 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Flow Variational Autoencoders for Structured Sequence Prediction
Aug 24, 2019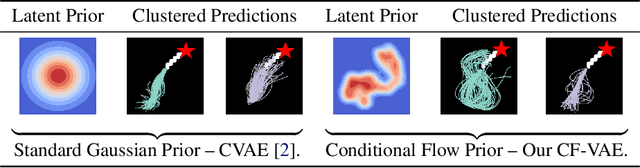



Prediction of future states of the environment and interacting agents is a key competence required for autonomous agents to operate successfully in the real world. Prior work for structured sequence prediction based on latent variable models imposes a uni-modal standard Gaussian prior on the latent variables. This induces a strong model bias which makes it challenging to fully capture the multi-modality of the distribution of the future states. In this work, we introduce Conditional Flow Variational Autoencoders which uses our novel conditional normalizing flow based prior. We show that using our novel complex multi-modal conditional prior we can capture complex multi-modal conditional distributions. Furthermore, we study for the first time latent variable collapse with normalizing flows and propose solutions to prevent such failure cases. Our experiments on three multi-modal structured sequence prediction datasets -- MNIST Sequences, Stanford Drone and HighD -- show that the proposed method obtains state of art results across different evaluation metrics.