 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling for Gaussian Entropic Risk Bandits
May 14, 2021The multi-armed bandit (MAB) problem is a ubiquitous decision-making problem that exemplifies exploration-exploitation tradeoff. Standard formulations exclude risk in decision making. Risknotably complicates the basic reward-maximising objectives, in part because there is no universally agreed definition of it. In this paper, we consider an entropic risk (ER) measure and explore the performance of a Thompson sampling-based algorithm ERTS under this risk measure by providing regret bounds for ERTS and corresponding instance dependent lower bounds.
Refining Deep Generative Models via Wasserstein Gradient Flows
Dec 01, 2020


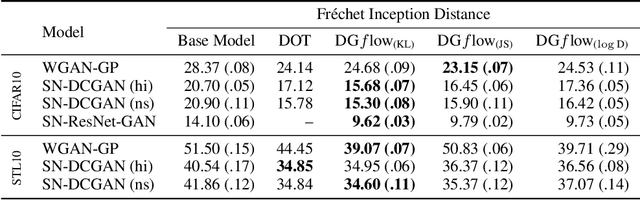
Deep generative modeling has seen impressive advances in recent years, to the point where it is now commonplace to see simulated samples (e.g., images) that closely resemble real-world data. However, generation quality is generally inconsistent for any given model and can vary dramatically between samples. We introduce Discriminator Gradient flow (DGflow), a new technique that improves generated samples via the gradient flow of entropy-regularized f-divergences between the real and the generated data distributions. The gradient flow takes the form of a non-linear Fokker-Plank equation, which can be easily simulated by sampling from the equivalent McKean-Vlasov process. By refining inferior samples, our technique avoids wasteful sample rejection used by previous methods (DRS & MH-GAN). Compared to existing works that focus on specific GAN variants, we show our refinement approach can be applied to GANs with vector-valued critics and even other deep generative models such as VAEs and Normalizing Flows. Empirical results on multiple synthetic, image, and text datasets demonstrate that DGflow leads to significant improvement in the quality of generated samples for a variety of generative models, outperforming the state-of-the-art Discriminator Optimal Transport (DOT) and Discriminator Driven Latent Sampling (DDLS) methods.