 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Based Whole-Heart Cardiac Flow Simulations in Health and Congenital Heart Disease
May 10, 2026Intracardiac flow patterns are shaped by the coupled motion of the cardiac chambers and heart valves and provide important information about cardiac function. However, clinical flow imaging remains limited by exam times, noise, resolution, and incomplete details of the three-dimensional flow. Computational fluid dynamics (CFD) can potentially provide detailed flow quantification and predictive insight into treatment outcomes, but clinical translation requires frameworks that reproduce patient-specific measurements while balancing physiological realism, computational cost, and modeling effort. Herein, we present an image-based, patient-specific computational framework for simulating whole-heart intracardiac hemodynamics that balances physiological fidelity with computational efficiency. The framework first employs machine learning-based segmentation and mesh propagation to reconstruct moving cardiac anatomies from time-resolved images. CFD simulations are then performed to resolve blood flow in deforming domains, while resistive immersed surfaces (RIS) are used to model all four cardiac valves with physiologically realistic opening and closing dynamics. The framework was applied to model hemodynamics in a healthy adult and a pediatric patient with complex congenital heart disease (CHD). In the healthy case, the simulations reproduced physiologic pressure-volume behavior, valve timing, and ventricular vortex formation. In the CHD case, simulated chamber and vessel pressures showed agreement with cardiac catheterization measurements. Simulated flow fields were qualitatively consistent with 4D-Flow MRI, while providing higher-resolution visualization of flow structures that were partially obscured by imaging artifacts. Comparison between the healthy and CHD cases further revealed altered diastolic flow organization and elevated normalized viscous dissipation in the CHD heart.
Emergent World Beliefs: Exploring Transformers in Stochastic Games
Dec 18, 2025Transformer-based large language models (LLMs) have demonstrated strong reasoning abilities across diverse fields, from solving programming challenges to competing in strategy-intensive games such as chess. Prior work has shown that LLMs can develop emergent world models in games of perfect information, where internal representations correspond to latent states of the environment. In this paper, we extend this line of investigation to domains of incomplete information, focusing on poker as a canonical partially observable Markov decision process (POMDP). We pretrain a GPT-style model on Poker Hand History (PHH) data and probe its internal activations. Our results demonstrate that the model learns both deterministic structure, such as hand ranks, and stochastic features, such as equity, without explicit instruction. Furthermore, by using primarily nonlinear probes, we demonstrated that these representations are decodeable and correlate with theoretical belief states, suggesting that LLMs are learning their own representation of the stochastic environment of Texas Hold'em Poker.
SDF4CHD: Generative Modeling of Cardiac Anatomies with Congenital Heart Defects
Nov 08, 2023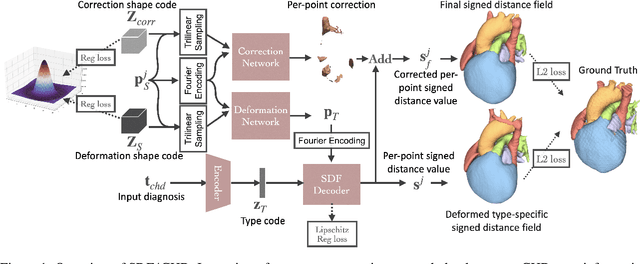

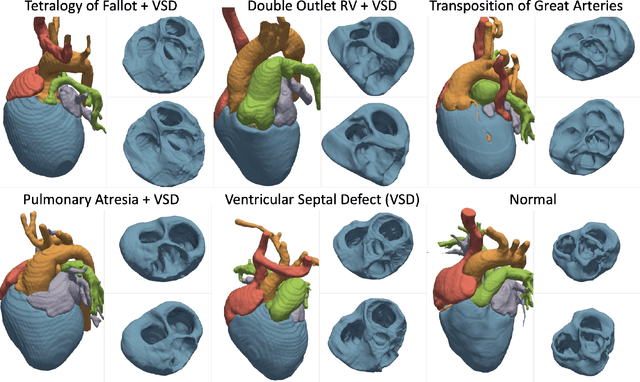

Congenital heart disease (CHD) encompasses a spectrum of cardiovascular structural abnormalities, often requiring customized treatment plans for individual patients. Computational modeling and analysis of these unique cardiac anatomies can improve diagnosis and treatment planning and may ultimately lead to improved outcomes. Deep learning (DL) methods have demonstrated the potential to enable efficient treatment planning by automating cardiac segmentation and mesh construction for patients with normal cardiac anatomies. However, CHDs are often rare, making it challenging to acquire sufficiently large patient cohorts for training such DL models. Generative modeling of cardiac anatomies has the potential to fill this gap via the generation of virtual cohorts; however, prior approaches were largely designed for normal anatomies and cannot readily capture the significant topological variations seen in CHD patients. Therefore, we propose a type- and shape-disentangled generative approach suitable to capture the wide spectrum of cardiac anatomies observed in different CHD types and synthesize differently shaped cardiac anatomies that preserve the unique topology for specific CHD types. Our DL approach represents generic whole heart anatomies with CHD type-specific abnormalities implicitly using signed distance fields (SDF) based on CHD type diagnosis, which conveniently captures divergent anatomical variations across different types and represents meaningful intermediate CHD states. To capture the shape-specific variations, we then learn invertible deformations to morph the learned CHD type-specific anatomies and reconstruct patient-specific shapes. Our approach has the potential to augment the image-segmentation pairs for rarer CHD types for cardiac segmentation and generate cohorts of CHD cardiac meshes for computational simulation.
Robust Visual Tracking by Motion Analyzing
Sep 06, 2023



In recent years, Video Object Segmentation (VOS) has emerged as a complementary method to Video Object Tracking (VOT). VOS focuses on classifying all the pixels around the target, allowing for precise shape labeling, while VOT primarily focuses on the approximate region where the target might be. However, traditional segmentation modules usually classify pixels frame by frame, disregarding information between adjacent frames. In this paper, we propose a new algorithm that addresses this limitation by analyzing the motion pattern using the inherent tensor structure. The tensor structure, obtained through Tucker2 tensor decomposition, proves to be effective in describing the target's motion. By incorporating this information, we achieved competitive results on Four benchmarks LaSOT\cite{fan2019lasot}, AVisT\cite{noman2022avist}, OTB100\cite{7001050}, and GOT-10k\cite{huang2019got} LaSOT\cite{fan2019lasot} with SOTA. Furthermore, the proposed tracker is capable of real-time operation, adding value to its practical application.
Semi-Supervised Learning with Multiple Imputations on Non-Random Missing Labels
Aug 15, 2023



Semi-Supervised Learning (SSL) is implemented when algorithms are trained on both labeled and unlabeled data. This is a very common application of ML as it is unrealistic to obtain a fully labeled dataset. Researchers have tackled three main issues: missing at random (MAR), missing completely at random (MCAR), and missing not at random (MNAR). The MNAR problem is the most challenging of the three as one cannot safely assume that all class distributions are equal. Existing methods, including Class-Aware Imputation (CAI) and Class-Aware Propensity (CAP), mostly overlook the non-randomness in the unlabeled data. This paper proposes two new methods of combining multiple imputation models to achieve higher accuracy and less bias. 1) We use multiple imputation models, create confidence intervals, and apply a threshold to ignore pseudo-labels with low confidence. 2) Our new method, SSL with De-biased Imputations (SSL-DI), aims to reduce bias by filtering out inaccurate data and finding a subset that is accurate and reliable. This subset of the larger dataset could be imputed into another SSL model, which will be less biased. The proposed models have been shown to be effective in both MCAR and MNAR situations, and experimental results show that our methodology outperforms existing methods in terms of classification accuracy and reducing bias.