 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Port-Hamiltonian Neural Networks
Feb 04, 2025



In recent years, nonlinear dynamic system identification using artificial neural networks has garnered attention due to its manifold potential applications in virtually all branches of science and engineering. However, purely data-driven approaches often struggle with extrapolation and may yield physically implausible forecasts. Furthermore, the learned dynamics can exhibit instabilities, making it difficult to apply such models safely and robustly. This article proposes stable port-Hamiltonian neural networks, a machine learning architecture that incorporates the physical biases of energy conservation or dissipation while guaranteeing global Lyapunov stability of the learned dynamics. Evaluations with illustrative examples and real-world measurement data demonstrate the model's ability to generalize from sparse data, outperforming purely data-driven approaches and avoiding instability issues. In addition, the model's potential for data-driven surrogate modeling is highlighted in application to multi-physics simulation data.
TwinLab: a framework for data-efficient training of non-intrusive reduced-order models for digital twins
Jul 04, 2024


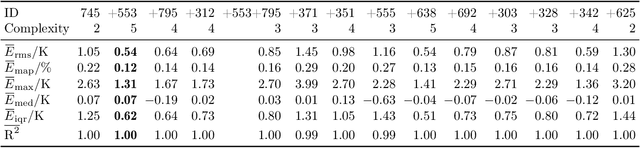
Purpose: Simulation-based digital twins represent an effort to provide high-accuracy real-time insights into operational physical processes. However, the computation time of many multi-physical simulation models is far from real-time. It might even exceed sensible time frames to produce sufficient data for training data-driven reduced-order models. This study presents TwinLab, a framework for data-efficient, yet accurate training of neural-ODE type reduced-order models with only two data sets. Design/methodology/approach: Correlations between test errors of reduced-order models and distinct features of corresponding training data are investigated. Having found the single best data sets for training, a second data set is sought with the help of similarity and error measures to enrich the training process effectively. Findings: Adding a suitable second training data set in the training process reduces the test error by up to 49% compared to the best base reduced-order model trained only with one data set. Such a second training data set should at least yield a good reduced-order model on its own and exhibit higher levels of dissimilarity to the base training data set regarding the respective excitation signal. Moreover, the base reduced-order model should have elevated test errors on the second data set. The relative error of the time series ranges from 0.18% to 0.49%. Prediction speed-ups of up to a factor of 36,000 are observed. Originality: The proposed computational framework facilitates the automated, data-efficient extraction of non-intrusive reduced-order models for digital twins from existing simulation models, independent of the simulation software.
Autonomous Cooking with Digital Twin Methodology
Sep 07, 2022

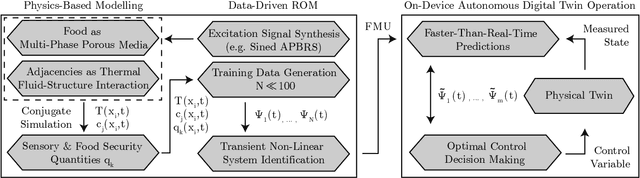
This work introduces the concept of an autonomous cooking process based on Digital Twin method- ology. It proposes a hybrid approach of physics-based full order simulations followed by a data-driven system identification process with low errors. It makes faster-than-real-time simulations of Digital Twins feasible on a device level, without the need for cloud or high-performance computing. The concept is universally applicable to various physical processes.
Physics-based Digital Twins for Autonomous Thermal Food Processing: Efficient, Non-intrusive Reduced-order Modeling
Sep 07, 2022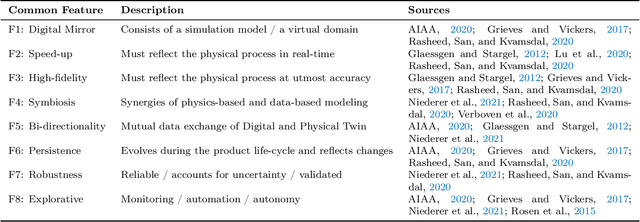
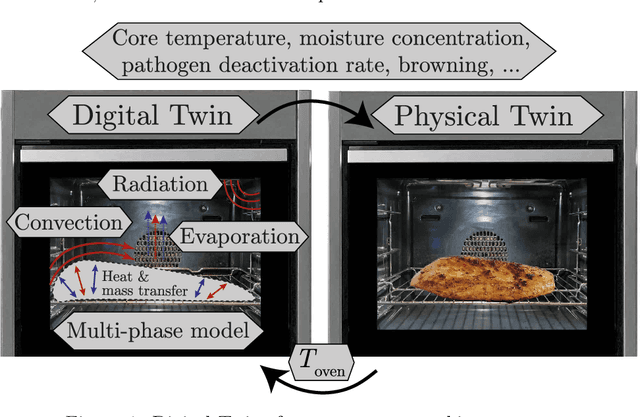

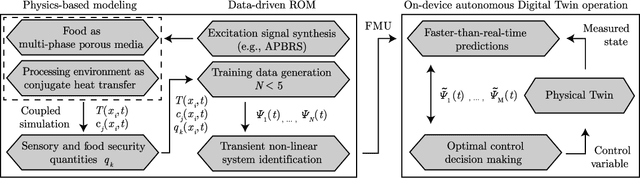
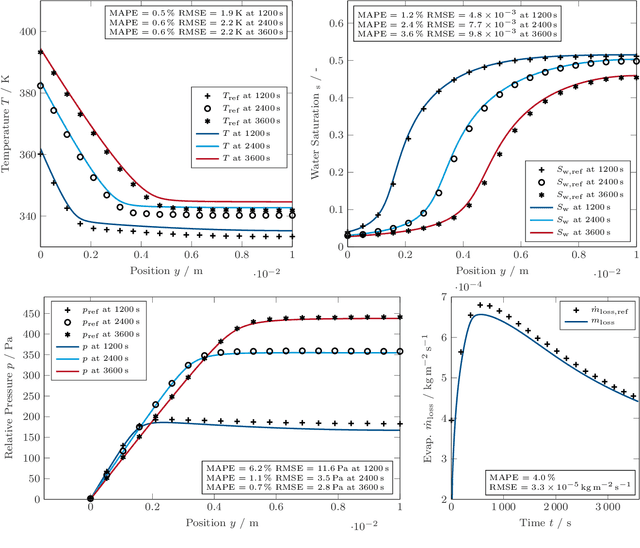
One possible way of making thermal processing controllable is to gather real-time information on the product's current state. Often, sensory equipment cannot capture all relevant information easily or at all. Digital Twins close this gap with virtual probes in real-time simulations, synchronized with the process. This paper proposes a physics-based, data-driven Digital Twin framework for autonomous food processing. We suggest a lean Digital Twin concept that is executable at the device level, entailing minimal computational load, data storage, and sensor data requirements. This study focuses on a parsimonious experimental design for training non-intrusive reduced-order models (ROMs) of a thermal process. A correlation ($R=-0.76$) between a high standard deviation of the surface temperatures in the training data and a low root mean square error in ROM testing enables efficient selection of training data. The mean test root mean square error of the best ROM is less than 1 Kelvin (0.2 % mean average percentage error) on representative test sets. Simulation speed-ups of Sp $\approx$ 1.8E4 allow on-device model predictive control. The proposed Digital Twin framework is designed to be applicable within the industry. Typically, non-intrusive reduced-order modeling is required as soon as the modeling of the process is performed in software, where root-level access to the solver is not provided, such as commercial simulation software. The data-driven training of the reduced-order model is achieved with only one data set, as correlations are utilized to predict the training success a priori.