 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of YOLO Models with Sliced Inference for Small Object Detection
Mar 09, 2022
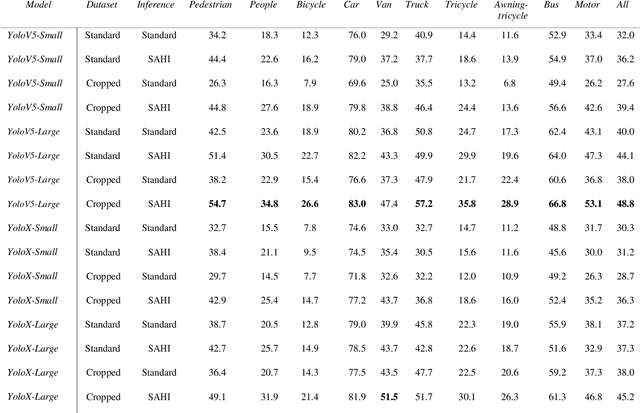
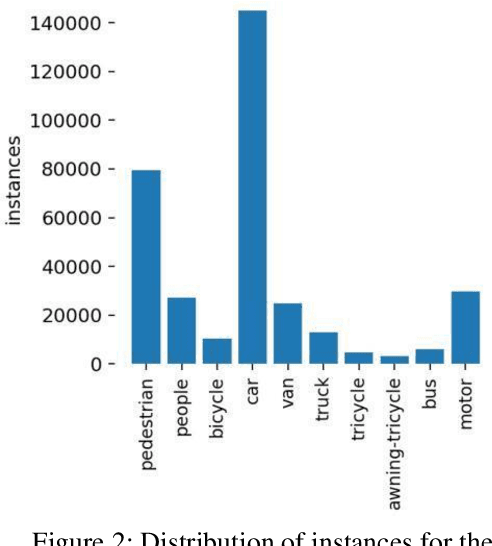

Small object detection has major applications in the fields of UAVs, surveillance, farming and many others. In this work we investigate the performance of state of the art Yolo based object detection models for the task of small object detection as they are one of the most popular and easy to use object detection models. We evaluated YOLOv5 and YOLOX models in this study. We also investigate the effects of slicing aided inference and fine-tuning the model for slicing aided inference. We used the VisDrone2019Det dataset for training and evaluating our models. This dataset is challenging in the sense that most objects are relatively small compared to the image sizes. This work aims to benchmark the YOLOv5 and YOLOX models for small object detection. We have seen that sliced inference increases the AP50 score in all experiments, this effect was greater for the YOLOv5 models compared to the YOLOX models. The effects of sliced fine-tuning and sliced inference combined produced substantial improvement for all models. The highest AP50 score was achieved by the YOLOv5- Large model on the VisDrone2019Det test-dev subset with the score being 48.8.
A new Video Synopsis Based Approach Using Stereo Camera
Jun 23, 2021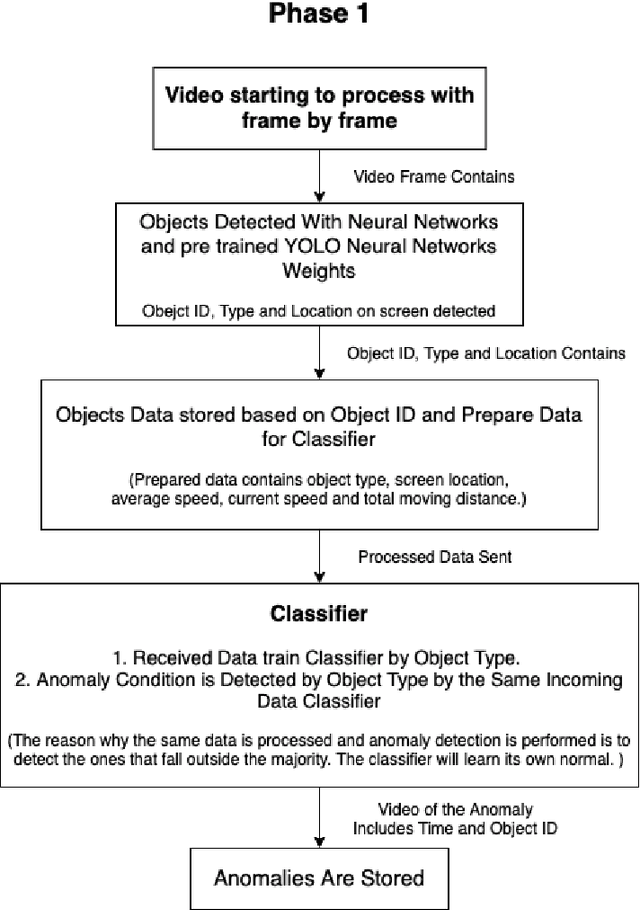
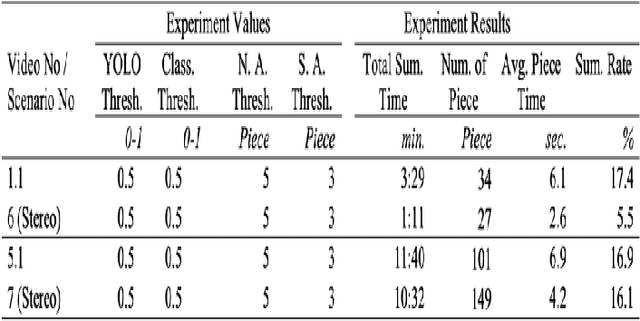
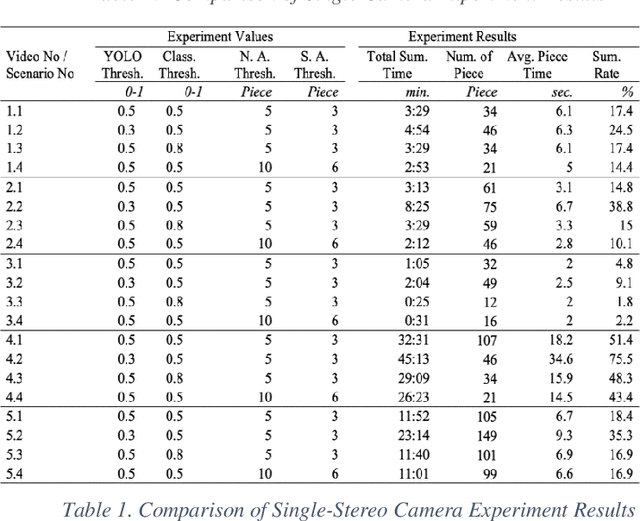
In today's world, the amount of data produced in every field has increased at an unexpected level. In the face of increasing data, the importance of data processing has increased remarkably. Our resource topic is on the processing of video data, which has an important place in increasing data, and the production of summary videos. Within the scope of this resource, a new method for anomaly detection with object-based unsupervised learning has been developed while creating a video summary. By using this method, the video data is processed as pixels and the result is produced as a video segment. The process flow can be briefly summarized as follows. Objects on the video are detected according to their type, and then they are tracked. Then, the tracking history data of the objects are processed, and the classifier is trained with the object type. Thanks to this classifier, anomaly behavior of objects is detected. Video segments are determined by processing video moments containing anomaly behaviors. The video summary is created by extracting the detected video segments from the original video and combining them. The model we developed has been tested and verified separately for single camera and dual camera systems.
Analysis of Interpolation based Image In-painting Approaches
Feb 12, 2021


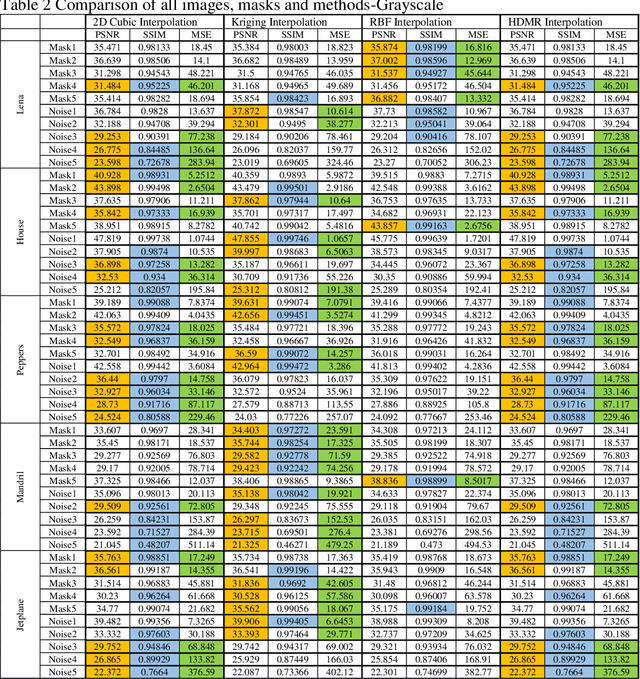
Interpolation and internal painting are one of the basic approaches in image internal painting, which is used to eliminate undesirable parts that occur in digital images or to enhance faulty parts. This study was designed to compare the interpolation algorithms used in image in-painting in the literature. Errors and noise generated on the colour and grayscale formats of some of the commonly used standard images in the literature were corrected by using Cubic, Kriging, Radial based function and High dimensional model representation approaches and the results were compared using standard image comparison criteria, namely, PSNR (peak signal-to-noise ratio), SSIM (Structural SIMilarity), Mean Square Error (MSE). According to the results obtained from the study, the absolute superiority of the methods against each other was not observed. However, Kriging and RBF interpolation give better results both for numerical data and visual evaluation for image in-painting problems with large area losses.
Playing Flappy Bird via Asynchronous Advantage Actor Critic Algorithm
Jul 06, 2019

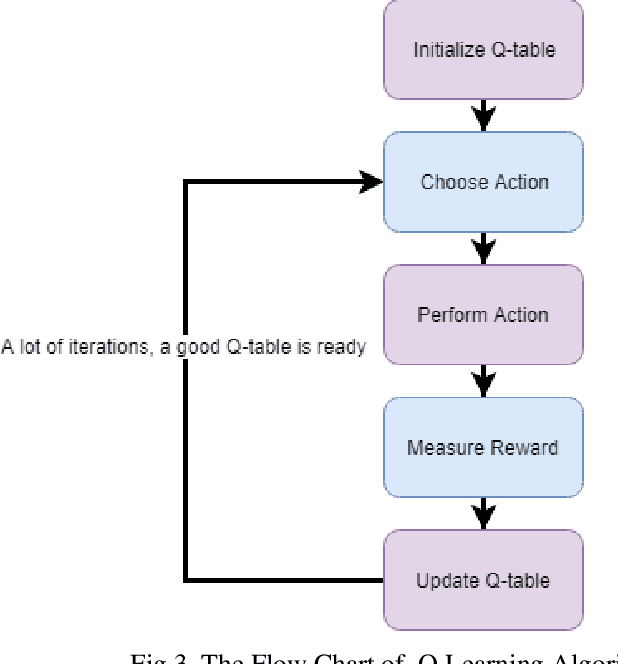

Flappy Bird, which has a very high popularity, has been trained in many algorithms. Some of these studies were trained from raw pixel values of game and some from specific attributes. In this study, the model was trained with raw game images, which had not been seen before. The trained model has learned as reinforcement when to make which decision. As an input to the model, the reward or penalty at the end of each step was returned and the training was completed. Flappy Bird game was trained with the Reinforcement Learning algorithm Deep Q-Network and Asynchronous Advantage Actor Critic (A3C) algorithms.
A Vehicle Detection Approach using Deep Learning Methodologies
Apr 02, 2018
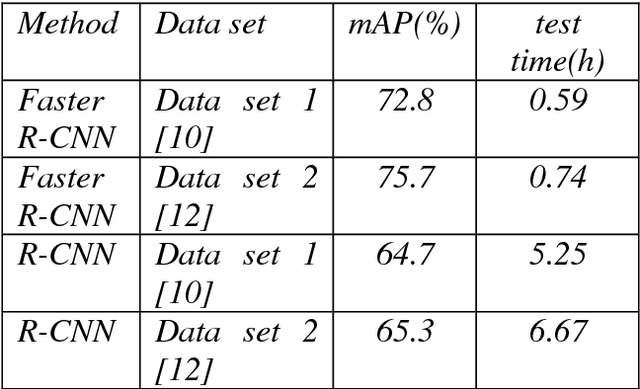

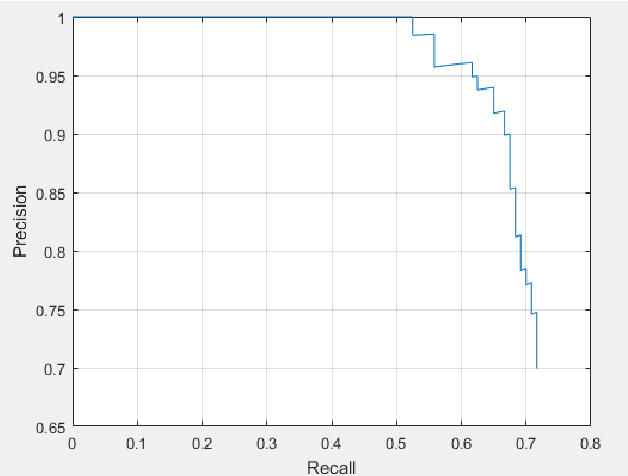
The purpose of this study is to successfully train our vehicle detector using R-CNN, Faster R-CNN deep learning methods on a sample vehicle data sets and to optimize the success rate of the trained detector by providing efficient results for vehicle detection by testing the trained vehicle detector on the test data. The working method consists of six main stages. These are respectively; loading the data set, the design of the convolutional neural network, configuration of training options, training of the Faster R-CNN object detector and evaluation of trained detector. In addition, in the scope of the study, Faster R-CNN, R-CNN deep learning methods were mentioned and experimental analysis comparisons were made with the results obtained from vehicle detection.
Live Target Detection with Deep Learning Neural Network and Unmanned Aerial Vehicle on Android Mobile Device
Mar 22, 2018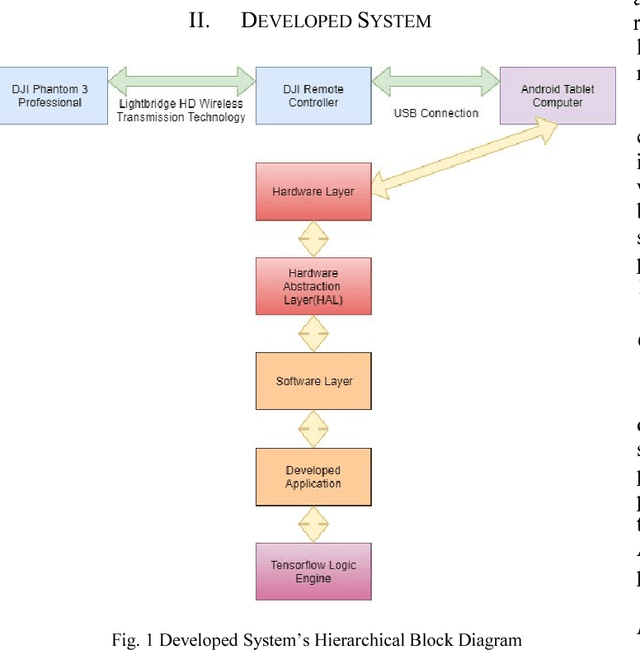

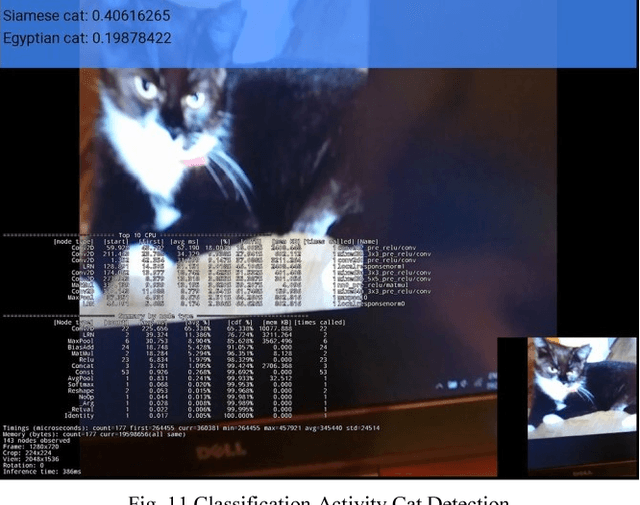
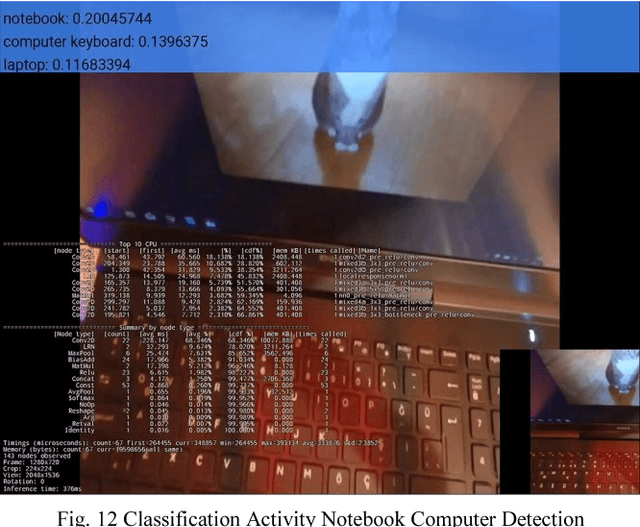
This paper describes the stages faced during the development of an Android program which obtains and decodes live images from DJI Phantom 3 Professional Drone and implements certain features of the TensorFlow Android Camera Demo application. Test runs were made and outputs of the application were noted. A lake was classified as seashore, breakwater and pier with the proximities of 24.44%, 21.16% and 12.96% respectfully. The joystick of the UAV controller and laptop keyboard was classified with the proximities of 19.10% and 13.96% respectfully. The laptop monitor was classified as screen, monitor and television with the proximities of 18.77%, 14.76% and 14.00% respectfully. The computer used during the development of this study was classified as notebook and laptop with the proximities of 20.04% and 11.68% respectfully. A tractor parked at a parking lot was classified with the proximity of 12.88%. A group of cars in the same parking lot were classified as sports car, racer and convertible with the proximities of 31.75%, 18.64% and 13.45% respectfully at an inference time of 851ms.
A Fuzzy Brute Force Matching Method for Binary Image Features
Apr 20, 2017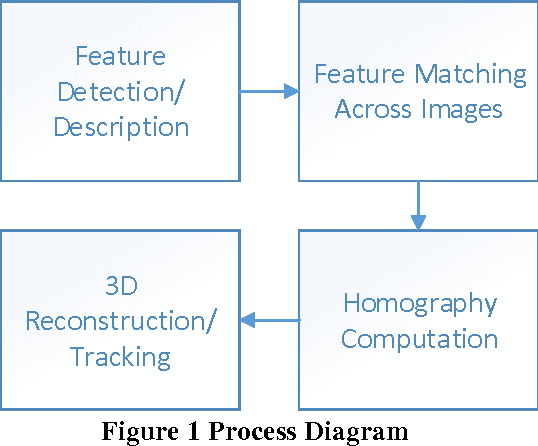
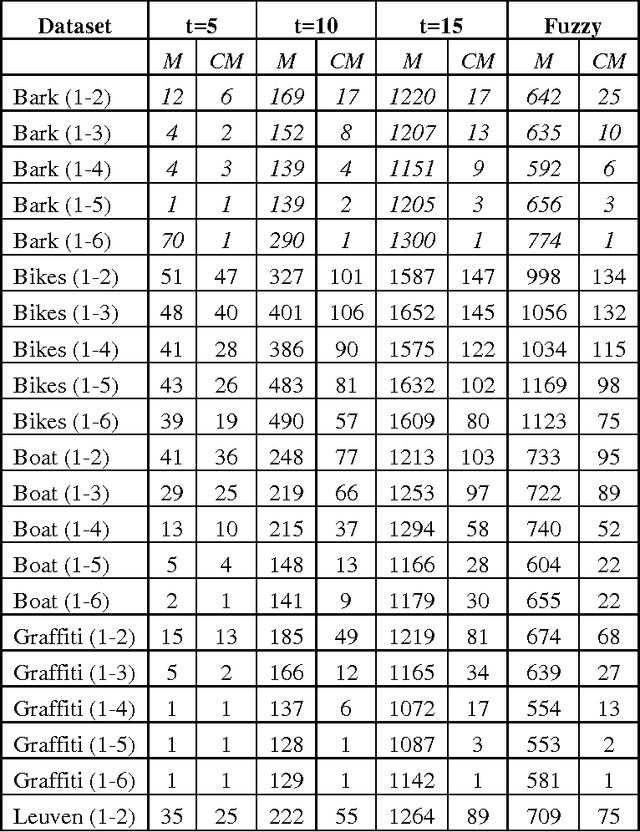
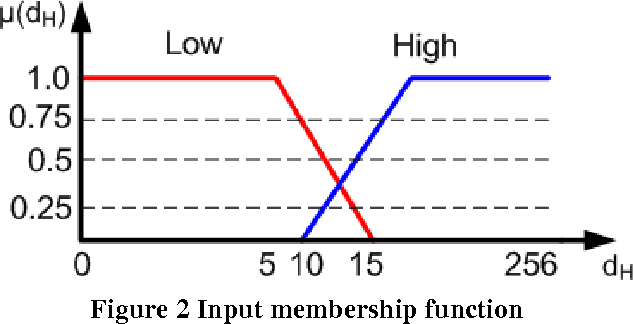
Matching of binary image features is an important step in many different computer vision applications. Conventionally, an arbitrary threshold is used to identify a correct match from incorrect matches using Hamming distance which may improve or degrade the matching results for different input images. This is mainly due to the image content which is affected by the scene, lighting and imaging conditions. This paper presents a fuzzy logic based approach for brute force matching of image features to overcome this situation. The method was tested using a well-known image database with known ground truth. The approach is shown to produce a higher number of correct matches when compared against constant distance thresholds. The nature of fuzzy logic which allows the vagueness of information and tolerance to errors has been successfully exploited in an image processing context. The uncertainty arising from the imaging conditions has been overcome with the use of compact fuzzy matching membership functions.
Genetic Algorithm Based Floor Planning System
Apr 20, 2017
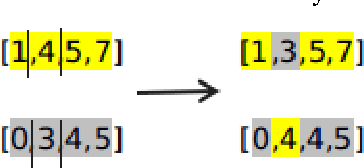

Genetic Algorithms are widely used in many different optimization problems including layout design. The layout of the shelves play an important role in the total sales metrics for superstores since this affects the customers' shopping behaviour. This paper employed a genetic algorithm based approach to design shelf layout of superstores. The layout design problem was tackled by using a novel chromosome representation which takes many different parameters to prevent dead-ends and improve shelf visibility into consideration. Results show that the approach can produce reasonably good layout designs in very short amounts of time.