 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Spectral GNNs Are Neither Spectral Nor Superior for Node Classification
Mar 19, 2026Spectral Graph Neural Networks (Spectral GNNs) for node classification promise frequency-domain filtering on graphs, yet rest on flawed foundations. Recent work shows that graph Laplacian eigenvectors do not in general have the key properties of a true Fourier basis, but leaves the empirical success of Spectral GNNs unexplained. We identify two theoretical glitches: (1) commonly used "graph Fourier bases" are not classical Fourier bases for graph signals; (2) (n-1)-degree polynomials (n = number of nodes) can exactly interpolate any spectral response via a Vandermonde system, so the usual "polynomial approximation" narrative is not theoretically justified. The effectiveness of GCN is commonly attributed to spectral low-pass filtering, yet we prove that low- and high-pass behaviors arise solely from message-passing dynamics rather than Graph Fourier Transform-based spectral formulations. We then analyze two representative directed spectral models, MagNet and HoloNet. Their reported effectiveness is not spectral: it arises from implementation issues that reduce them to powerful MPNNs. When implemented consistently with the claimed spectral algorithms, performance becomes weak. This position paper argues that: for node classification, Spectral GNNs neither meaningfully capture the graph spectrum nor reliably improve performance; competitive results are better explained by their equivalence to MPNNs, sometimes aided by implementations inconsistent with their intended design.
A Comparative Analysis of Transformer Models in Social Bot Detection
Sep 18, 2025Social media has become a key medium of communication in today's society. This realisation has led to many parties employing artificial users (or bots) to mislead others into believing untruths or acting in a beneficial manner to such parties. Sophisticated text generation tools, such as large language models, have further exacerbated this issue. This paper aims to compare the effectiveness of bot detection models based on encoder and decoder transformers. Pipelines are developed to evaluate the performance of these classifiers, revealing that encoder-based classifiers demonstrate greater accuracy and robustness. However, decoder-based models showed greater adaptability through task-specific alignment, suggesting more potential for generalisation across different use cases in addition to superior observa. These findings contribute to the ongoing effort to prevent digital environments being manipulated while protecting the integrity of online discussion.
Scale Invariance of Graph Neural Networks
Nov 28, 2024



We address two fundamental challenges in Graph Neural Networks (GNNs): (1) the lack of theoretical support for invariance learning, a critical property in image processing, and (2) the absence of a unified model capable of excelling on both homophilic and heterophilic graph datasets. To tackle these issues, we establish and prove scale invariance in graphs, extending this key property to graph learning, and validate it through experiments on real-world datasets. Leveraging directed multi-scaled graphs and an adaptive self-loop strategy, we propose ScaleNet, a unified network architecture that achieves state-of-the-art performance across four homophilic and two heterophilic benchmark datasets. Furthermore, we show that through graph transformation based on scale invariance, uniform weights can replace computationally expensive edge weights in digraph inception networks while maintaining or improving performance. For another popular GNN approach to digraphs, we demonstrate the equivalence between Hermitian Laplacian methods and GraphSAGE with incidence normalization. ScaleNet bridges the gap between homophilic and heterophilic graph learning, offering both theoretical insights into scale invariance and practical advancements in unified graph learning. Our implementation is publicly available at https://github.com/Qin87/ScaleNet/tree/Aug23.
ScaleNet: Scale Invariance Learning in Directed Graphs
Nov 13, 2024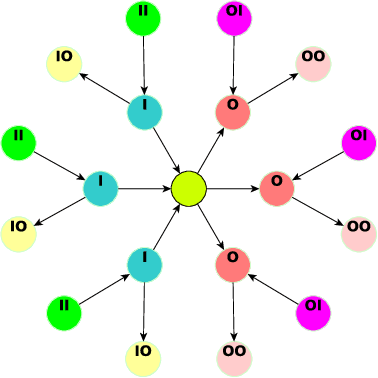
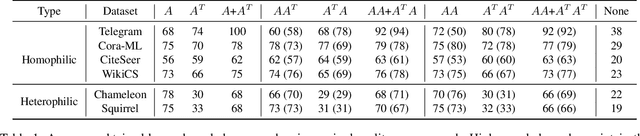
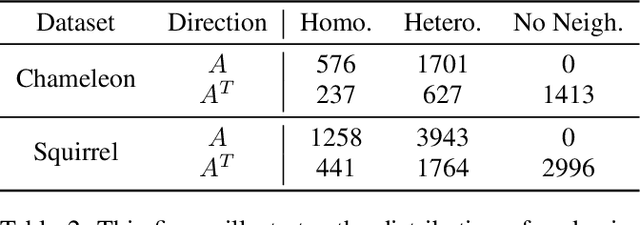
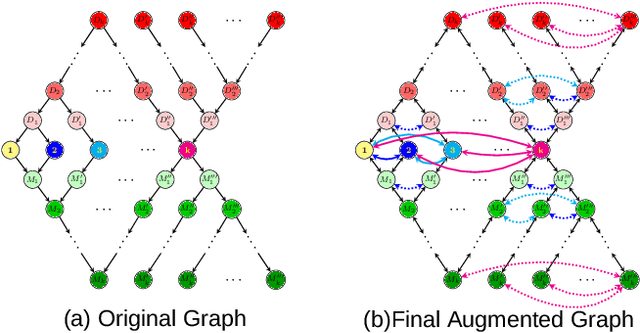
Graph Neural Networks (GNNs) have advanced relational data analysis but lack invariance learning techniques common in image classification. In node classification with GNNs, it is actually the ego-graph of the center node that is classified. This research extends the scale invariance concept to node classification by drawing an analogy to image processing: just as scale invariance being used in image classification to capture multi-scale features, we propose the concept of ``scaled ego-graphs''. Scaled ego-graphs generalize traditional ego-graphs by replacing undirected single-edges with ``scaled-edges'', which are ordered sequences of multiple directed edges. We empirically assess the performance of the proposed scale invariance in graphs on seven benchmark datasets, across both homophilic and heterophilic structures. Our scale-invariance-based graph learning outperforms inception models derived from random walks by being simpler, faster, and more accurate. The scale invariance explains inception models' success on homophilic graphs and limitations on heterophilic graphs. To ensure applicability of inception model to heterophilic graphs as well, we further present ScaleNet, an architecture that leverages multi-scaled features. ScaleNet achieves state-of-the-art results on five out of seven datasets (four homophilic and one heterophilic) and matches top performance on the remaining two, demonstrating its excellent applicability. This represents a significant advance in graph learning, offering a unified framework that enhances node classification across various graph types. Our code is available at https://github.com/Qin87/ScaleNet/tree/July25.
Optimising Optimisers with Push GP
Oct 02, 2019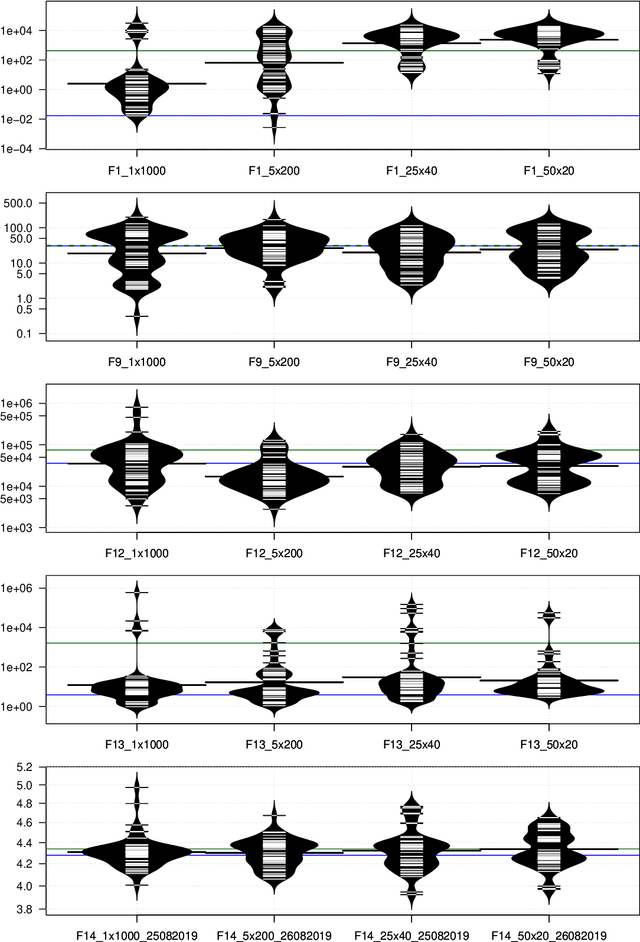
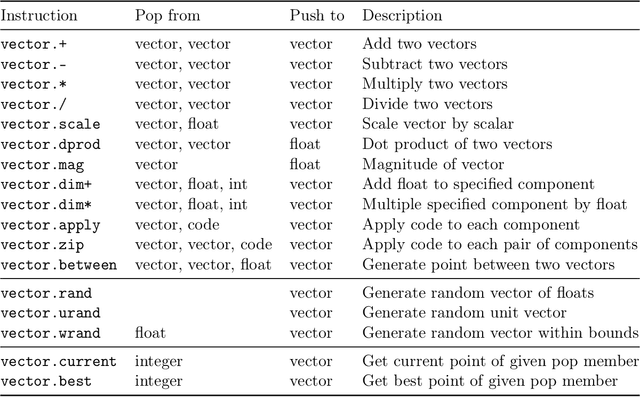
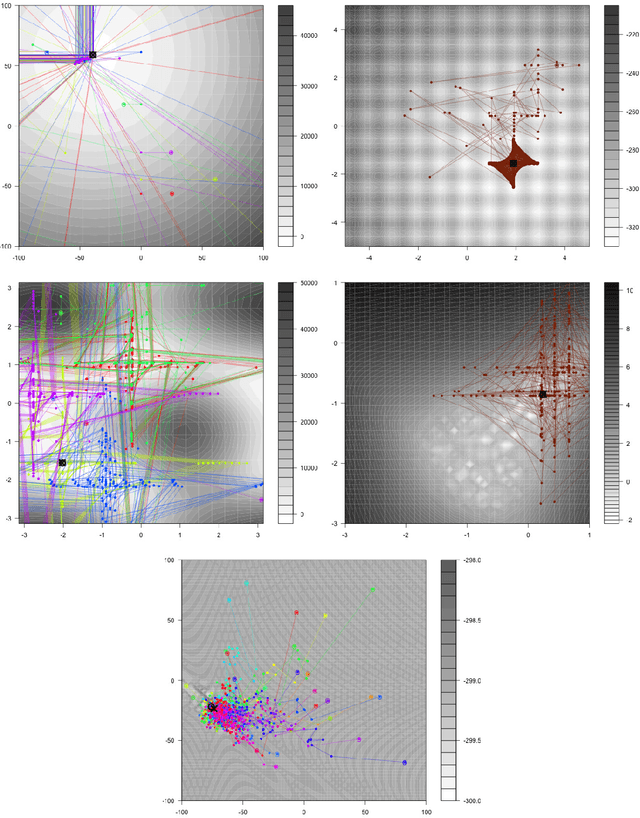
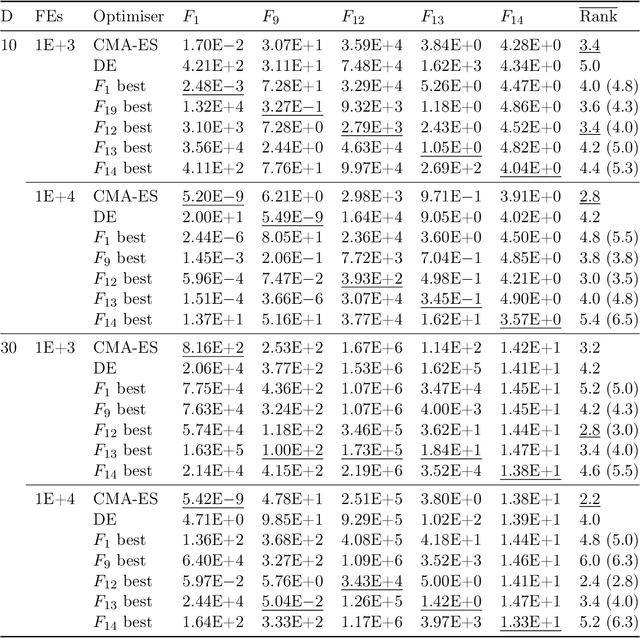
This work uses Push GP to automatically design both local and population-based optimisers for continuous-valued problems. The optimisers are trained on a single function optimisation landscape, using random transformations to discourage overfitting. They are then tested for generality on larger versions of the same problem, and on other continuous-valued problems. In most cases, the optimisers generalise well to the larger problems. Surprisingly, some of them also generalise very well to previously unseen problems, outperforming existing general purpose optimisers such as CMA-ES. Analysis of the behaviour of the evolved optimisers indicates a range of interesting optimisation strategies that are not found within conventional optimisers, suggesting that this approach could be useful for discovering novel and effective forms of optimisation in an automated manner.
Instruction-Level Design of Local Optimisers using Push GP
May 24, 2019



This work uses genetic programming to explore the design space of local optimisation algorithms. Optimisers are expressed in the Push programming language, a stack-based language with a wide range of typed primitive instructions. The evolutionary framework provides the evolving optimisers with an outer loop and information about whether a solution has improved, but otherwise they are relatively unconstrained in how they explore optimisation landscapes. To test the utility of this approach, optimisers were evolved on four different types of continuous landscape, and the search behaviours of the evolved optimisers analysed. By making use of mathematical functions such as tangents and logarithms to explore different neighbourhoods, and also by learning features of the landscapes, it was observed that the evolved optimisers were often able to reach the optima using relatively short paths.