 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Feature Selection Method to Improve Performance of a Group of Classification Algorithms
Mar 08, 2014
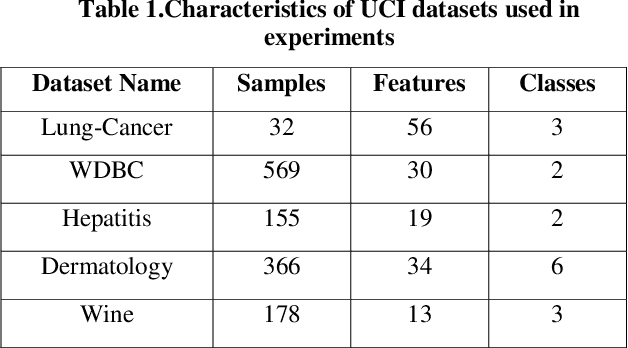
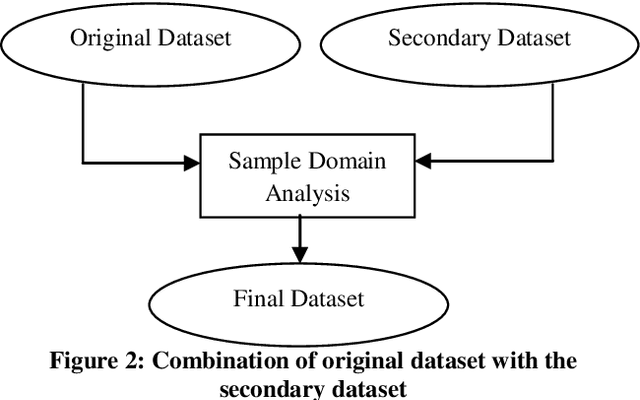
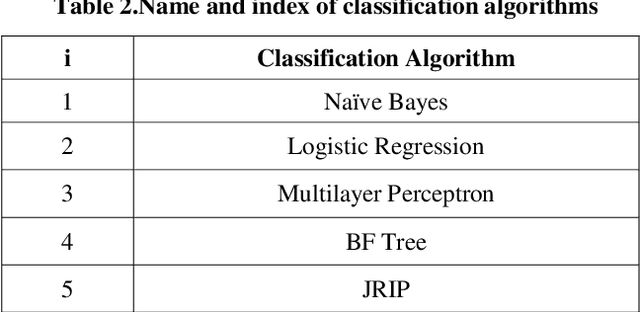
In this paper a hybrid feature selection method is proposed which takes advantages of wrapper subset evaluation with a lower cost and improves the performance of a group of classifiers. The method uses combination of sample domain filtering and resampling to refine the sample domain and two feature subset evaluation methods to select reliable features. This method utilizes both feature space and sample domain in two phases. The first phase filters and resamples the sample domain and the second phase adopts a hybrid procedure by information gain, wrapper subset evaluation and genetic search to find the optimal feature space. Experiments carried out on different types of datasets from UCI Repository of Machine Learning databases and the results show a rise in the average performance of five classifiers (Naive Bayes, Logistic, Multilayer Perceptron, Best First Decision Tree and JRIP) simultaneously and the classification error for these classifiers decreases considerably. The experiments also show that this method outperforms other feature selection methods with a lower cost.
* 8 pages. arXiv admin note: substantial text overlap with arXiv:1403.1946; and text overlap with arXiv:1106.1813 by other authors
Improving Performance of a Group of Classification Algorithms Using Resampling and Feature Selection
Mar 08, 2014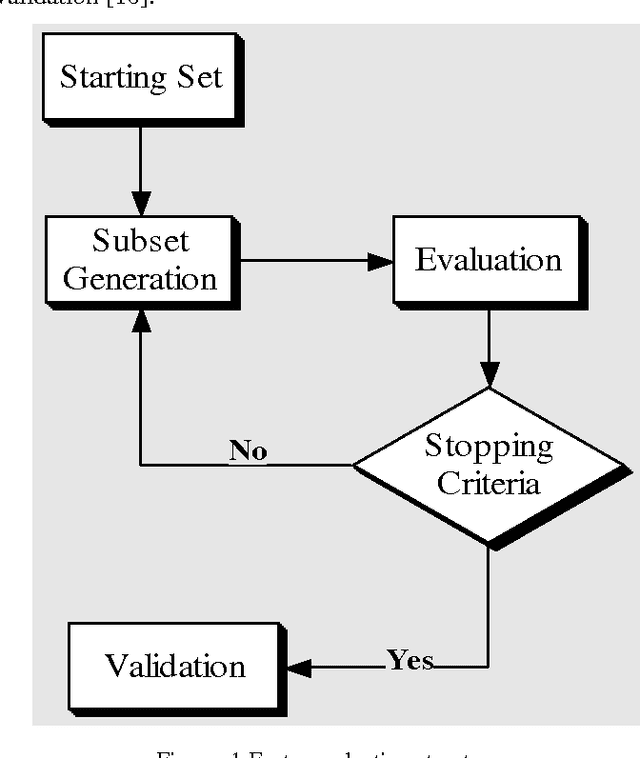
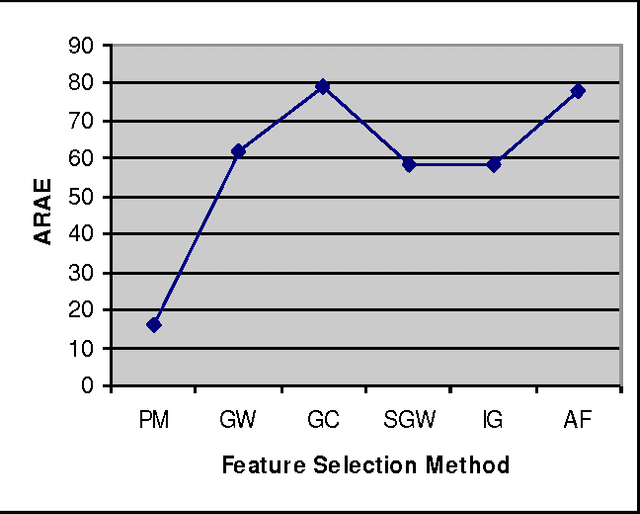
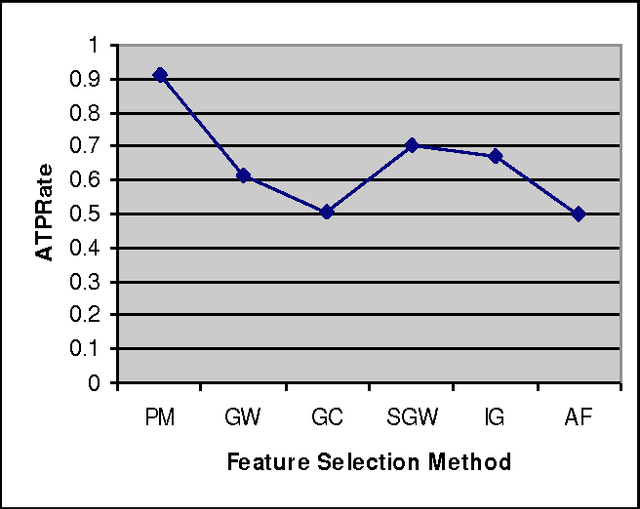
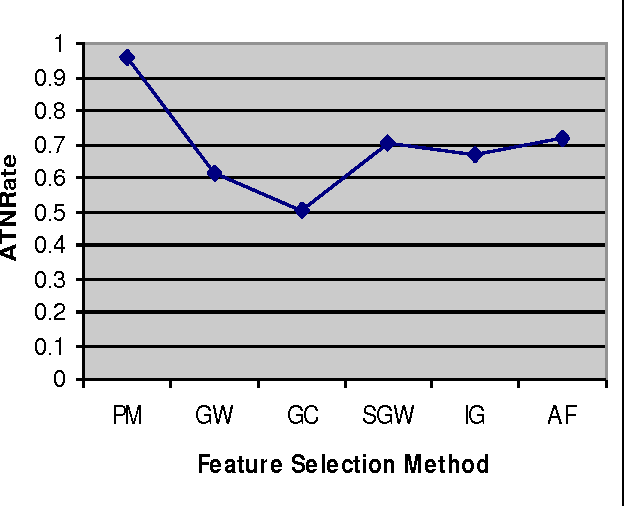
In recent years the importance of finding a meaningful pattern from huge datasets has become more challenging. Data miners try to adopt innovative methods to face this problem by applying feature selection methods. In this paper we propose a new hybrid method in which we use a combination of resampling, filtering the sample domain and wrapper subset evaluation method with genetic search to reduce dimensions of Lung-Cancer dataset that we received from UCI Repository of Machine Learning databases. Finally, we apply some well- known classification algorithms (Na\"ive Bayes, Logistic, Multilayer Perceptron, Best First Decision Tree and JRIP) to the resulting dataset and compare the results and prediction rates before and after the application of our feature selection method on that dataset. The results show a substantial progress in the average performance of five classification algorithms simultaneously and the classification error for these classifiers decreases considerably. The experiments also show that this method outperforms other feature selection methods with a lower cost.
* 7 pages