 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo we still need fuzzy classifiers for Small Data in the Era of Big Data?
Paper and Code
Mar 08, 2019

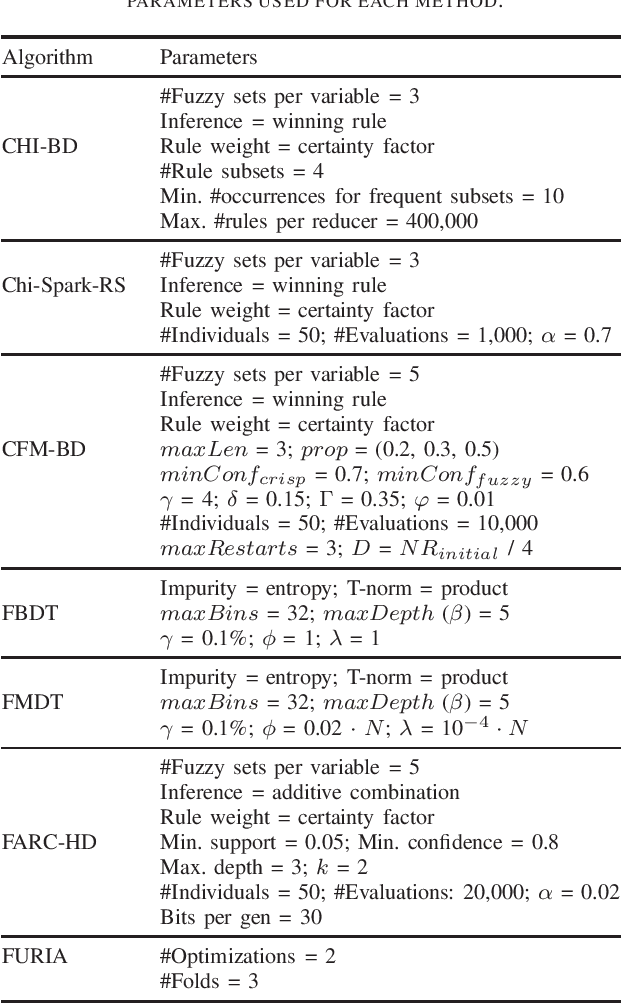
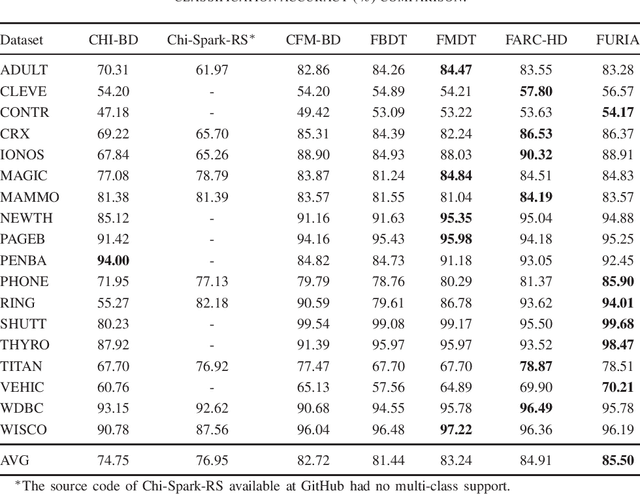
The Era of Big Data has forced researchers to explore new distributed solutions for building fuzzy classifiers, which often introduce approximation errors or make strong assumptions to reduce computational and memory requirements. As a result, Big Data classifiers might be expected to be inferior to those designed for standard classification tasks (Small Data) in terms of accuracy and model complexity. To our knowledge, however, there is no empirical evidence to confirm such a conjecture yet. Here, we investigate the extent to which state-of-the-art fuzzy classifiers for Big Data sacrifice performance in favor of scalability. To this end, we carry out an empirical study that compares these classifiers with some of the best performing algorithms for Small Data. Assuming the latter were generally designed for maximizing performance without considering scalability issues, the results of this study provide some intuition around the tradeoff between performance and scalability achieved by current Big Data solutions. Our findings show that, although slightly inferior, Big Data classifiers are gradually catching up with state-of-the-art classifiers for Small data, suggesting that a unified learning algorithm for Big and Small Data might be possible.