 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Image Content Extraction: Operationalizing Machine Learning in Humanistic Photographic Studies of Large Visual Archives
Apr 05, 2022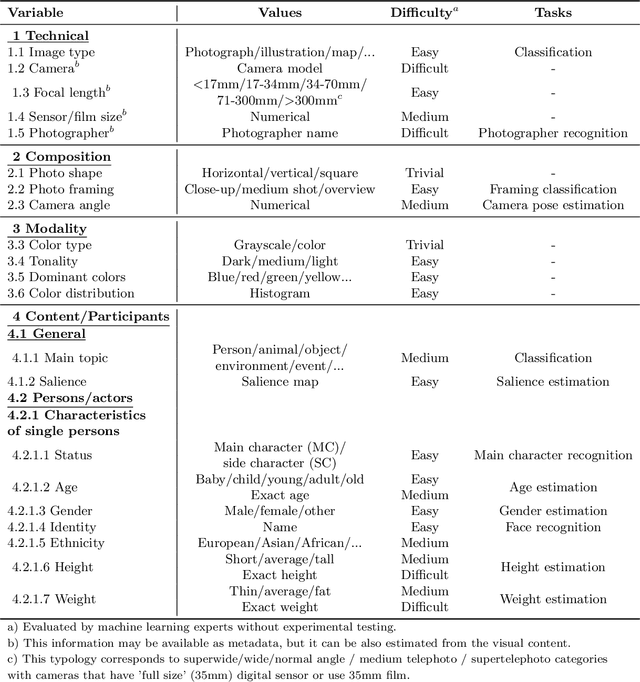
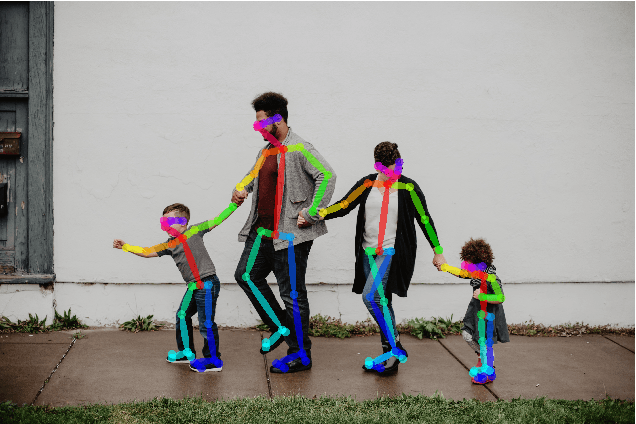
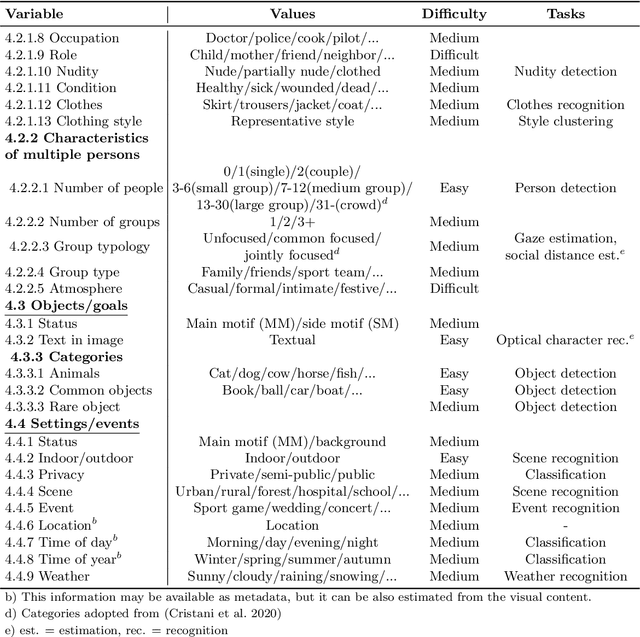

Applying machine learning tools to digitized image archives has a potential to revolutionize quantitative research of visual studies in humanities and social sciences. The ability to process a hundredfold greater number of photos than has been traditionally possible and to analyze them with an extensive set of variables will contribute to deeper insight into the material. Overall, these changes will help to shift the workflow from simple manual tasks to more demanding stages. In this paper, we introduce Automatic Image Content Extraction (AICE) framework for machine learning-based search and analysis of large image archives. We developed the framework in a multidisciplinary research project as framework for future photographic studies by reformulating and expanding the traditional visual content analysis methodologies to be compatible with the current and emerging state-of-the-art machine learning tools and to cover the novel machine learning opportunities for automatic content analysis. The proposed framework can be applied in several domains in humanities and social sciences, and it can be adjusted and scaled into various research settings. We also provide information on the current state of different machine learning techniques and show that there are already various publicly available methods that are suitable to a wide-scale of visual content analysis tasks.
Automatic Main Character Recognition for Photographic Studies
Jun 16, 2021



Main characters in images are the most important humans that catch the viewer's attention upon first look, and they are emphasized by properties such as size, position, color saturation, and sharpness of focus. Identifying the main character in images plays an important role in traditional photographic studies and media analysis, but the task is performed manually and can be slow and laborious. Furthermore, selection of main characters can be sometimes subjective. In this paper, we analyze the feasibility of solving the main character recognition needed for photographic studies automatically and propose a method for identifying the main characters. The proposed method uses machine learning based human pose estimation along with traditional computer vision approaches for this task. We approach the task as a binary classification problem where each detected human is classified either as a main character or not. To evaluate both the subjectivity of the task and the performance of our method, we collected a dataset of 300 varying images from multiple sources and asked five people, a photographic researcher and four other persons, to annotate the main characters. Our analysis showed a relatively high agreement between different annotators. The proposed method achieved a promising F1 score of 0.83 on the full image set and 0.96 on a subset evaluated as most clear and important cases by the photographic researcher.
Automatic Social Distance Estimation From Images: Performance Evaluation, Test Benchmark, and Algorithm
Mar 11, 2021

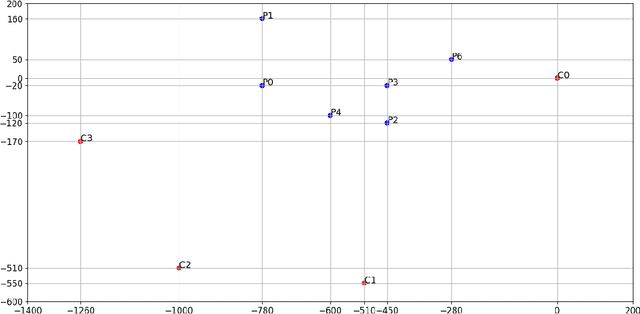

The COVID-19 virus has caused a global pandemic since March 2020. The World Health Organization (WHO) has provided guidelines on how to reduce the spread of the virus and one of the most important measures is social distancing. Maintaining a minimum of one meter distance from other people is strongly suggested to reduce the risk of infection. This has created a strong interest in monitoring the social distances either as a safety measure or to study how the measures have affected human behavior and country-wise differences in this. The need for automatic social distance estimation algorithms is evident, but there is no suitable test benchmark for such algorithms. Collecting images with measured ground-truth pair-wise distances between all the people using different camera settings is cumbersome. Furthermore, performance evaluation for social distance estimation algorithms is not straightforward and there is no widely accepted evaluation protocol. In this paper, we provide a dataset of varying images with measured pair-wise social distances under different camera positionings and focal length values. We suggest a performance evaluation protocol and provide a benchmark to easily evaluate social distance estimation algorithms. We also propose a method for automatic social distance estimation. Our method takes advantage of object detection and human pose estimation. It can be applied on any single image as long as focal length and sensor size information are known. The results on our benchmark are encouraging with 92% human detection rate and only 28.9% average error in distance estimation among the detected people.
Single Image Super-Resolution
Jan 08, 2021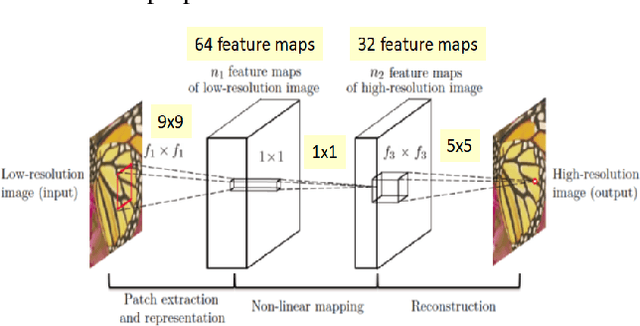
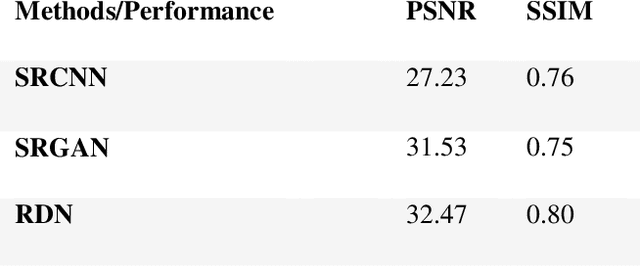
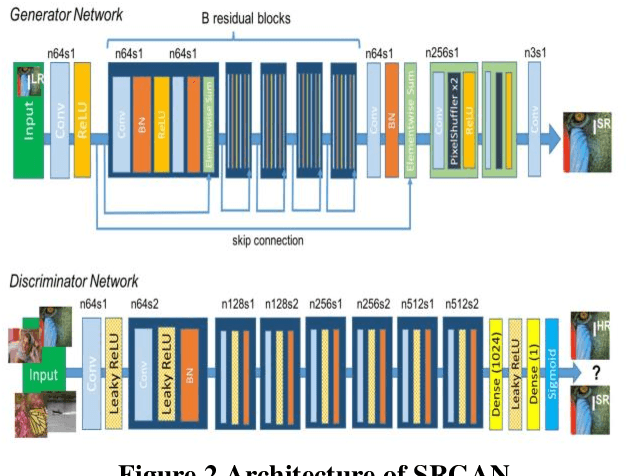

This study presents a chronological overview of the single image super-resolution problem. We first define the problem thoroughly and mention some of the serious challenges. Then the problem formulation and the performance metrics are defined. We give an overview of the previous methods relying on reconstruction based solutions and then continue with the deep learning approaches. We pick 3 landmark architectures and present their results quantitatively. We see that the latest proposed network gives favorable output compared to the previous methods.