 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of General-Purpose Embeddings for Code Changes
Jun 03, 2021

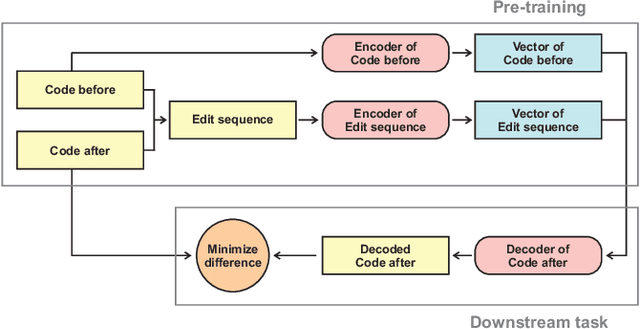

A lot of problems in the field of software engineering - bug fixing, commit message generation, etc. - require analyzing not only the code itself but specifically code changes. Applying machine learning models to these tasks requires us to create numerical representations of the changes, i.e. embeddings. Recent studies demonstrate that the best way to obtain these embeddings is to pre-train a deep neural network in an unsupervised manner on a large volume of unlabeled data and then further fine-tune it for a specific task. In this work, we propose an approach for obtaining such embeddings of code changes during pre-training and evaluate them on two different downstream tasks - applying changes to code and commit message generation. The pre-training consists of the model learning to apply the given change (an edit sequence) to the code in a correct way, and therefore requires only the code change itself. To increase the quality of the obtained embeddings, we only consider the changed tokens in the edit sequence. In the task of applying code changes, our model outperforms the model that uses full edit sequences by 5.9 percentage points in accuracy. As for the commit message generation, our model demonstrated the same results as supervised models trained for this specific task, which indicates that it can encode code changes well and can be improved in the future by pre-training on a larger dataset of easily gathered code changes.