 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Speech Classification: IEEE Signal Processing Cup 2022 challenge
Dec 17, 2024The aim of this project is to implement and design arobust synthetic speech classifier for the IEEE Signal ProcessingCup 2022 challenge. Here, we learn a synthetic speech attributionmodel using the speech generated from various text-to-speech(TTS) algorithms as well as unknown TTS algorithms. Weexperiment with both the classical machine learning methodssuch as support vector machine, Gaussian mixture model, anddeep learning based methods such as ResNet, VGG16, and twoshallow end-to-end networks. We observe that deep learningbased methods with raw data demonstrate the best performance.
UAV-CROWD: Violent and non-violent crowd activity simulator from the perspective of UAV
Aug 13, 2022
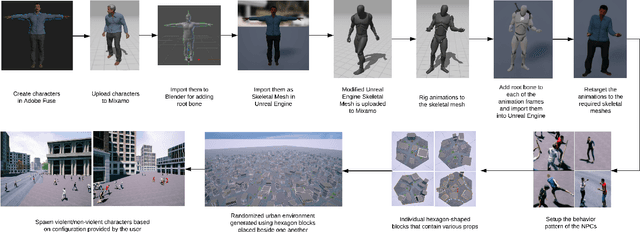
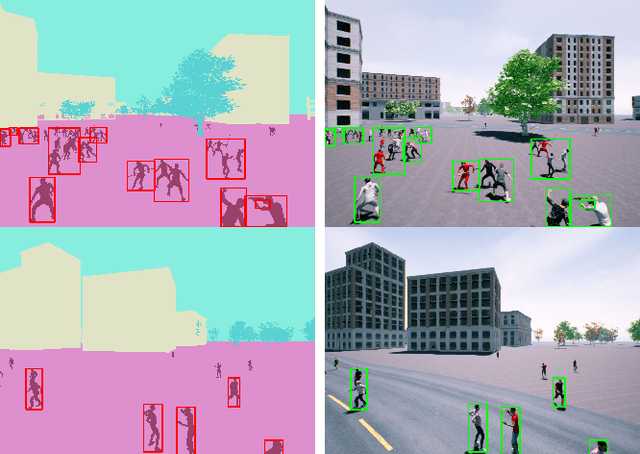
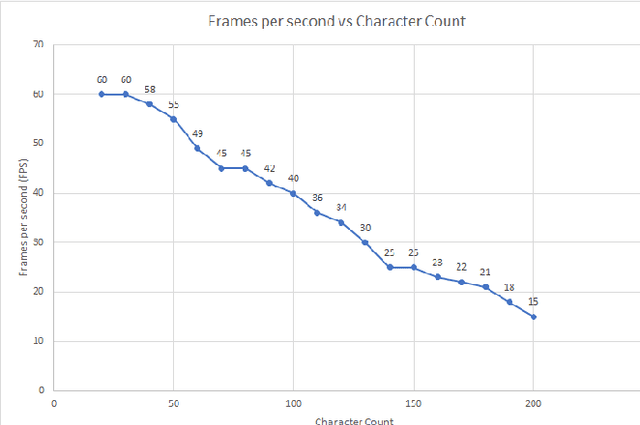
Unmanned Aerial Vehicle (UAV) has gained significant traction in the recent years, particularly the context of surveillance. However, video datasets that capture violent and non-violent human activity from aerial point-of-view is scarce. To address this issue, we propose a novel, baseline simulator which is capable of generating sequences of photo-realistic synthetic images of crowds engaging in various activities that can be categorized as violent or non-violent. The crowd groups are annotated with bounding boxes that are automatically computed using semantic segmentation. Our simulator is capable of generating large, randomized urban environments and is able to maintain an average of 25 frames per second on a mid-range computer with 150 concurrent crowd agents interacting with each other. We also show that when synthetic data from the proposed simulator is augmented with real world data, binary video classification accuracy is improved by 5% on average across two different models.