 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Vision Transformer for 360-degree Video Saliency Prediction
Aug 24, 2023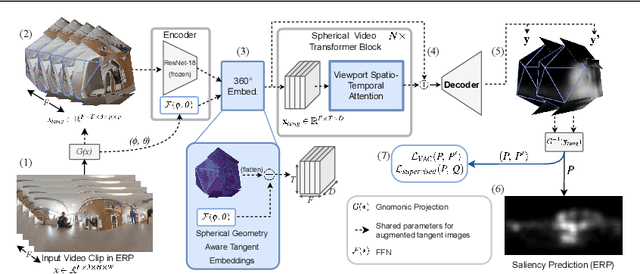
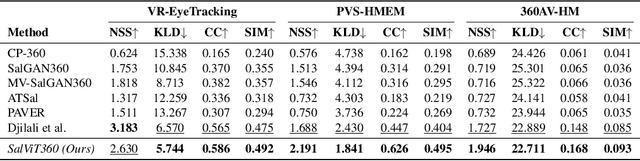
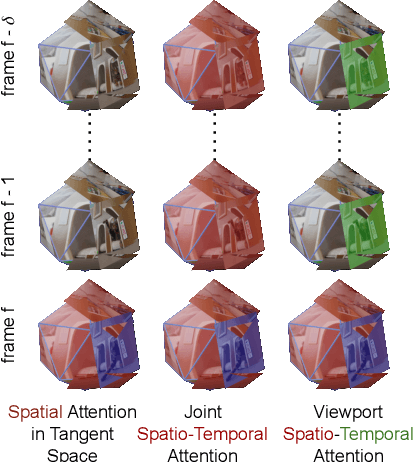
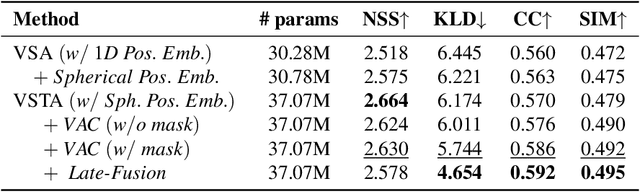
The growing interest in omnidirectional videos (ODVs) that capture the full field-of-view (FOV) has gained 360-degree saliency prediction importance in computer vision. However, predicting where humans look in 360-degree scenes presents unique challenges, including spherical distortion, high resolution, and limited labelled data. We propose a novel vision-transformer-based model for omnidirectional videos named SalViT360 that leverages tangent image representations. We introduce a spherical geometry-aware spatiotemporal self-attention mechanism that is capable of effective omnidirectional video understanding. Furthermore, we present a consistency-based unsupervised regularization term for projection-based 360-degree dense-prediction models to reduce artefacts in the predictions that occur after inverse projection. Our approach is the first to employ tangent images for omnidirectional saliency prediction, and our experimental results on three ODV saliency datasets demonstrate its effectiveness compared to the state-of-the-art.