 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXFBoost: Improving Text Generation with Controllable Decoders
Feb 16, 2022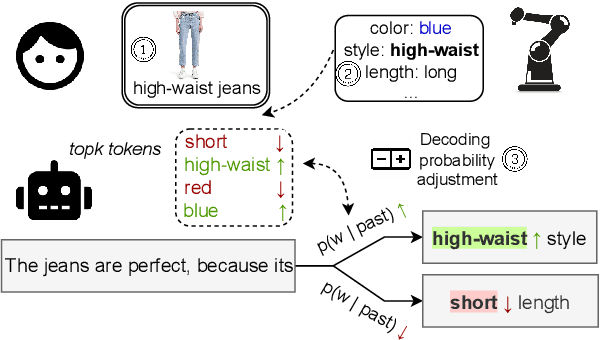


Multimodal conditionality in transformer-based natural language models has demonstrated state-of-the-art performance in the task of product description generation. Recent approaches condition a language model on one or more images and other textual metadata to achieve near-human performance for describing products from e-commerce stores. However, generated descriptions may exhibit degrees of inaccuracy or even contradictory claims relative to the inputs of a given product. In this paper, we propose a controllable language generation framework called Extract-Finetune-Boost (XFBoost), which addresses the problem of inaccurate low-quality inference. By using visual semantic attributes as constraints at the decoding stage of the generation process and finetuning the language model with policy gradient techniques, the XFBoost framework is found to produce significantly more descriptive text with higher image relevancy, outperforming baselines and lowering the frequency of factually inaccurate descriptions. We further demonstrate the application of XFBoost to online learning wherein human-in-the-loop critics improve language models with active feedback.
Multimodal Conditionality for Natural Language Generation
Sep 02, 2021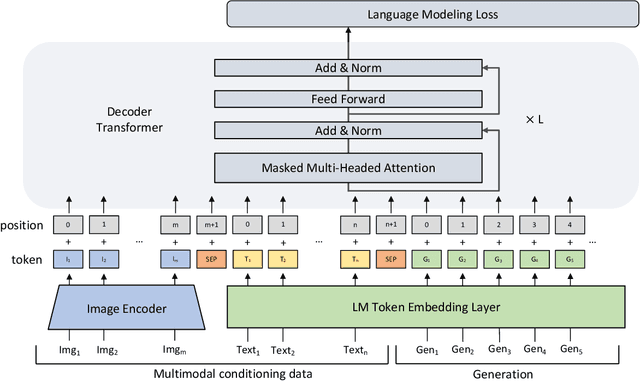

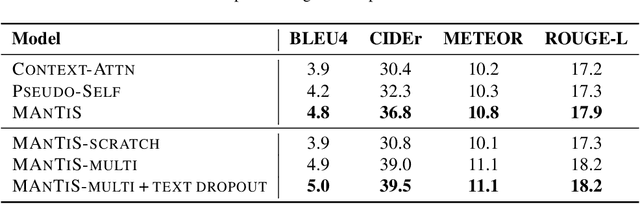

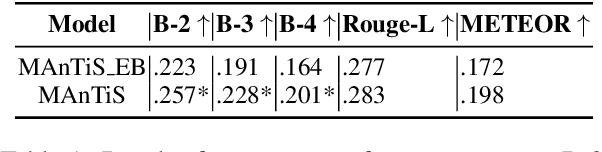
Large scale pretrained language models have demonstrated state-of-the-art performance in language understanding tasks. Their application has recently expanded into multimodality learning, leading to improved representations combining vision and language. However, progress in adapting language models towards conditional Natural Language Generation (NLG) has been limited to a single modality, generally text. We propose MAnTiS, Multimodal Adaptation for Text Synthesis, a general approach for multimodal conditionality in transformer-based NLG models. In this method, we pass inputs from each modality through modality-specific encoders, project to textual token space, and finally join to form a conditionality prefix. We fine-tune the pretrained language model and encoders with the conditionality prefix guiding the generation. We apply MAnTiS to the task of product description generation, conditioning a network on both product images and titles to generate descriptive text. We demonstrate that MAnTiS outperforms strong baseline approaches on standard NLG scoring metrics. Furthermore, qualitative assessments demonstrate that MAnTiS can generate human quality descriptions consistent with given multimodal inputs.
Copyspace: Where to Write on Images?
Dec 04, 2020


The placement of text over an image is an important part of producing high-quality visual designs. Automating this work by determining appropriate position, orientation, and style for textual elements requires understanding the contents of the background image. We refer to the search for aesthetic parameters of text rendered over images as "copyspace detection", noting that this task is distinct from foreground-background separation. We have developed solutions using one and two stage object detection methodologies trained on an expertly labeled data. This workshop will examine such algorithms for copyspace detection and demonstrate their application in generative design models and pipelines such as Einstein Designer.
GarmentGAN: Photo-realistic Adversarial Fashion Transfer
Mar 04, 2020
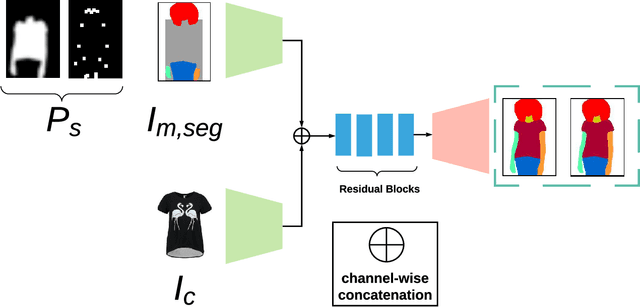


The garment transfer problem comprises two tasks: learning to separate a person's body (pose, shape, color) from their clothing (garment type, shape, style) and then generating new images of the wearer dressed in arbitrary garments. We present GarmentGAN, a new algorithm that performs image-based garment transfer through generative adversarial methods. The GarmentGAN framework allows users to virtually try-on items before purchase and generalizes to various apparel types. GarmentGAN requires as input only two images, namely, a picture of the target fashion item and an image containing the customer. The output is a synthetic image wherein the customer is wearing the target apparel. In order to make the generated image look photo-realistic, we employ the use of novel generative adversarial techniques. GarmentGAN improves on existing methods in the realism of generated imagery and solves various problems related to self-occlusions. Our proposed model incorporates additional information during training, utilizing both segmentation maps and body key-point information. We show qualitative and quantitative comparisons to several other networks to demonstrate the effectiveness of this technique.