 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Inter-Layer Functional Mappings of Deep Learning Models
Jul 09, 2019
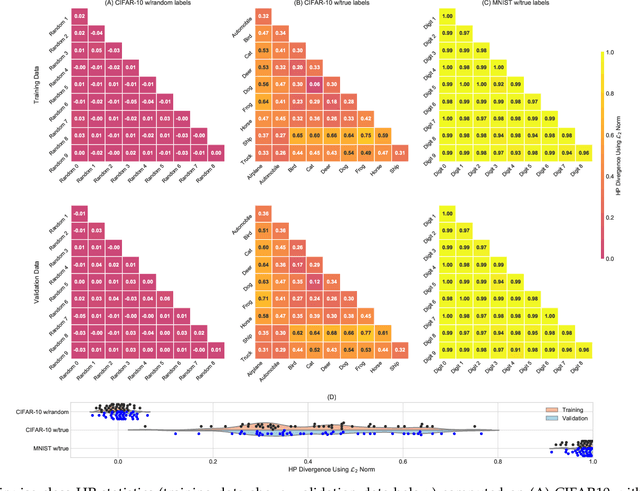
Deep learning architectures have demonstrated state-of-the-art performance for object classification and have become ubiquitous in commercial products. These methods are often applied without understanding (a) the difficulty of a classification task given the input data, and (b) how a specific deep learning architecture transforms that data. To answer (a) and (b), we illustrate the utility of a multivariate nonparametric estimator of class separation, the Henze-Penrose (HP) statistic, in the original as well as layer-induced representations. Given an $N$-class problem, our contribution defines the $C(N,2)$ combinations of HP statistics as a sample from a distribution of class-pair separations. This allows us to characterize the distributional change to class separation induced at each layer of the model. Fisher permutation tests are used to detect statistically significant changes within a model. By comparing the HP statistic distributions between layers, one can statistically characterize: layer adaptation during training, the contribution of each layer to the classification task, and the presence or absence of consistency between training and validation data. This is demonstrated for a simple deep neural network using CIFAR10 with random-labels, CIFAR10, and MNIST datasets.