 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular End-to-End Multimodal Learning Method for Structured and Unstructured Data
Mar 07, 2024Multimodal learning is a rapidly growing research field that has revolutionized multitasking and generative modeling in AI. While much of the research has focused on dealing with unstructured data (e.g., language, images, audio, or video), structured data (e.g., tabular data, time series, or signals) has received less attention. However, many industry-relevant use cases involve or can be benefited from both types of data. In this work, we propose a modular, end-to-end multimodal learning method called MAGNUM, which can natively handle both structured and unstructured data. MAGNUM is flexible enough to employ any specialized unimodal module to extract, compress, and fuse information from all available modalities.
Do we still need fuzzy classifiers for Small Data in the Era of Big Data?
Mar 08, 2019

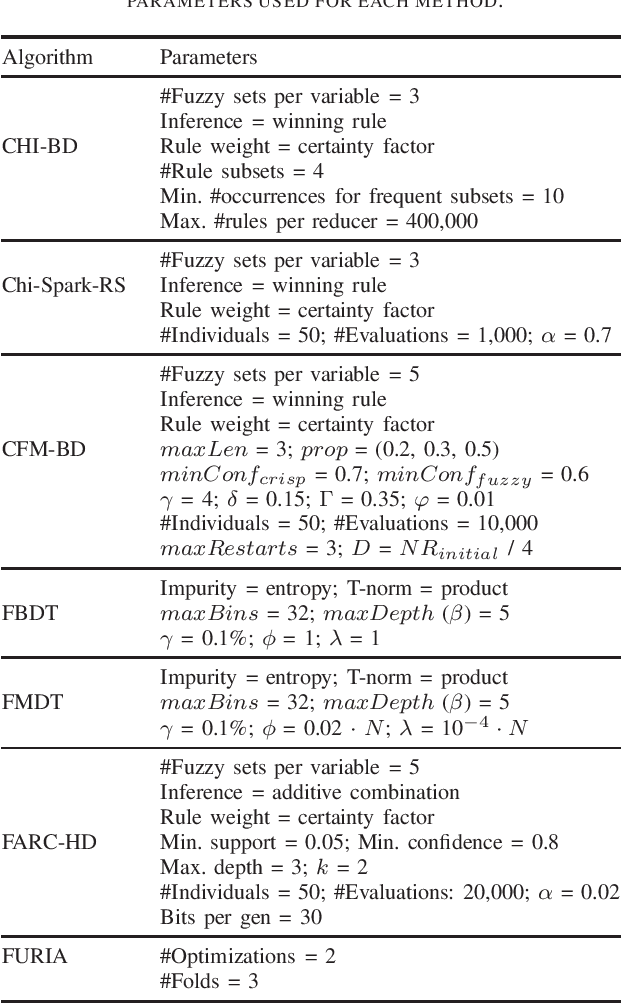
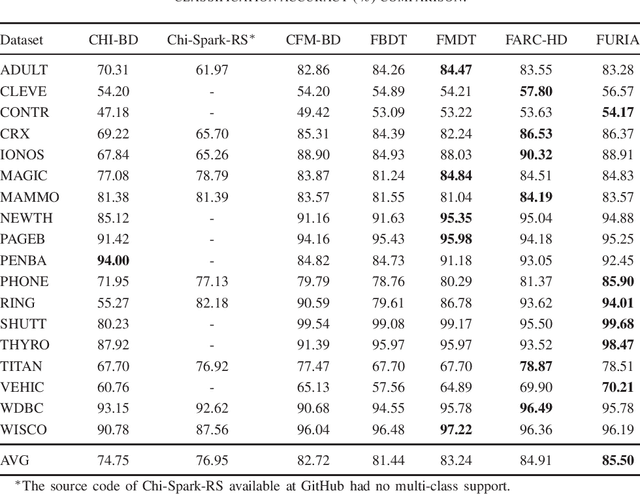
The Era of Big Data has forced researchers to explore new distributed solutions for building fuzzy classifiers, which often introduce approximation errors or make strong assumptions to reduce computational and memory requirements. As a result, Big Data classifiers might be expected to be inferior to those designed for standard classification tasks (Small Data) in terms of accuracy and model complexity. To our knowledge, however, there is no empirical evidence to confirm such a conjecture yet. Here, we investigate the extent to which state-of-the-art fuzzy classifiers for Big Data sacrifice performance in favor of scalability. To this end, we carry out an empirical study that compares these classifiers with some of the best performing algorithms for Small Data. Assuming the latter were generally designed for maximizing performance without considering scalability issues, the results of this study provide some intuition around the tradeoff between performance and scalability achieved by current Big Data solutions. Our findings show that, although slightly inferior, Big Data classifiers are gradually catching up with state-of-the-art classifiers for Small data, suggesting that a unified learning algorithm for Big and Small Data might be possible.
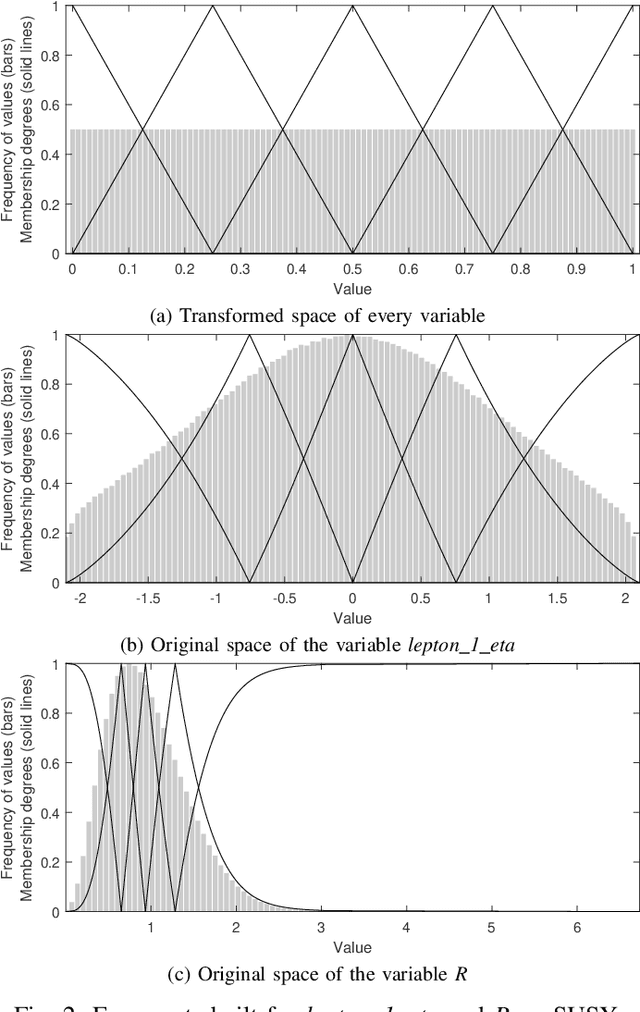
On the usage of the probability integral transform to reduce the complexity of multi-way fuzzy decision trees in Big Data classification problems
Feb 28, 2019
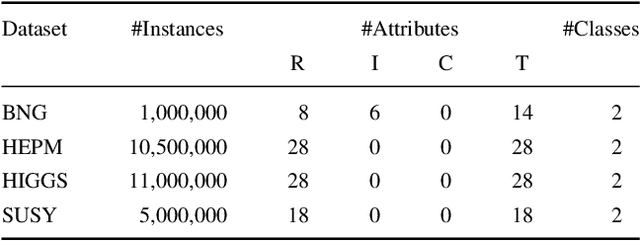

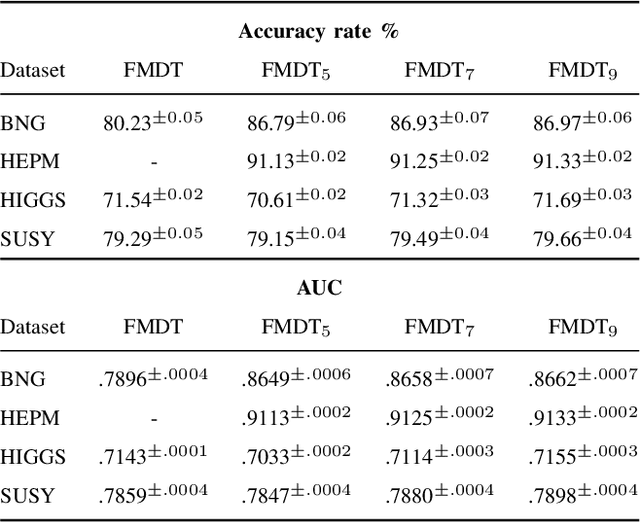
We present a new distributed fuzzy partitioning method to reduce the complexity of multi-way fuzzy decision trees in Big Data classification problems. The proposed algorithm builds a fixed number of fuzzy sets for all variables and adjusts their shape and position to the real distribution of training data. A two-step process is applied : 1) transformation of the original distribution into a standard uniform distribution by means of the probability integral transform. Since the original distribution is generally unknown, the cumulative distribution function is approximated by computing the q-quantiles of the training set; 2) construction of a Ruspini strong fuzzy partition in the transformed attribute space using a fixed number of equally distributed triangular membership functions. Despite the aforementioned transformation, the definition of every fuzzy set in the original space can be recovered by applying the inverse cumulative distribution function (also known as quantile function). The experimental results reveal that the proposed methodology allows the state-of-the-art multi-way fuzzy decision tree (FMDT) induction algorithm to maintain classification accuracy with up to 6 million fewer leaves.
CFM-BD: a distributed rule induction algorithm for building Compact Fuzzy Models in Big Data classification problems
Feb 25, 2019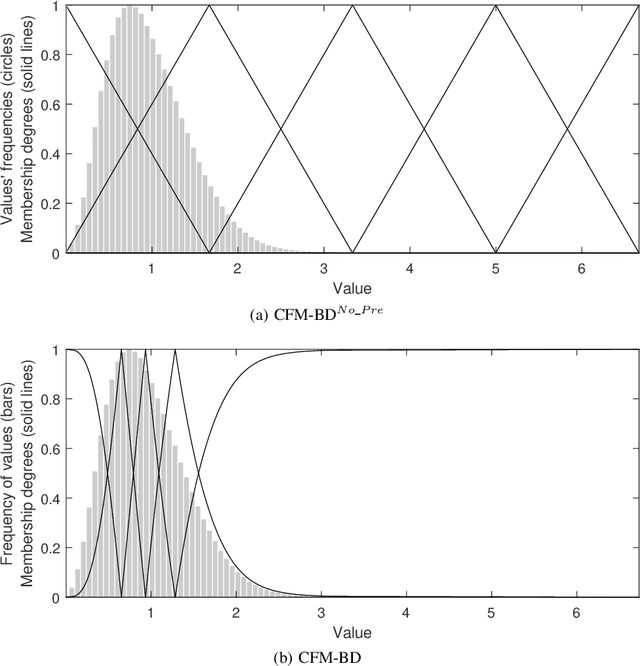


Interpretability has always been a major concern for fuzzy rule-based classifiers. The usage of human-readable models allows them to explain the reasoning behind their predictions and decisions. However, when it comes to Big Data classification problems, fuzzy rule-based classifiers have not been able to maintain the good trade-off between accuracy and interpretability that has characterized these techniques in non-Big Data environments. The most accurate methods build too complex models composed of a large number of rules and fuzzy sets, while those approaches focusing on interpretability do not provide state-of-the-art discrimination capabilities. In this paper, we propose a new distributed learning algorithm named CFM-BD to construct accurate and compact fuzzy rule-based classification systems for Big Data. This method has been specifically designed from scratch for Big Data problems and does not adapt or extend any existing algorithm. The proposed learning process consists of three stages: 1) pre-processing based on the probability integral transform theorem; 2) rule induction inspired by CHI-BD and Apriori algorithms; 3) rule selection by means of a global evolutionary optimization. We conducted a complete empirical study to test the performance of our approach in terms of accuracy, complexity, and runtime. The results obtained were compared and contrasted with four state-of-the-art fuzzy classifiers for Big Data (FBDT, FMDT, Chi-Spark-RS, and CHI-BD). According to this study, CFM-BD is able to provide competitive discrimination capabilities using significantly simpler models composed of a few rules of less than 3 antecedents, employing 5 linguistic labels for all variables.