on this important field at present. In this paper, we propose a novel model termed DLGM via deep learning for hazard classification. Specifically, first, we leverage BERT to vectorize the hazard and treat it as a type of time series (HTS). Secondly, we build a grey model FSGM(1, 1) to model it, and get the grey guidance in the sense of the structural parameters. Finally, we design a hierarchical-feature fusion neural network (HFFNN) to investigate the HTS with grey guidance (HTSGG) from three themes, where, HFFNN is a hierarchical structure with four types of modules: two feature encoders, a gating mechanism, and a deepening mechanism. We take 18 industrial processes as application cases and launch a series of experiments. The experimental results prove that DLGM has promising aptitudes for hazard classification and that FSGM(1, 1) and HFFNN are effective. We hope our research can contribute added value and support to the daily practice in industrial safety.
Exploring industrial safety knowledge via Zipf law
May 25, 2022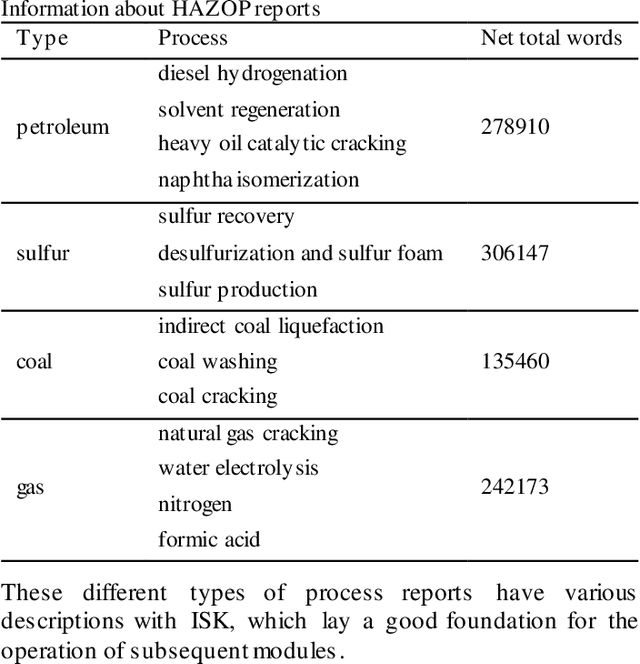
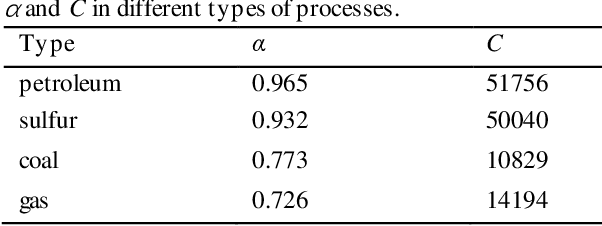
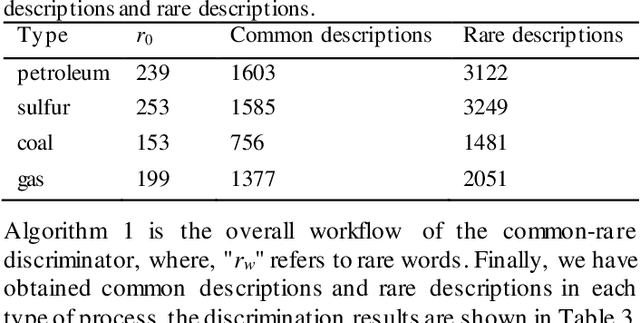
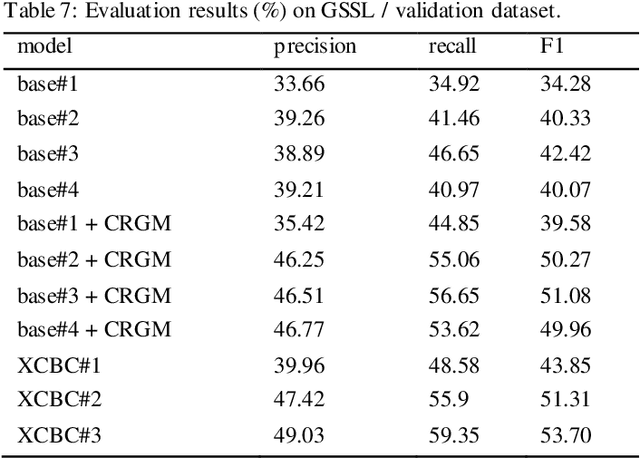
The hazard and operability analysis (HAZOP) report contains precious industrial safety knowledge (ISK) with expert experience and process nature, which is of great significance to the development of industrial intelligence. Subject to the attributes of ISK, existing researches mine them through sequence labeling in deep learning. Yet, there are two thorny issues: (1) Uneven distribution of ISK and (2) Consistent importance of ISK: for safety review. In this study, we propose a novel generative mining strategy called CRGM to explore ISK. Inspired Zipf law in linguistics, CRGM consists of common-rare discriminator, induction-extension generator and ISK extractor. Firstly, the common-rare discriminator divides HAZOP descriptions into common words and rare words, and obtains the common description and the rare description, where the latter contains more industrial substances. Then, they are operated by the induction-extension generator in the way of deep text generation, the common description is induced and the rare description is extended, the material knowledge and the equipment knowledge can be enriched. Finally, the ISK extractor processes the material knowledge and equipment knowledge from the generated description through the rule template method, the additional ISK is regarded as the supplement of the training set to train the proposed sequence labeling model. We conduct multiple evaluation experiments on two industrial safety datasets. The results show that CRGM has promising and gratifying aptitudes, greatly improves the performance of the model, and is efficient and generalized. Our sequence labeling model also shows the expected performance, which is better than the existing research. Our research provides a new perspective for exploring ISK, we hope it can contribute support for the intelligent progress of industrial safety.