 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXFBoost: Improving Text Generation with Controllable Decoders
Paper and Code
Feb 16, 2022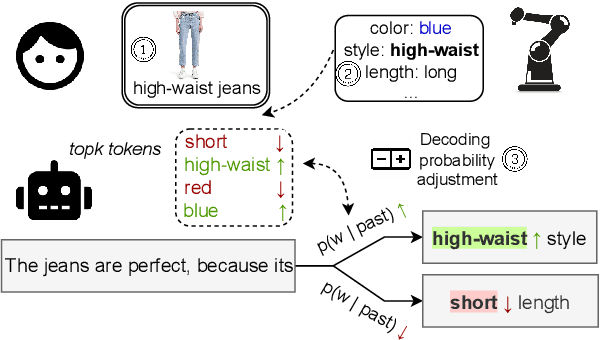
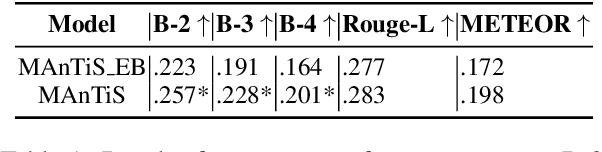


Multimodal conditionality in transformer-based natural language models has demonstrated state-of-the-art performance in the task of product description generation. Recent approaches condition a language model on one or more images and other textual metadata to achieve near-human performance for describing products from e-commerce stores. However, generated descriptions may exhibit degrees of inaccuracy or even contradictory claims relative to the inputs of a given product. In this paper, we propose a controllable language generation framework called Extract-Finetune-Boost (XFBoost), which addresses the problem of inaccurate low-quality inference. By using visual semantic attributes as constraints at the decoding stage of the generation process and finetuning the language model with policy gradient techniques, the XFBoost framework is found to produce significantly more descriptive text with higher image relevancy, outperforming baselines and lowering the frequency of factually inaccurate descriptions. We further demonstrate the application of XFBoost to online learning wherein human-in-the-loop critics improve language models with active feedback.