 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Melanocytic Cell Masks from Adjacent Stained Tissue
Nov 01, 2022Melanoma is one of the most aggressive forms of skin cancer, causing a large proportion of skin cancer deaths. However, melanoma diagnoses by pathologists shows low interrater reliability. As melanoma is a cancer of the melanocyte, there is a clear need to develop a melanocytic cell segmentation tool that is agnostic to pathologist variability and automates pixel-level annotation. Gigapixel-level pathologist labeling, however, is impractical. Herein, we propose a means to train deep neural networks for melanocytic cell segmentation from hematoxylin and eosin (H&E) stained slides using paired immunohistochemical (IHC) slides of adjacent tissue sections, achieving a mean IOU of 0.64 despite imperfect ground-truth labels.
A single-cell gene expression language model
Oct 25, 2022Gene regulation is a dynamic process that connects genotype and phenotype. Given the difficulty of physically mapping mammalian gene circuitry, we require new computational methods to learn regulatory rules. Natural language is a valuable analogy to the communication of regulatory control. Machine learning systems model natural language by explicitly learning context dependencies between words. We propose a similar system applied to single-cell RNA expression profiles to learn context dependencies between genes. Our model, Exceiver, is trained across a diversity of cell types using a self-supervised task formulated for discrete count data, accounting for feature sparsity. We found agreement between the similarity profiles of latent sample representations and learned gene embeddings with respect to biological annotations. We evaluated Exceiver on a new dataset and a downstream prediction task and found that pretraining supports transfer learning. Our work provides a framework to model gene regulation on a single-cell level and transfer knowledge to downstream tasks.
Robust Semantic Interpretability: Revisiting Concept Activation Vectors
Apr 06, 2021



Interpretability methods for image classification assess model trustworthiness by attempting to expose whether the model is systematically biased or attending to the same cues as a human would. Saliency methods for feature attribution dominate the interpretability literature, but these methods do not address semantic concepts such as the textures, colors, or genders of objects within an image. Our proposed Robust Concept Activation Vectors (RCAV) quantifies the effects of semantic concepts on individual model predictions and on model behavior as a whole. RCAV calculates a concept gradient and takes a gradient ascent step to assess model sensitivity to the given concept. By generalizing previous work on concept activation vectors to account for model non-linearity, and by introducing stricter hypothesis testing, we show that RCAV yields interpretations which are both more accurate at the image level and robust at the dataset level. RCAV, like saliency methods, supports the interpretation of individual predictions. To evaluate the practical use of interpretability methods as debugging tools, and the scientific use of interpretability methods for identifying inductive biases (e.g. texture over shape), we construct two datasets and accompanying metrics for realistic benchmarking of semantic interpretability methods. Our benchmarks expose the importance of counterfactual augmentation and negative controls for quantifying the practical usability of interpretability methods.
Attention-Based Learning on Molecular Ensembles
Nov 25, 2020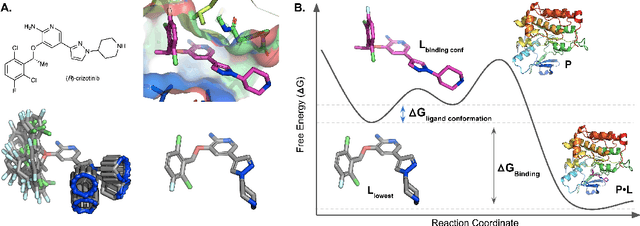
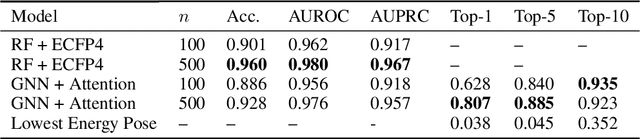
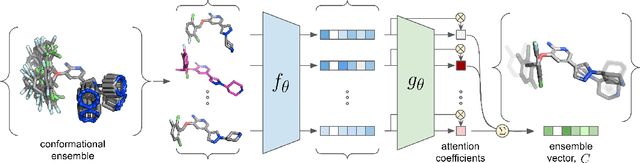
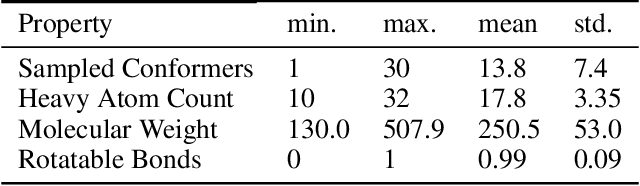
The three-dimensional shape and conformation of small-molecule ligands are critical for biomolecular recognition, yet encoding 3D geometry has not improved ligand-based virtual screening approaches. We describe an end-to-end deep learning approach that operates directly on small-molecule conformational ensembles and identifies key conformational poses of small-molecules. Our networks leverage two levels of representation learning: 1) individual conformers are first encoded as spatial graphs using a graph neural network, and 2) sampled conformational ensembles are represented as sets using an attention mechanism to aggregate over individual instances. We demonstrate the feasibility of this approach on a simple task based on bidentate coordination of biaryl ligands, and show how attention-based pooling can elucidate key conformational poses in tasks based on molecular geometry. This work illustrates how set-based learning approaches may be further developed for small molecule-based virtual screening.
Global Saliency: Aggregating Saliency Maps to Assess Dataset Artefact Bias
Oct 16, 2019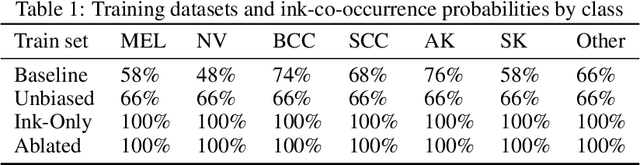



In high-stakes applications of machine learning models, interpretability methods provide guarantees that models are right for the right reasons. In medical imaging, saliency maps have become the standard tool for determining whether a neural model has learned relevant robust features, rather than artefactual noise. However, saliency maps are limited to local model explanation because they interpret predictions on an image-by-image basis. We propose aggregating saliency globally, using semantic segmentation masks, to provide quantitative measures of model bias across a dataset. To evaluate global saliency methods, we propose two metrics for quantifying the validity of saliency explanations. We apply the global saliency method to skin lesion diagnosis to determine the effect of artefacts, such as ink, on model bias.