 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning vs XNOR-Net: A Comprehensive Study of Deep Learning for Audio Classification on Edge-devices
Paper and Code
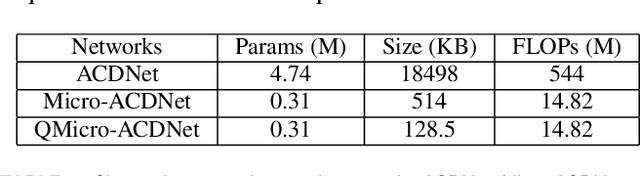
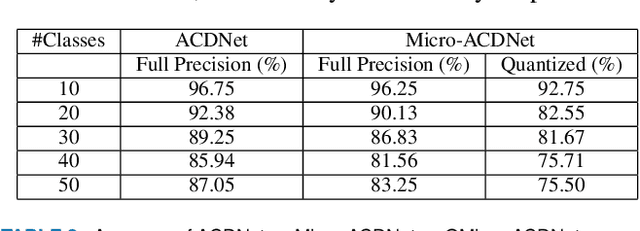
Deep Learning has celebrated resounding successes in many application areas of relevance to the Internet-of-Things, for example, computer vision and machine listening. To fully harness the power of deep leaning for the IoT, these technologies must ultimately be brought directly to the edge. The obvious challenge is that deep learning techniques can only be implemented on strictly resource-constrained edge devices if the models are radically downsized. This task relies on different model compression techniques, such as network pruning, quantization, and the recent advancement of XNOR-Net. This paper examines the suitability of these techniques for audio classification on microcontrollers. We present an XNOR-Net for end-to-end raw audio classification and a comprehensive empirical study comparing this approach with pruning-and-quantization methods. We show that raw audio classification with XNOR yields comparable performance to regular full precision networks for small numbers of classes while reducing memory requirements 32-fold and computation requirements 58-fold. However, as the number of classes increases significantly, performance degrades, and pruning-and-quantization based compression techniques take over as the preferred technique being able to satisfy the same space constraints but requiring about 8x more computation. We show that these insights are consistent between raw audio classification and image classification using standard benchmark sets. To the best of our knowledge, this is the first study applying XNOR to end-to-end audio classification and evaluating it in the context of alternative techniques. All code is publicly available on GitHub.