 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Centric Defense Mechanisms against Adversarial Examples
Oct 26, 2021

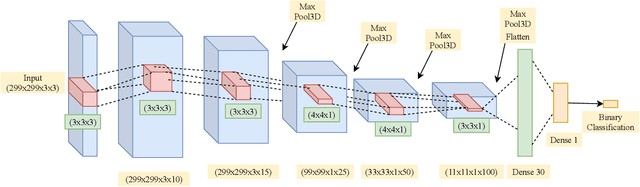
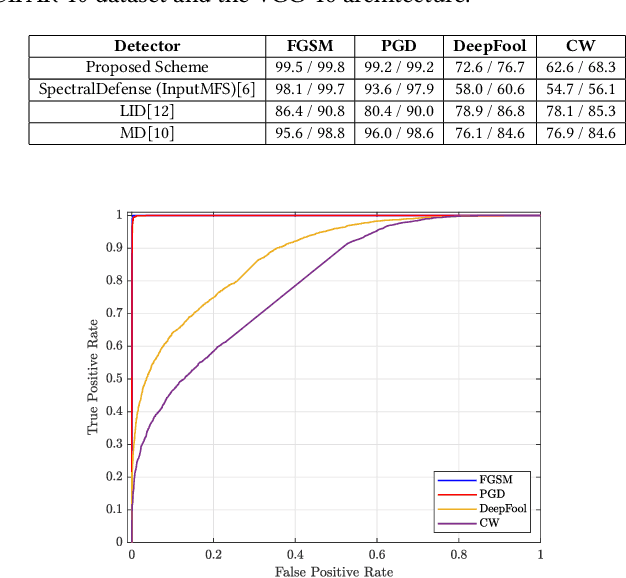
Adversarial example (AE) aims at fooling a Convolution Neural Network by introducing small perturbations in the input image.The proposed work uses the magnitude and phase of the Fourier Spectrum and the entropy of the image to defend against AE. We demonstrate the defense in two ways: by training an adversarial detector and denoising the adversarial effect. Experiments were conducted on the low-resolution CIFAR-10 and high-resolution ImageNet datasets. The adversarial detector has 99% accuracy for FGSM and PGD attacks on the CIFAR-10 dataset. However, the detection accuracy falls to 50% for sophisticated DeepFool and Carlini & Wagner attacks on ImageNet. We overcome the limitation by using autoencoder and show that 70% of AEs are correctly classified after denoising.
Person Retrieval in Surveillance Video using Height, Color and Gender
Sep 24, 2018



A person is commonly described by attributes like height, build, cloth color, cloth type, and gender. Such attributes are known as soft biometrics. They bridge the semantic gap between human description and person retrieval in surveillance video. The paper proposes a deep learning-based linear filtering approach for person retrieval using height, cloth color, and gender. The proposed approach uses Mask R-CNN for pixel-wise person segmentation. It removes background clutter and provides precise boundary around the person. Color and gender models are fine-tuned using AlexNet and the algorithm is tested on SoftBioSearch dataset. It achieves good accuracy for person retrieval using the semantic query in challenging conditions.
ViS-HuD: Using Visual Saliency to Improve Human Detection with Convolutional Neural Networks
Apr 18, 2018



The paper presents a technique to improve human detection in still images using deep learning. Our novel method, ViS-HuD, computes visual saliency map from the image. Then the input image is multiplied by the map and product is fed to the Convolutional Neural Network (CNN) which detects humans in the image. A visual saliency map is generated using ML-Net and human detection is carried out using DetectNet. ML-Net is pre-trained on SALICON while, DetectNet is pre-trained on ImageNet database for visual saliency detection and image classification respectively. The CNNs of ViS-HuD were trained on two challenging databases - Penn Fudan and TUD-Brussels Benchmark. Experimental results demonstrate that the proposed method achieves state-of-the-art performance on Penn Fudan Dataset with 91.4% human detection accuracy and it achieves average miss-rate of 53% on the TUDBrussels benchmark.