 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE-VLM: A Vision-Language-Driven Reinforcement Learning Framework for UAV Wildfire Tracking in a Physics-Grounded Fire Digital Twin
Jan 06, 2026Wildfire monitoring demands autonomous systems capable of reasoning under extreme visual degradation, rapidly evolving physical dynamics, and scarce real-world training data. Existing UAV navigation approaches rely on simplified simulators and supervised perception pipelines, and lack embodied agents interacting with physically realistic fire environments. We introduce FIRE-VLM, the first end-to-end vision-language model (VLM) guided reinforcement learning (RL) framework trained entirely within a high-fidelity, physics-grounded wildfire digital twin. Built from USGS Digital Elevation Model (DEM) terrain, LANDFIRE fuel inventories, and semi-physical fire-spread solvers, this twin captures terrain-induced runs, wind-driven acceleration, smoke plume occlusion, and dynamic fuel consumption. Within this environment, a PPO agent with dual-view UAV sensing is guided by a CLIP-style VLM. Wildfire-specific semantic alignment scores, derived from a single prompt describing active fire and smoke plumes, are integrated as potential-based reward shaping signals. Our contributions are: (1) a GIS-to-simulation pipeline for constructing wildfire digital twins; (2) a VLM-guided RL agent for UAV firefront tracking; and (3) a wildfire-aware reward design that combines physical terms with VLM semantics. Across five digital-twin evaluation tasks, our VLM-guided policy reduces time-to-detection by up to 6 times, increases time-in-FOV, and is, to our knowledge, the first RL-based UAV wildfire monitoring system demonstrated in kilometer-scale, physics-grounded digital-twin fires.
UAV-CROWD: Violent and non-violent crowd activity simulator from the perspective of UAV
Aug 13, 2022
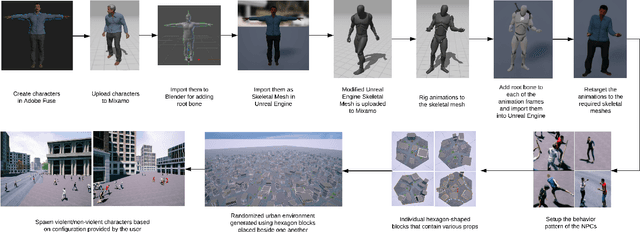
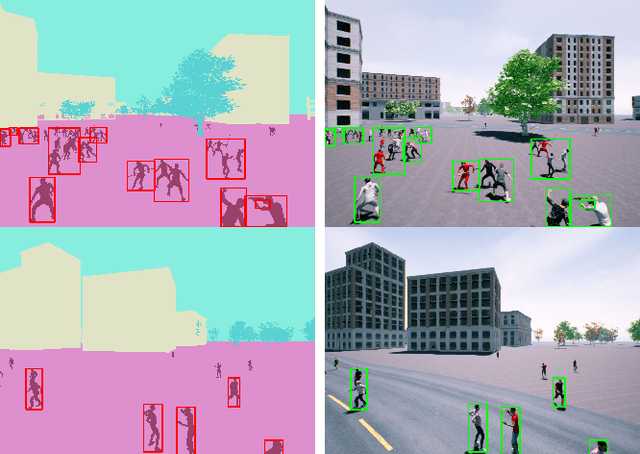
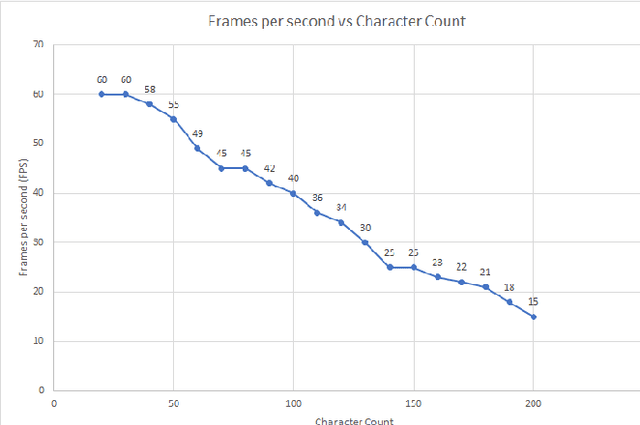
Unmanned Aerial Vehicle (UAV) has gained significant traction in the recent years, particularly the context of surveillance. However, video datasets that capture violent and non-violent human activity from aerial point-of-view is scarce. To address this issue, we propose a novel, baseline simulator which is capable of generating sequences of photo-realistic synthetic images of crowds engaging in various activities that can be categorized as violent or non-violent. The crowd groups are annotated with bounding boxes that are automatically computed using semantic segmentation. Our simulator is capable of generating large, randomized urban environments and is able to maintain an average of 25 frames per second on a mid-range computer with 150 concurrent crowd agents interacting with each other. We also show that when synthetic data from the proposed simulator is augmented with real world data, binary video classification accuracy is improved by 5% on average across two different models.