 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Click Models for Recommender Systems
Sep 30, 2024We develop and evaluate neural architectures to model the user behavior in recommender systems (RS) inspired by click models for Web search but going beyond standard click models. Proposed architectures include recurrent networks, Transformer-based models that alleviate the quadratic complexity of self-attention, adversarial and hierarchical architectures. Our models outperform baselines on the ContentWise and RL4RS datasets and can be used in RS simulators to model user response for RS evaluation and pretraining.
$ abla^2$DFT: A Universal Quantum Chemistry Dataset of Drug-Like Molecules and a Benchmark for Neural Network Potentials
Jun 20, 2024Methods of computational quantum chemistry provide accurate approximations of molecular properties crucial for computer-aided drug discovery and other areas of chemical science. However, high computational complexity limits the scalability of their applications. Neural network potentials (NNPs) are a promising alternative to quantum chemistry methods, but they require large and diverse datasets for training. This work presents a new dataset and benchmark called $\nabla^2$DFT that is based on the nablaDFT. It contains twice as much molecular structures, three times more conformations, new data types and tasks, and state-of-the-art models. The dataset includes energies, forces, 17 molecular properties, Hamiltonian and overlap matrices, and a wavefunction object. All calculations were performed at the DFT level ($\omega$B97X-D/def2-SVP) for each conformation. Moreover, $\nabla^2$DFT is the first dataset that contains relaxation trajectories for a substantial number of drug-like molecules. We also introduce a novel benchmark for evaluating NNPs in molecular property prediction, Hamiltonian prediction, and conformational optimization tasks. Finally, we propose an extendable framework for training NNPs and implement 10 models within it.
Machine Learning for SAT: Restricted Heuristics and New Graph Representations
Jul 18, 2023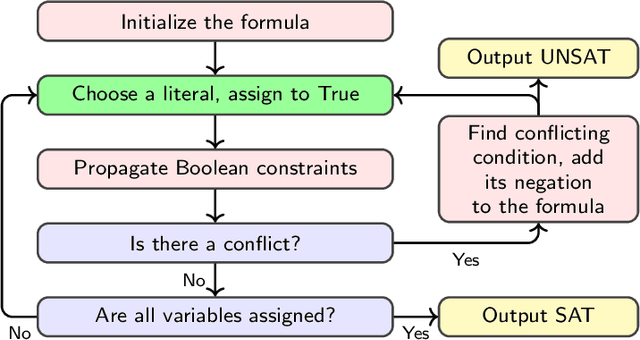
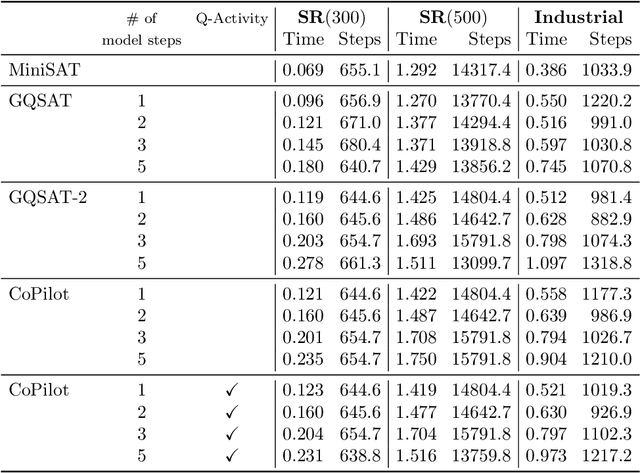
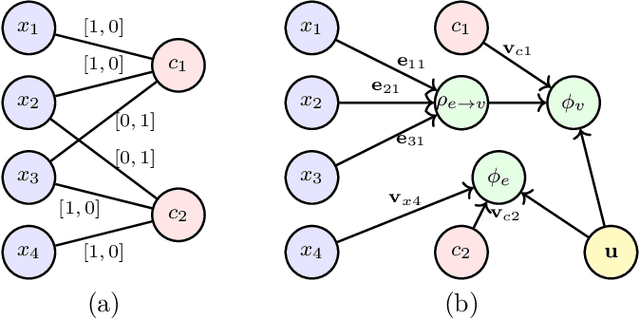
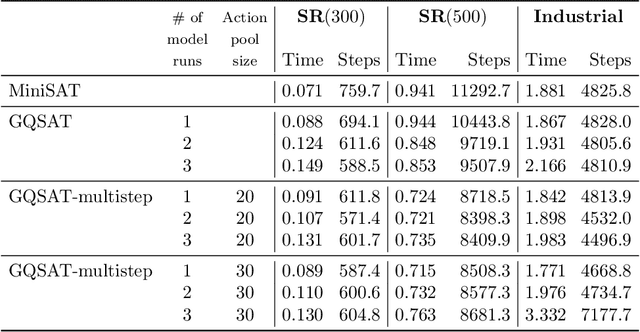
Boolean satisfiability (SAT) is a fundamental NP-complete problem with many applications, including automated planning and scheduling. To solve large instances, SAT solvers have to rely on heuristics, e.g., choosing a branching variable in DPLL and CDCL solvers. Such heuristics can be improved with machine learning (ML) models; they can reduce the number of steps but usually hinder the running time because useful models are relatively large and slow. We suggest the strategy of making a few initial steps with a trained ML model and then releasing control to classical heuristics; this simplifies cold start for SAT solving and can decrease both the number of steps and overall runtime, but requires a separate decision of when to release control to the solver. Moreover, we introduce a modification of Graph-Q-SAT tailored to SAT problems converted from other domains, e.g., open shop scheduling problems. We validate the feasibility of our approach with random and industrial SAT problems.