 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context-Enhanced De-identification System
Feb 17, 2021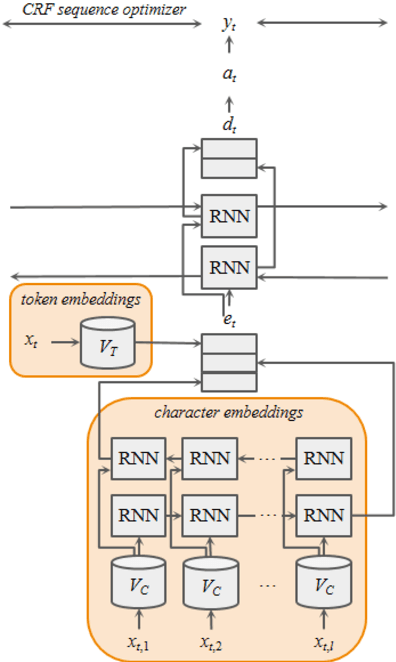
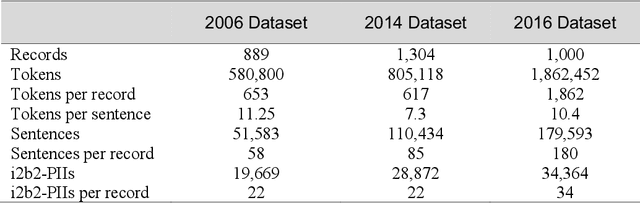
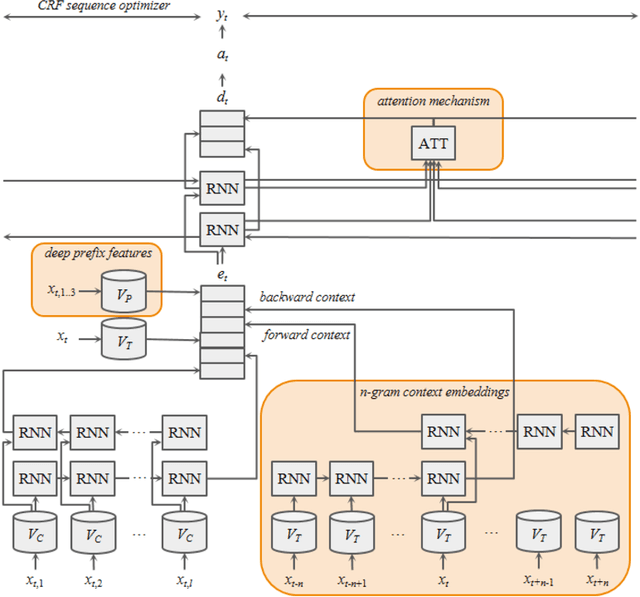
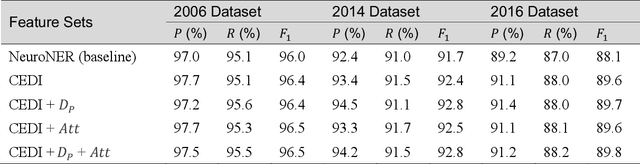
Many modern entity recognition systems, including the current state-of-the-art de-identification systems, are based on bidirectional long short-term memory (biLSTM) units augmented by a conditional random field (CRF) sequence optimizer. These systems process the input sentence by sentence. This approach prevents the systems from capturing dependencies over sentence boundaries and makes accurate sentence boundary detection a prerequisite. Since sentence boundary detection can be problematic especially in clinical reports, where dependencies and co-references across sentence boundaries are abundant, these systems have clear limitations. In this study, we built a new system on the framework of one of the current state-of-the-art de-identification systems, NeuroNER, to overcome these limitations. This new system incorporates context embeddings through forward and backward n-grams without using sentence boundaries. Our context-enhanced de-identification (CEDI) system captures dependencies over sentence boundaries and bypasses the sentence boundary detection problem altogether. We enhanced this system with deep affix features and an attention mechanism to capture the pertinent parts of the input. The CEDI system outperforms NeuroNER on the 2006 i2b2 de-identification challenge dataset, the 2014 i2b2 shared task de-identification dataset, and the 2016 CEGS N-GRID de-identification dataset (p<0.01). All datasets comprise narrative clinical reports in English but contain different note types varying from discharge summaries to psychiatric notes. Enhancing CEDI with deep affix features and the attention mechanism further increased performance.
A Bayesian Network Scoring Metric That Is Based On Globally Uniform Parameter Priors
Dec 12, 2012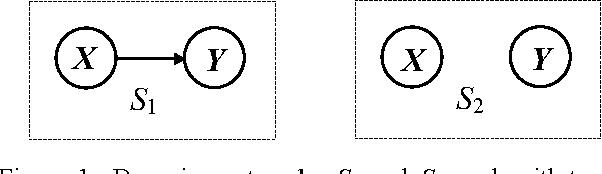
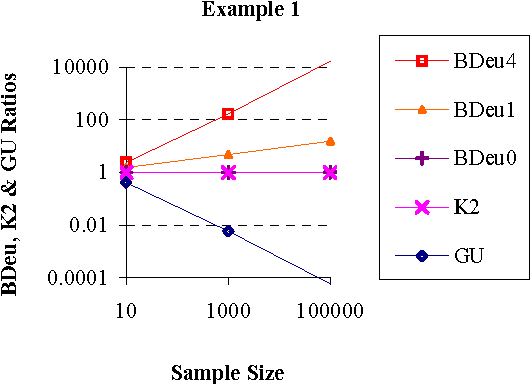
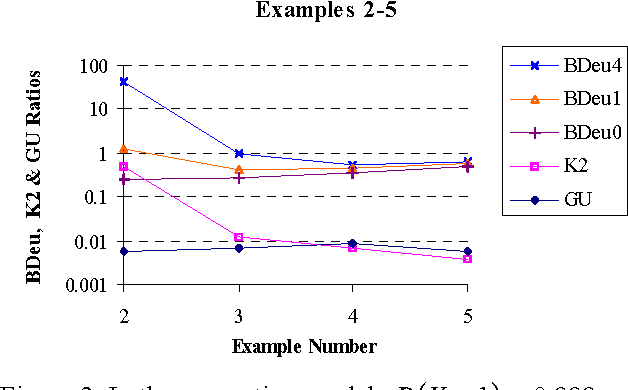
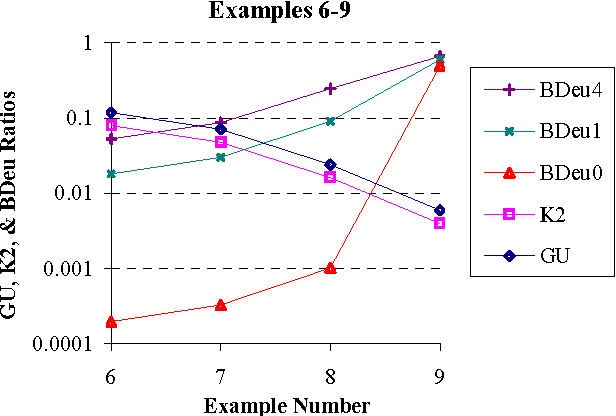
We introduce a new Bayesian network (BN) scoring metric called the Global Uniform (GU) metric. This metric is based on a particular type of default parameter prior. Such priors may be useful when a BN developer is not willing or able to specify domain-specific parameter priors. The GU parameter prior specifies that every prior joint probability distribution P consistent with a BN structure S is considered to be equally likely. Distribution P is consistent with S if P includes just the set of independence relations defined by S. We show that the GU metric addresses some undesirable behavior of the BDeu and K2 Bayesian network scoring metrics, which also use particular forms of default parameter priors. A closed form formula for computing GU for special classes of BNs is derived. Efficiently computing GU for an arbitrary BN remains an open problem.