 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graphs: Opportunities and Challenges
Mar 24, 2023With the explosive growth of artificial intelligence (AI) and big data, it has become vitally important to organize and represent the enormous volume of knowledge appropriately. As graph data, knowledge graphs accumulate and convey knowledge of the real world. It has been well-recognized that knowledge graphs effectively represent complex information; hence, they rapidly gain the attention of academia and industry in recent years. Thus to develop a deeper understanding of knowledge graphs, this paper presents a systematic overview of this field. Specifically, we focus on the opportunities and challenges of knowledge graphs. We first review the opportunities of knowledge graphs in terms of two aspects: (1) AI systems built upon knowledge graphs; (2) potential application fields of knowledge graphs. Then, we thoroughly discuss severe technical challenges in this field, such as knowledge graph embeddings, knowledge acquisition, knowledge graph completion, knowledge fusion, and knowledge reasoning. We expect that this survey will shed new light on future research and the development of knowledge graphs.
Combination of PCA with SMOTE Resampling to Boost the Prediction Rate in Lung Cancer Dataset
Mar 08, 2014

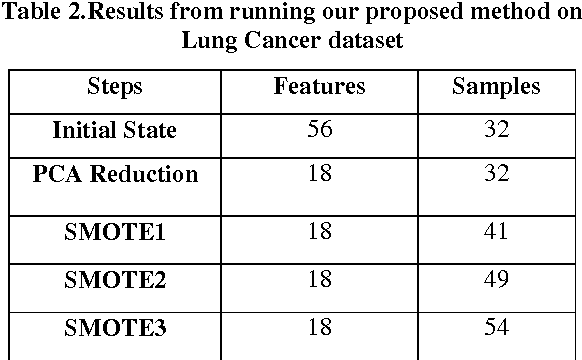
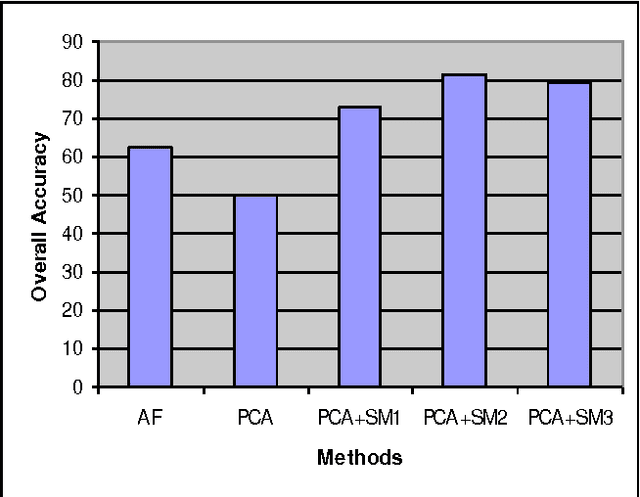
Classification algorithms are unable to make reliable models on the datasets with huge sizes. These datasets contain many irrelevant and redundant features that mislead the classifiers. Furthermore, many huge datasets have imbalanced class distribution which leads to bias over majority class in the classification process. In this paper combination of unsupervised dimensionality reduction methods with resampling is proposed and the results are tested on Lung-Cancer dataset. In the first step PCA is applied on Lung-Cancer dataset to compact the dataset and eliminate irrelevant features and in the second step SMOTE resampling is carried out to balance the class distribution and increase the variety of sample domain. Finally, Naive Bayes classifier is applied on the resulting dataset and the results are compared and evaluation metrics are calculated. The experiments show the effectiveness of the proposed method across four evaluation metrics: Overall accuracy, False Positive Rate, Precision, Recall.
* 6 pages. arXiv admin note: text overlap with arXiv:1106.1813, arXiv:1001.1446 by other authors
A Hybrid Feature Selection Method to Improve Performance of a Group of Classification Algorithms
Mar 08, 2014
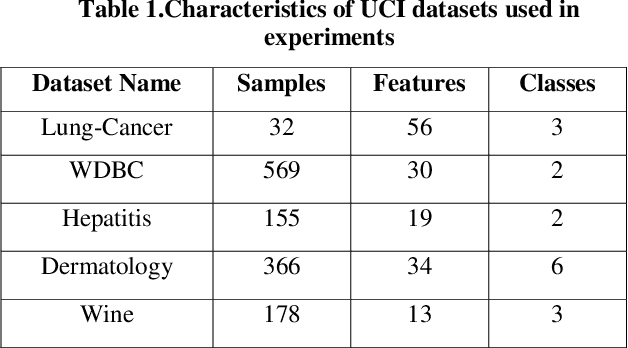
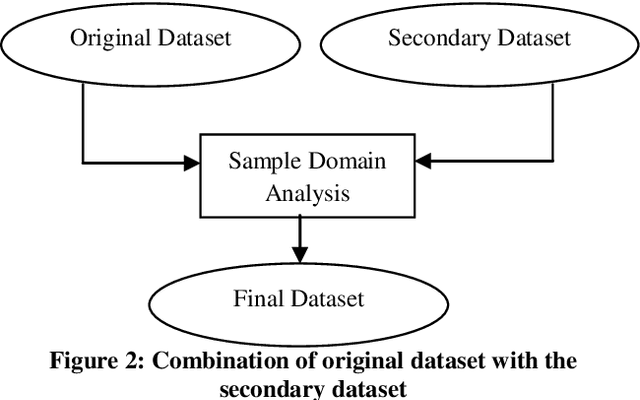
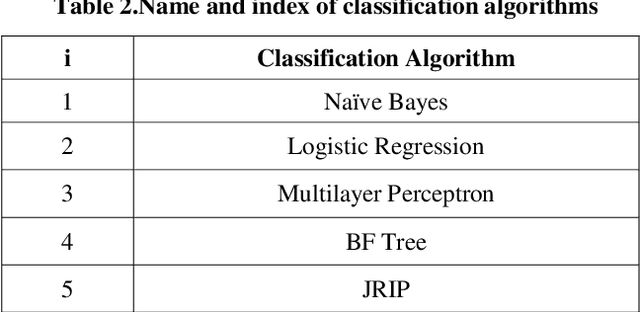
In this paper a hybrid feature selection method is proposed which takes advantages of wrapper subset evaluation with a lower cost and improves the performance of a group of classifiers. The method uses combination of sample domain filtering and resampling to refine the sample domain and two feature subset evaluation methods to select reliable features. This method utilizes both feature space and sample domain in two phases. The first phase filters and resamples the sample domain and the second phase adopts a hybrid procedure by information gain, wrapper subset evaluation and genetic search to find the optimal feature space. Experiments carried out on different types of datasets from UCI Repository of Machine Learning databases and the results show a rise in the average performance of five classifiers (Naive Bayes, Logistic, Multilayer Perceptron, Best First Decision Tree and JRIP) simultaneously and the classification error for these classifiers decreases considerably. The experiments also show that this method outperforms other feature selection methods with a lower cost.
* 8 pages. arXiv admin note: substantial text overlap with arXiv:1403.1946; and text overlap with arXiv:1106.1813 by other authors
Improving Performance of a Group of Classification Algorithms Using Resampling and Feature Selection
Mar 08, 2014
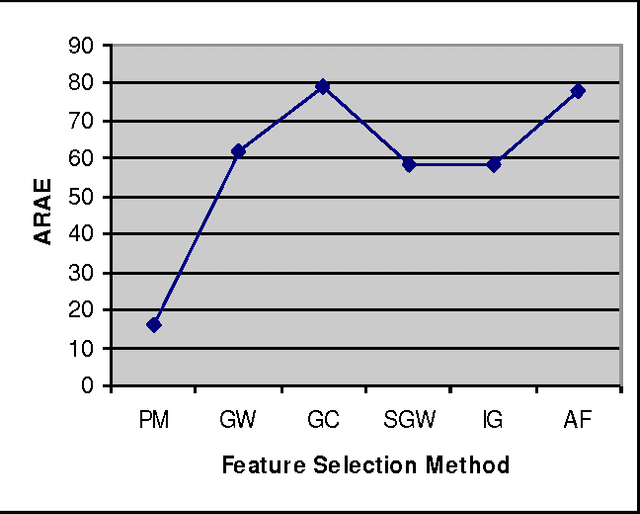
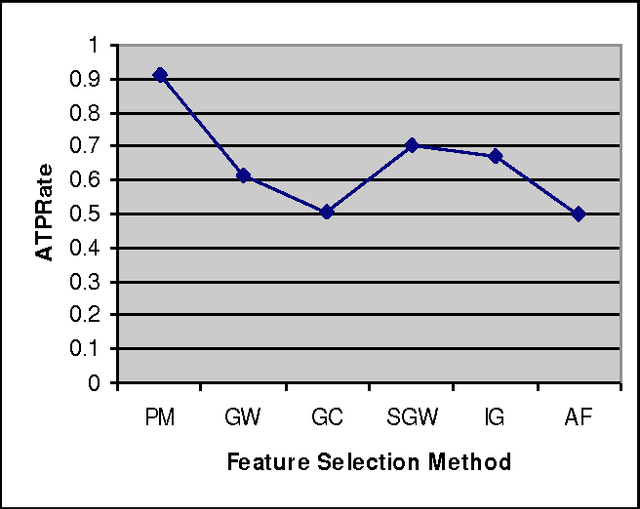
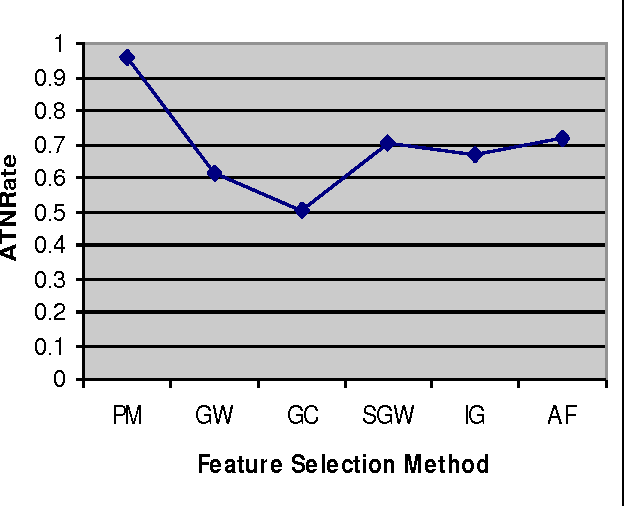
In recent years the importance of finding a meaningful pattern from huge datasets has become more challenging. Data miners try to adopt innovative methods to face this problem by applying feature selection methods. In this paper we propose a new hybrid method in which we use a combination of resampling, filtering the sample domain and wrapper subset evaluation method with genetic search to reduce dimensions of Lung-Cancer dataset that we received from UCI Repository of Machine Learning databases. Finally, we apply some well- known classification algorithms (Na\"ive Bayes, Logistic, Multilayer Perceptron, Best First Decision Tree and JRIP) to the resulting dataset and compare the results and prediction rates before and after the application of our feature selection method on that dataset. The results show a substantial progress in the average performance of five classification algorithms simultaneously and the classification error for these classifiers decreases considerably. The experiments also show that this method outperforms other feature selection methods with a lower cost.
* 7 pages