 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting the scanner effect in brain MRI segmentation with a progressive level-of-detail network trained on multi-site data
Nov 04, 2022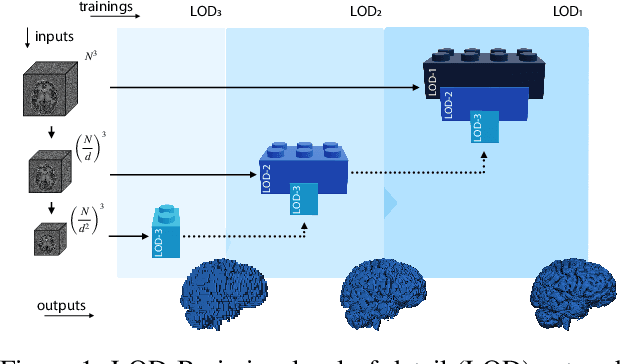

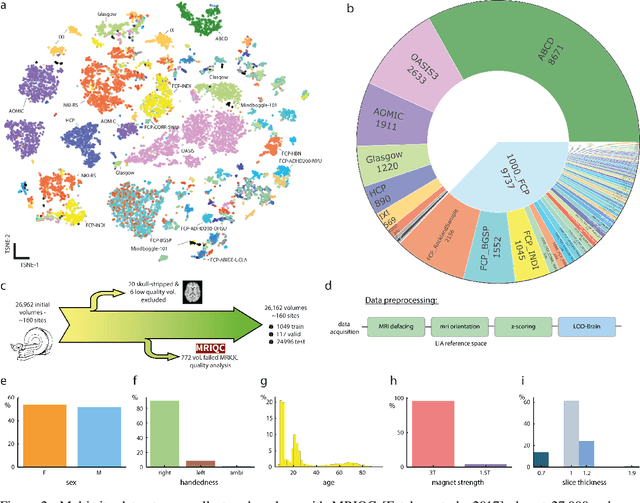
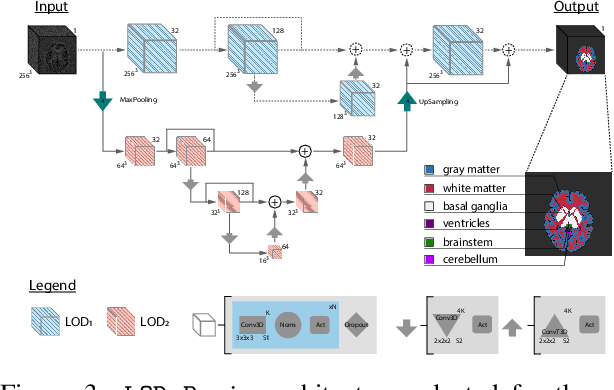
Many clinical and research studies of the human brain require an accurate structural MRI segmentation. While traditional atlas-based methods can be applied to volumes from any acquisition site, recent deep learning algorithms ensure very high accuracy only when tested on data from the same sites exploited in training (i.e., internal data). The performance degradation experienced on external data (i.e., unseen volumes from unseen sites) is due to the inter-site variabilities in intensity distributions induced by different MR scanner models, acquisition parameters, and unique artefacts. To mitigate this site-dependency, often referred to as the scanner effect, we propose LOD-Brain, a 3D convolutional neural network with progressive levels-of-detail (LOD) able to segment brain data from any site. Coarser network levels are responsible to learn a robust anatomical prior useful for identifying brain structures and their locations, while finer levels refine the model to handle site-specific intensity distributions and anatomical variations. We ensure robustness across sites by training the model on an unprecedented rich dataset aggregating data from open repositories: almost 27,000 T1w volumes from around 160 acquisition sites, at 1.5 - 3T, from a population spanning from 8 to 90 years old. Extensive tests demonstrate that LOD-Brain produces state-of-the-art results, with no significant difference in performance between internal and external sites, and robust to challenging anatomical variations. Its portability opens the way for large scale application across different healthcare institutions, patient populations, and imaging technology manufacturers. Code, model, and demo are available at the project website.
CEREBRUM: a fast and fully-volumetric Convolutional Encoder-decodeR for weakly-supervised sEgmentation of BRain strUctures from out-of-the-scanner MRI
Sep 26, 2019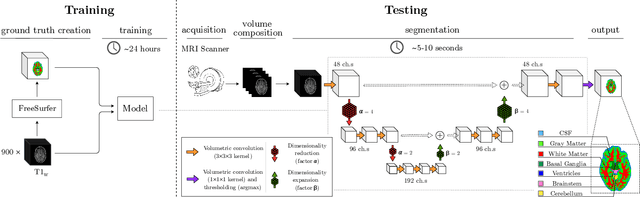
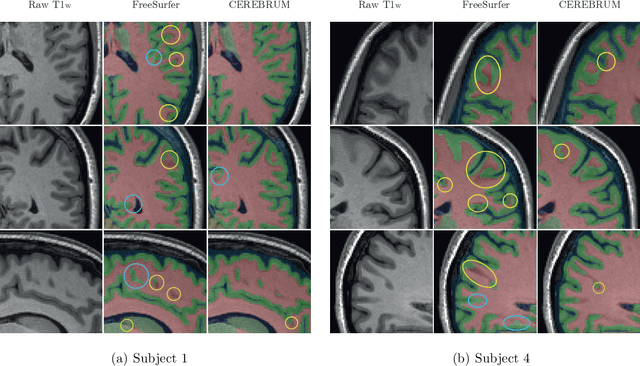
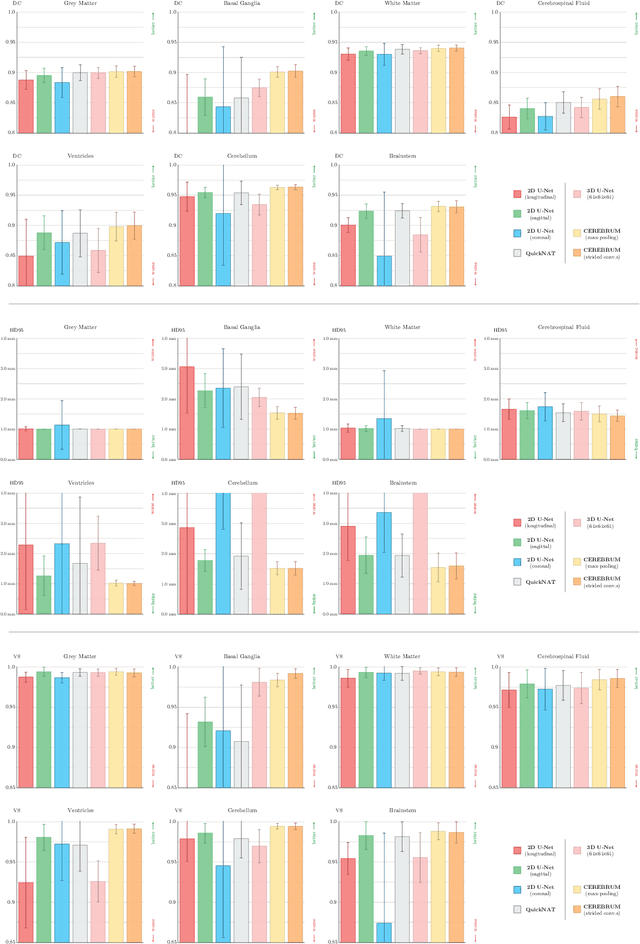
Many functional and structural neuroimaging studies call for accurate morphometric segmentation of different brain structures starting from image intensity values of MRI scans. Current automatic (multi-) atlas-based segmentation strategies often lack accuracy on difficult-to-segment brain structures and, since these methods rely on atlas-to-scan alignment, they may take long processing times. Recently, methods deploying solutions based on Convolutional Neural Networks (CNNs) are making the direct analysis of out-of-the-scanner data feasible. However, current CNN-based solutions partition the test volume into 2D or 3D patches, which are processed independently. This entails a loss of global contextual information thereby negatively impacting the segmentation accuracy. In this work, we design and test an optimised end-to-end CNN architecture that makes the exploitation of global spatial information computationally tractable, allowing to process a whole MRI volume at once. We adopt a weakly supervised learning strategy by exploiting a large dataset composed by 947 out-of-the-scanner (3 Tesla T1-weighted 1mm isotropic MP-RAGE 3D sequences) MR Images. The resulting model is able to produce accurate multi-structure segmentation results in only few seconds. Different quantitative measures demonstrate an improved accuracy of our solution when compared to state-of-the-art techniques. Moreover, through a randomised survey involving expert neuroscientists, we show that subjective judgements clearly prefer our solution with respect to the widely adopted atlas-based FreeSurfer software.
Deep driven fMRI decoding of visual categories
Jan 09, 2017
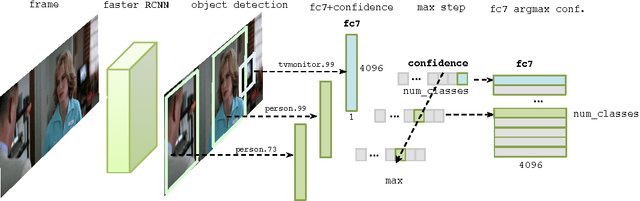
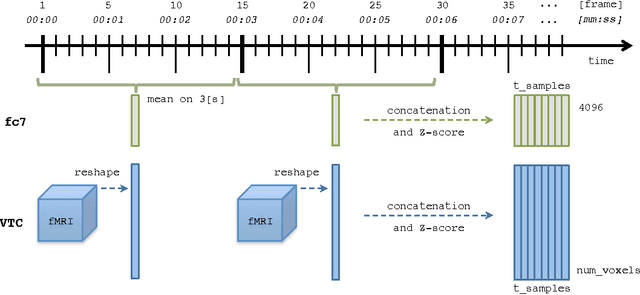
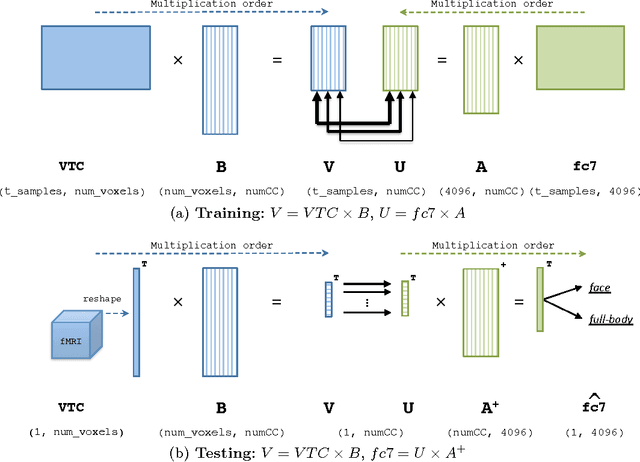
Deep neural networks have been developed drawing inspiration from the brain visual pathway, implementing an end-to-end approach: from image data to video object classes. However building an fMRI decoder with the typical structure of Convolutional Neural Network (CNN), i.e. learning multiple level of representations, seems impractical due to lack of brain data. As a possible solution, this work presents the first hybrid fMRI and deep features decoding approach: collected fMRI and deep learnt representations of video object classes are linked together by means of Kernel Canonical Correlation Analysis. In decoding, this allows exploiting the discriminatory power of CNN by relating the fMRI representation to the last layer of CNN (fc7). We show the effectiveness of embedding fMRI data onto a subspace related to deep features in distinguishing semantic visual categories based solely on brain imaging data.