 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Conditionality for Natural Language Generation
Paper and Code
Sep 02, 2021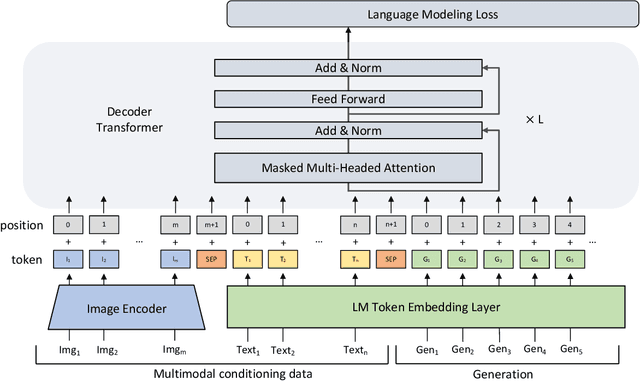

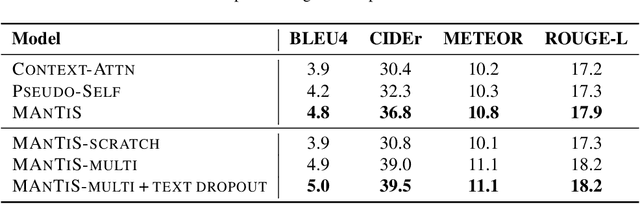

Large scale pretrained language models have demonstrated state-of-the-art performance in language understanding tasks. Their application has recently expanded into multimodality learning, leading to improved representations combining vision and language. However, progress in adapting language models towards conditional Natural Language Generation (NLG) has been limited to a single modality, generally text. We propose MAnTiS, Multimodal Adaptation for Text Synthesis, a general approach for multimodal conditionality in transformer-based NLG models. In this method, we pass inputs from each modality through modality-specific encoders, project to textual token space, and finally join to form a conditionality prefix. We fine-tune the pretrained language model and encoders with the conditionality prefix guiding the generation. We apply MAnTiS to the task of product description generation, conditioning a network on both product images and titles to generate descriptive text. We demonstrate that MAnTiS outperforms strong baseline approaches on standard NLG scoring metrics. Furthermore, qualitative assessments demonstrate that MAnTiS can generate human quality descriptions consistent with given multimodal inputs.