 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombination of PCA with SMOTE Resampling to Boost the Prediction Rate in Lung Cancer Dataset
Paper and Code
Mar 08, 2014

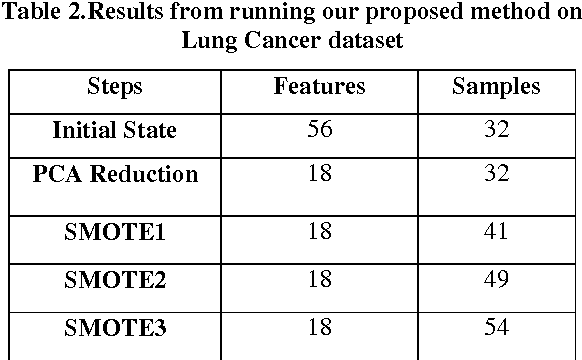
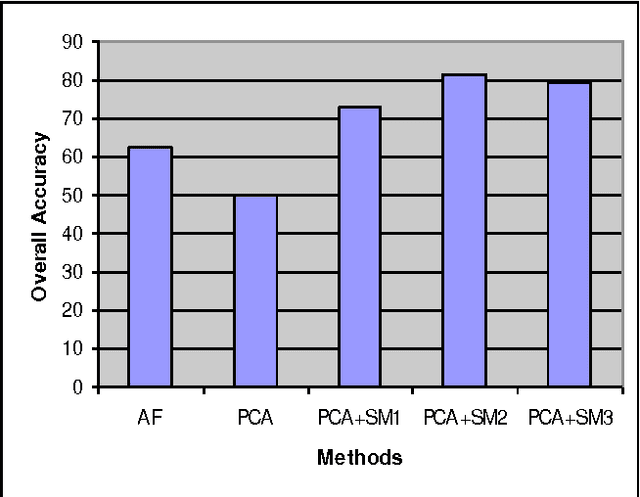
Classification algorithms are unable to make reliable models on the datasets with huge sizes. These datasets contain many irrelevant and redundant features that mislead the classifiers. Furthermore, many huge datasets have imbalanced class distribution which leads to bias over majority class in the classification process. In this paper combination of unsupervised dimensionality reduction methods with resampling is proposed and the results are tested on Lung-Cancer dataset. In the first step PCA is applied on Lung-Cancer dataset to compact the dataset and eliminate irrelevant features and in the second step SMOTE resampling is carried out to balance the class distribution and increase the variety of sample domain. Finally, Naive Bayes classifier is applied on the resulting dataset and the results are compared and evaluation metrics are calculated. The experiments show the effectiveness of the proposed method across four evaluation metrics: Overall accuracy, False Positive Rate, Precision, Recall.