 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Image Content Extraction: Operationalizing Machine Learning in Humanistic Photographic Studies of Large Visual Archives
Paper and Code
Apr 05, 2022
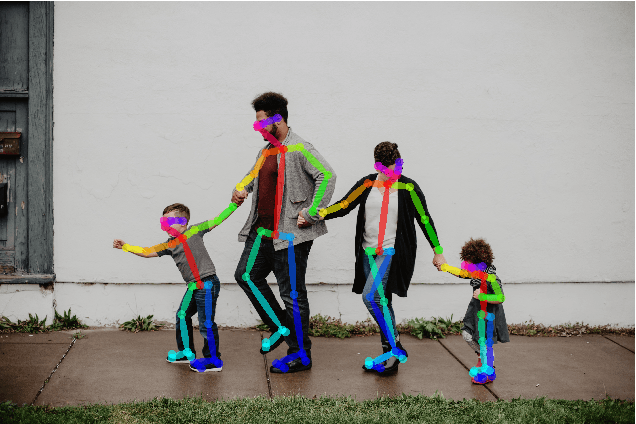

Applying machine learning tools to digitized image archives has a potential to revolutionize quantitative research of visual studies in humanities and social sciences. The ability to process a hundredfold greater number of photos than has been traditionally possible and to analyze them with an extensive set of variables will contribute to deeper insight into the material. Overall, these changes will help to shift the workflow from simple manual tasks to more demanding stages. In this paper, we introduce Automatic Image Content Extraction (AICE) framework for machine learning-based search and analysis of large image archives. We developed the framework in a multidisciplinary research project as framework for future photographic studies by reformulating and expanding the traditional visual content analysis methodologies to be compatible with the current and emerging state-of-the-art machine learning tools and to cover the novel machine learning opportunities for automatic content analysis. The proposed framework can be applied in several domains in humanities and social sciences, and it can be adjusted and scaled into various research settings. We also provide information on the current state of different machine learning techniques and show that there are already various publicly available methods that are suitable to a wide-scale of visual content analysis tasks.