 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Audio Feature Learning in Resource-Constrained Environments
Aug 25, 2023The scarcity of labelled data makes training Deep Neural Network (DNN) models in bioacoustic applications challenging. In typical bioacoustics applications, manually labelling the required amount of data can be prohibitively expensive. To effectively identify both new and current classes, DNN models must continue to learn new features from a modest amount of fresh data. Active Learning (AL) is an approach that can help with this learning while requiring little labelling effort. Nevertheless, the use of fixed feature extraction approaches limits feature quality, resulting in underutilization of the benefits of AL. We describe an AL framework that addresses this issue by incorporating feature extraction into the AL loop and refining the feature extractor after each round of manual annotation. In addition, we use raw audio processing rather than spectrograms, which is a novel approach. Experiments reveal that the proposed AL framework requires 14.3%, 66.7%, and 47.4% less labelling effort on benchmark audio datasets ESC-50, UrbanSound8k, and InsectWingBeat, respectively, for a large DNN model and similar savings on a microcontroller-based counterpart. Furthermore, we showcase the practical relevance of our study by incorporating data from conservation biology projects.
Pruning vs XNOR-Net: A Comprehensive Study of Deep Learning for Audio Classification on Edge-devices
Aug 29, 2021
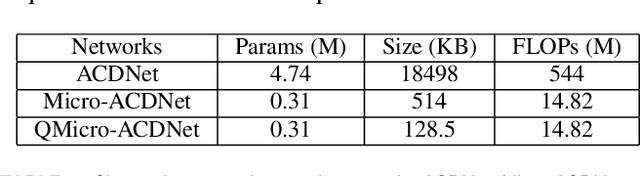
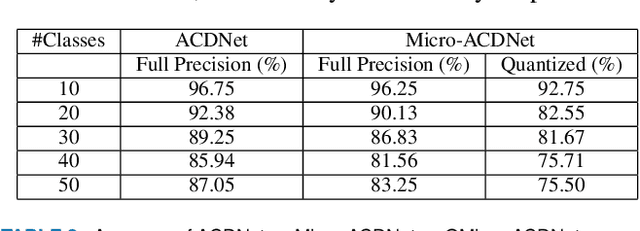
Deep Learning has celebrated resounding successes in many application areas of relevance to the Internet-of-Things, for example, computer vision and machine listening. To fully harness the power of deep leaning for the IoT, these technologies must ultimately be brought directly to the edge. The obvious challenge is that deep learning techniques can only be implemented on strictly resource-constrained edge devices if the models are radically downsized. This task relies on different model compression techniques, such as network pruning, quantization, and the recent advancement of XNOR-Net. This paper examines the suitability of these techniques for audio classification on microcontrollers. We present an XNOR-Net for end-to-end raw audio classification and a comprehensive empirical study comparing this approach with pruning-and-quantization methods. We show that raw audio classification with XNOR yields comparable performance to regular full precision networks for small numbers of classes while reducing memory requirements 32-fold and computation requirements 58-fold. However, as the number of classes increases significantly, performance degrades, and pruning-and-quantization based compression techniques take over as the preferred technique being able to satisfy the same space constraints but requiring about 8x more computation. We show that these insights are consistent between raw audio classification and image classification using standard benchmark sets. To the best of our knowledge, this is the first study applying XNOR to end-to-end audio classification and evaluating it in the context of alternative techniques. All code is publicly available on GitHub.
Environmental Sound Classification on the Edge: A Pipeline for Deep Acoustic Networks on Extremely Resource-Constrained Devices
Apr 06, 2021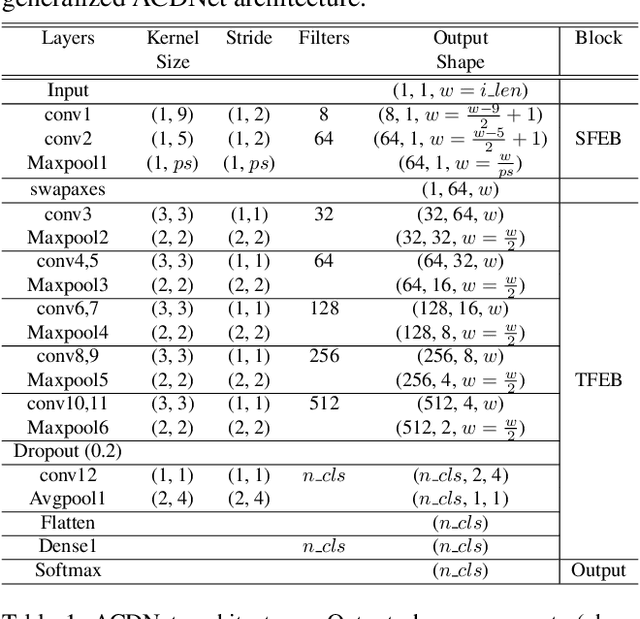
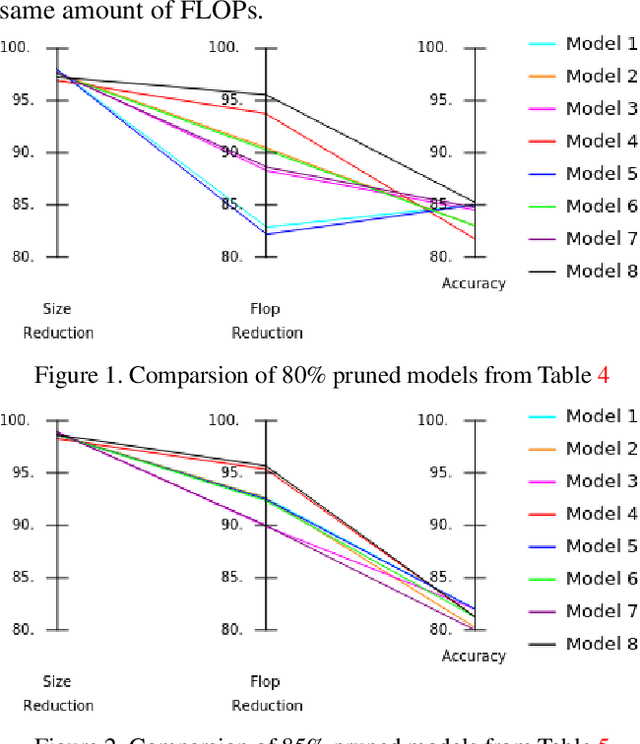
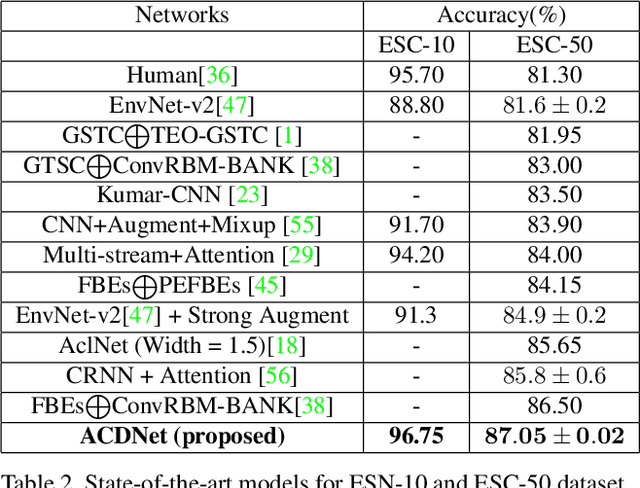
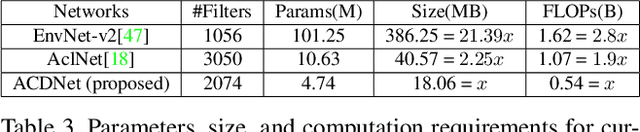
Significant efforts are being invested to bring state-of-the-art classification and recognition to edge devices with extreme resource constraints (memory, speed and lack of GPU support). Here, we demonstrate the first deep network for acoustic recognition that is small enough for an off-the-shelf microcrocontroller, yet achieves state-of-the-art performance on standard benchmarks. Rather than handcrafting a once-off solution, we present a universal pipeline that converts a large deep convolutional network automatically via compression and quantization into a network for resource-impoverished edge devices. After introducing ACDNet, which produces above state-of-the-art accuracy on ESC-10 (96.65%) and ESC-50 (87.1%), we describe the compression pipeline and show that it allows us to achieve 97.22% size reduction and 97.28% FLOP reduction while maintaining close to state-of-the-art accuracy (83.65% on ESC-50). We describe a successful implementation on a standard off-the-shelf microcontroller and, beyond laboratory benchmarks, report successful tests on real-world data sets.
Effect of Hyper-Parameter Optimization on the Deep Learning Model Proposed for Distributed Attack Detection in Internet of Things Environment
Jun 19, 2018

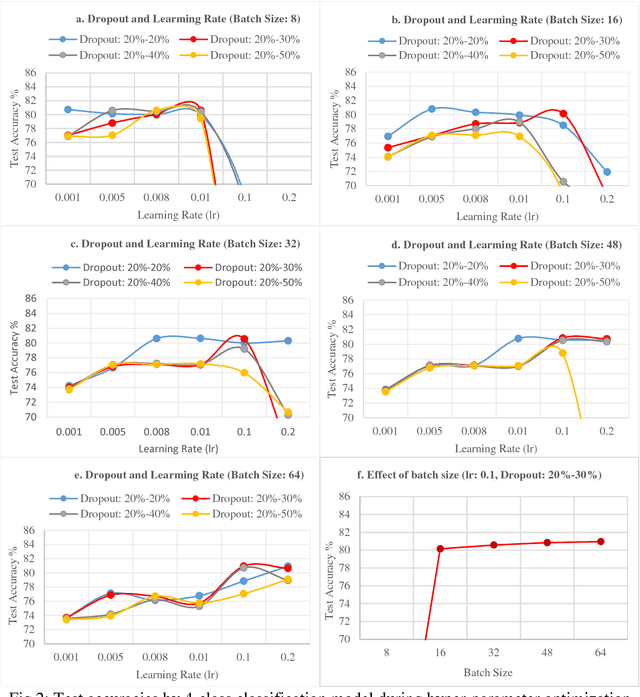

This paper studies the effect of various hyper-parameters and their selection for the best performance of the deep learning model proposed in [1] for distributed attack detection in the Internet of Things (IoT). The findings show that there are three hyper-parameters that have more influence on the best performance achieved by the model. As a consequence, this study shows that the model's accuracy as reported in the paper is not achievable, based on the best selections of parameters, which is also supported by another recent publication [2].