 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Weigh Waste: A Physics-Informed Multimodal Fusion Framework and Large-Scale Dataset for Commercial and Industrial Applications
Mar 03, 2026Accurate weight estimation of commercial and industrial waste is important for efficient operations, yet image-based estimation remains difficult because similar-looking objects may have different densities, and the visible size changes with camera distance. Addressing this problem, we propose Multimodal Weight Predictor (MWP) framework that estimates waste weight by combining RGB images with physics-informed metadata, including object dimensions, camera distance, and camera height. We also introduce Waste-Weight-10K, a real-world dataset containing 10,421 synchronized image-metadata collected from logistics and recycling sites. The dataset covers 11 waste categories and a wide weight range from 3.5 to 3,450 kg. Our model uses a Vision Transformer for visual features and a dedicated metadata encoder for geometric and category information, combining them with Stacked Mutual Attention Fusion that allows visual and physical cues guide each other. This helps the model manage perspective effects and link objects to material properties. To ensure stable performance across the wide weight range, we train the model using Mean Squared Logarithmic Error. On the test set, the proposed method achieves 88.06 kg Mean Absolute Error (MAE), 6.39% Mean Absolute Percentage Error (MAPE), and an R2 coefficient of 0.9548. The model shows strong accuracy for light objects in the 0-100 kg range with 2.38 kg MAE and 3.1% MAPE, maintaining reliable performance for heavy waste in the 1000-2000 kg range with 11.1% MAPE. Finally, we incorporate a physically grounded explanation module using Shapley Additive Explanations (SHAP) and a large language model to provide clear, human-readable explanations for each prediction.
A Source-Free Approach for Domain Adaptation via Multiview Image Transformation and Latent Space Consistency
Jan 28, 2026Domain adaptation (DA) addresses the challenge of transferring knowledge from a source domain to a target domain where image data distributions may differ. Existing DA methods often require access to source domain data, adversarial training, or complex pseudo-labeling techniques, which are computationally expensive. To address these challenges, this paper introduces a novel source-free domain adaptation method. It is the first approach to use multiview augmentation and latent space consistency techniques to learn domain-invariant features directly from the target domain. Our method eliminates the need for source-target alignment or pseudo-label refinement by learning transferable representations solely from the target domain by enforcing consistency between multiple augmented views in the latent space. Additionally, the method ensures consistency in the learned features by generating multiple augmented views of target domain data and minimizing the distance between their feature representations in the latent space. We also introduce a ConvNeXt-based encoder and design a loss function that combines classification and consistency objectives to drive effective adaptation directly from the target domain. The proposed model achieves an average classification accuracy of 90. 72\%, 84\%, and 97. 12\% in Office-31, Office-Home and Office-Caltech datasets, respectively. Further evaluations confirm that our study improves existing methods by an average classification accuracy increment of +1.23\%, +7.26\%, and +1.77\% on the respective datasets.
ReFRM3D: A Radiomics-enhanced Fused Residual Multiparametric 3D Network with Multi-Scale Feature Fusion for Glioma Characterization
Dec 27, 2025Gliomas are among the most aggressive cancers, characterized by high mortality rates and complex diagnostic processes. Existing studies on glioma diagnosis and classification often describe issues such as high variability in imaging data, inadequate optimization of computational resources, and inefficient segmentation and classification of gliomas. To address these challenges, we propose novel techniques utilizing multi-parametric MRI data to enhance tumor segmentation and classification efficiency. Our work introduces the first-ever radiomics-enhanced fused residual multiparametric 3D network (ReFRM3D) for brain tumor characterization, which is based on a 3D U-Net architecture and features multi-scale feature fusion, hybrid upsampling, and an extended residual skip mechanism. Additionally, we propose a multi-feature tumor marker-based classifier that leverages radiomic features extracted from the segmented regions. Experimental results demonstrate significant improvements in segmentation performance across the BraTS2019, BraTS2020, and BraTS2021 datasets, achieving high Dice Similarity Coefficients (DSC) of 94.04%, 92.68%, and 93.64% for whole tumor (WT), enhancing tumor (ET), and tumor core (TC) respectively in BraTS2019; 94.09%, 92.91%, and 93.84% in BraTS2020; and 93.70%, 90.36%, and 92.13% in BraTS2021.
Hallucination to Truth: A Review of Fact-Checking and Factuality Evaluation in Large Language Models
Aug 05, 2025Large Language Models (LLMs) are trained on vast and diverse internet corpora that often include inaccurate or misleading content. Consequently, LLMs can generate misinformation, making robust fact-checking essential. This review systematically analyzes how LLM-generated content is evaluated for factual accuracy by exploring key challenges such as hallucinations, dataset limitations, and the reliability of evaluation metrics. The review emphasizes the need for strong fact-checking frameworks that integrate advanced prompting strategies, domain-specific fine-tuning, and retrieval-augmented generation (RAG) methods. It proposes five research questions that guide the analysis of the recent literature from 2020 to 2025, focusing on evaluation methods and mitigation techniques. The review also discusses the role of instruction tuning, multi-agent reasoning, and external knowledge access via RAG frameworks. Key findings highlight the limitations of current metrics, the value of grounding outputs with validated external evidence, and the importance of domain-specific customization to improve factual consistency. Overall, the review underlines the importance of building LLMs that are not only accurate and explainable but also tailored for domain-specific fact-checking. These insights contribute to the advancement of research toward more trustworthy and context-aware language models.
GHTM: A Graph based Hybrid Topic Modeling Approach in Low-Resource Bengali Language
Aug 01, 2025Topic modeling is a Natural Language Processing (NLP) technique that is used to identify latent themes and extract topics from text corpora by grouping similar documents based on their most significant keywords. Although widely researched in English, topic modeling remains understudied in Bengali due to its morphological complexity, lack of adequate resources and initiatives. In this contribution, a novel Graph Convolutional Network (GCN) based model called GHTM (Graph-Based Hybrid Topic Model) is proposed. This model represents input vectors of documents as nodes in the graph, which GCN uses to produce semantically rich embeddings. The embeddings are then decomposed using Non-negative Matrix Factorization (NMF) to get the topical representations of the underlying themes of the text corpus. This study compares the proposed model against a wide range of Bengali topic modeling techniques, from traditional methods such as LDA, LSA, and NMF to contemporary frameworks such as BERTopic and Top2Vec on three Bengali datasets. The experimental results demonstrate the effectiveness of the proposed model by outperforming other models in topic coherence and diversity. In addition, we introduce a novel Bengali dataset called "NCTBText" sourced from Bengali textbook materials to enrich and diversify the predominantly newspaper-centric Bengali corpora.
A Novel Word Pair-based Gaussian Sentence Similarity Algorithm For Bengali Extractive Text Summarization
Nov 26, 2024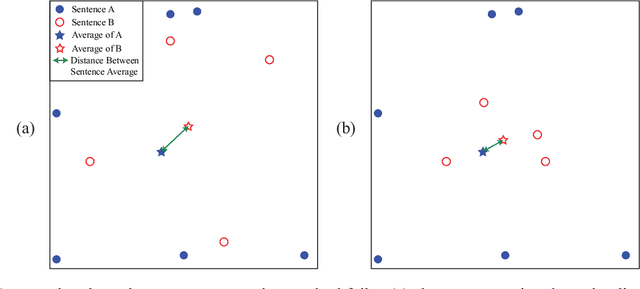

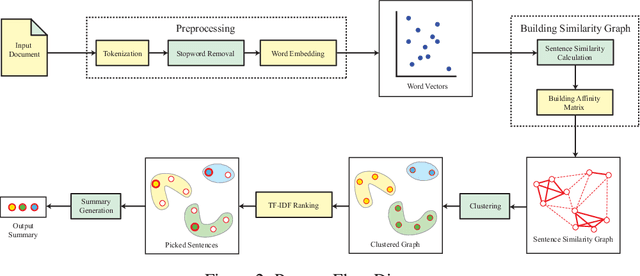

Extractive Text Summarization is the process of selecting the most representative parts of a larger text without losing any key information. Recent attempts at extractive text summarization in Bengali, either relied on statistical techniques like TF-IDF or used naive sentence similarity measures like the word averaging technique. All of these strategies suffer from expressing semantic relationships correctly. Here, we propose a novel Word pair-based Gaussian Sentence Similarity (WGSS) algorithm for calculating the semantic relation between two sentences. WGSS takes the geometric means of individual Gaussian similarity values of word embedding vectors to get the semantic relationship between sentences. It compares two sentences on a word-to-word basis which rectifies the sentence representation problem faced by the word averaging method. The summarization process extracts key sentences by grouping semantically similar sentences into clusters using the Spectral Clustering algorithm. After clustering, we use TF-IDF ranking to pick the best sentence from each cluster. The proposed method is validated using four different datasets, and it outperformed other recent models by 43.2\% on average ROUGE scores (ranging from 2.5\% to 95.4\%). It is also experimented on other low-resource languages i.e. Turkish, Marathi, and Hindi language, where we find that the proposed method performs as similar as Bengali for these languages. In addition, a new high-quality Bengali dataset is curated which contains 250 articles and a pair of summaries for each of them. We believe this research is a crucial addition to Bengali Natural Language Processing (NLP) research and it can easily be extended into other low-resource languages. We made the implementation of the proposed model and data public on \href{https://github.com/FMOpee/WGSS}{https://github.com/FMOpee/WGSS}.
Performance Analysis of Deep Autoencoder and NCA Dimensionality Reduction Techniques with KNN, ENN and SVM Classifiers
Dec 24, 2019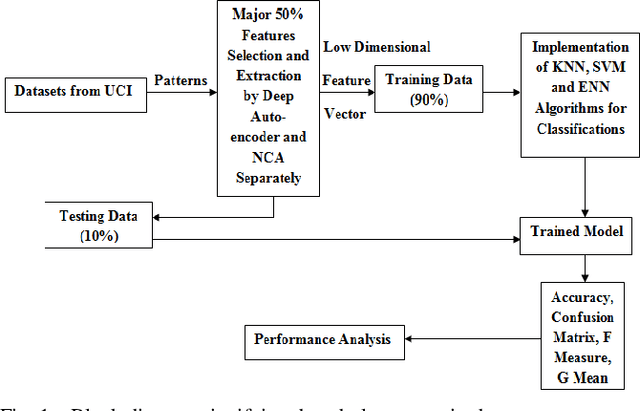
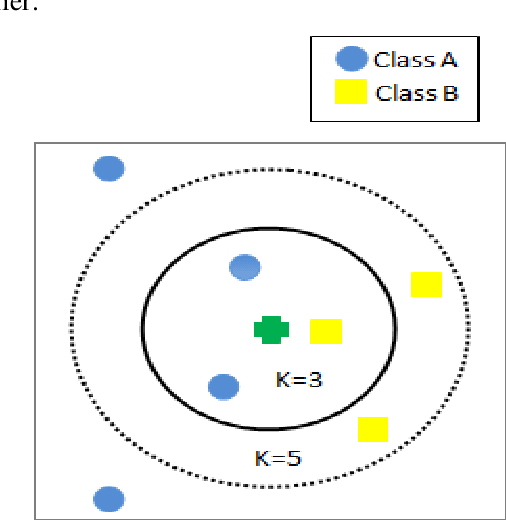

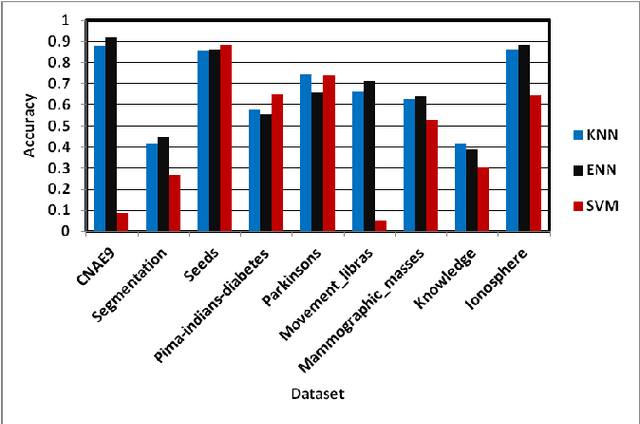
The central aim of this paper is to implement Deep Autoencoder and Neighborhood Components Analysis (NCA) dimensionality reduction methods in Matlab and to observe the application of these algorithms on nine unlike datasets from UCI machine learning repository. These datasets are CNAE9, Movement Libras, Pima Indians diabetes, Parkinsons, Knowledge, Segmentation, Seeds, Mammographic Masses, and Ionosphere. First of all, the dimension of these datasets has been reduced to fifty percent of their original dimension by selecting and extracting the most relevant and appropriate features or attributes using Deep Autoencoder and NCA dimensionality reduction techniques. Afterward, each dataset is classified applying K-Nearest Neighbors (KNN), Extended Nearest Neighbors (ENN) and Support Vector Machine (SVM) classification algorithms. All classification algorithms are developed in the Matlab environment. In each classification, the training test data ratio is always set to ninety percent: ten percent. Upon classification, variation between accuracies is observed and analyzed to find the degree of compatibility of each dimensionality reduction technique with each classifier and to evaluate each classifier performance on each dataset.
Modeling Spammer Behavior: Naïve Bayes vs. Artificial Neural Networks
Aug 19, 2010

Addressing the problem of spam emails in the Internet, this paper presents a comparative study on Na\"ive Bayes and Artificial Neural Networks (ANN) based modeling of spammer behavior. Keyword-based spam email filtering techniques fall short to model spammer behavior as the spammer constantly changes tactics to circumvent these filters. The evasive tactics that the spammer uses are themselves patterns that can be modeled to combat spam. It has been observed that both Na\"ive Bayes and ANN are best suitable for modeling spammer common patterns. Experimental results demonstrate that both of them achieve a promising detection rate of around 92%, which is considerably an improvement of performance compared to the keyword-based contemporary filtering approaches.
* 4 pages, 1 figure, 3 tables