 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Word Pair-based Gaussian Sentence Similarity Algorithm For Bengali Extractive Text Summarization
Paper and Code
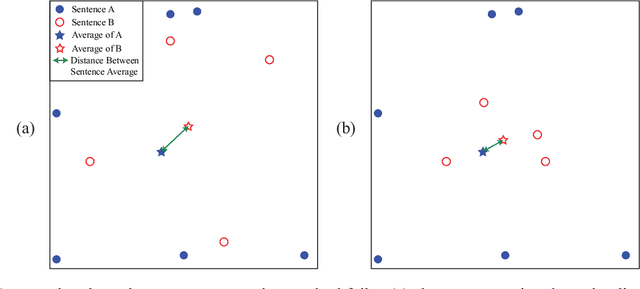

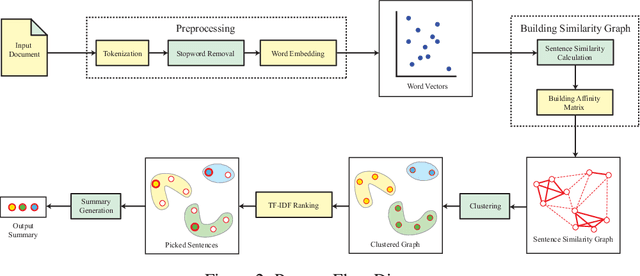

Extractive Text Summarization is the process of selecting the most representative parts of a larger text without losing any key information. Recent attempts at extractive text summarization in Bengali, either relied on statistical techniques like TF-IDF or used naive sentence similarity measures like the word averaging technique. All of these strategies suffer from expressing semantic relationships correctly. Here, we propose a novel Word pair-based Gaussian Sentence Similarity (WGSS) algorithm for calculating the semantic relation between two sentences. WGSS takes the geometric means of individual Gaussian similarity values of word embedding vectors to get the semantic relationship between sentences. It compares two sentences on a word-to-word basis which rectifies the sentence representation problem faced by the word averaging method. The summarization process extracts key sentences by grouping semantically similar sentences into clusters using the Spectral Clustering algorithm. After clustering, we use TF-IDF ranking to pick the best sentence from each cluster. The proposed method is validated using four different datasets, and it outperformed other recent models by 43.2\% on average ROUGE scores (ranging from 2.5\% to 95.4\%). It is also experimented on other low-resource languages i.e. Turkish, Marathi, and Hindi language, where we find that the proposed method performs as similar as Bengali for these languages. In addition, a new high-quality Bengali dataset is curated which contains 250 articles and a pair of summaries for each of them. We believe this research is a crucial addition to Bengali Natural Language Processing (NLP) research and it can easily be extended into other low-resource languages. We made the implementation of the proposed model and data public on \href{https://github.com/FMOpee/WGSS}{https://github.com/FMOpee/WGSS}.