 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultifile Partitioning for Record Linkage and Duplicate Detection
Oct 08, 2021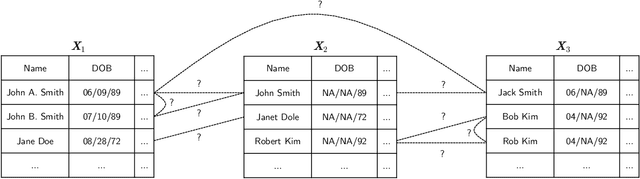
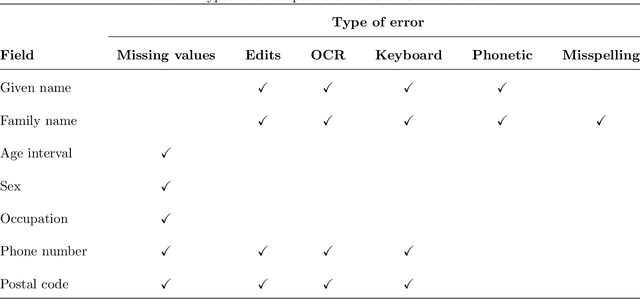
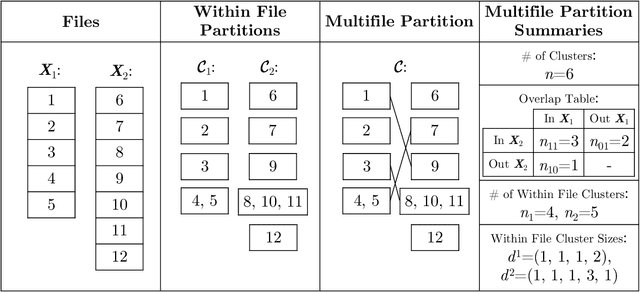
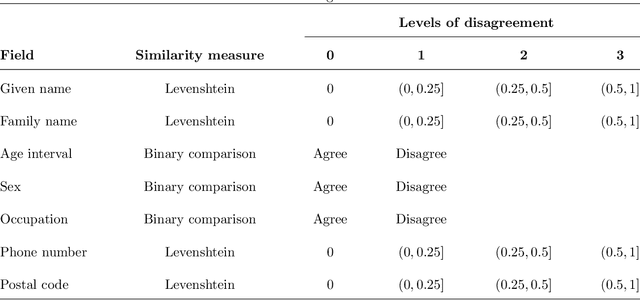
Merging datafiles containing information on overlapping sets of entities is a challenging task in the absence of unique identifiers, and is further complicated when some entities are duplicated in the datafiles. Most approaches to this problem have focused on linking two files assumed to be free of duplicates, or on detecting which records in a single file are duplicates. However, it is common in practice to encounter scenarios that fit somewhere in between or beyond these two settings. We propose a Bayesian approach for the general setting of multifile record linkage and duplicate detection. We use a novel partition representation to propose a structured prior for partitions that can incorporate prior information about the data collection processes of the datafiles in a flexible manner, and extend previous models for comparison data to accommodate the multifile setting. We also introduce a family of loss functions to derive Bayes estimates of partitions that allow uncertain portions of the partitions to be left unresolved. The performance of our proposed methodology is explored through extensive simulations. Code implementing the methodology is available at https://github.com/aleshing/multilink .
Least Ambiguous Set-Valued Classifiers with Bounded Error Levels
Sep 02, 2016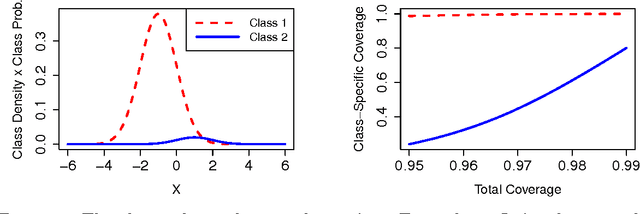
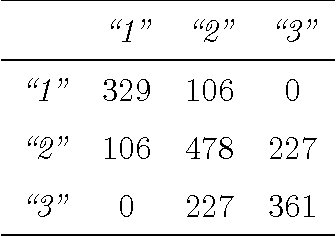
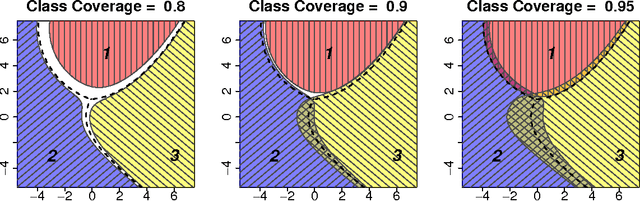
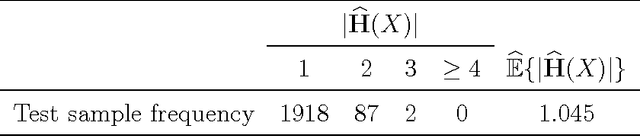
In most classification tasks there are observations that are ambiguous and therefore difficult to correctly label. Set-valued classification allows the classifiers to output a set of plausible labels rather than a single label, thereby giving a more appropriate and informative treatment to the labeling of ambiguous instances. We introduce a framework for multiclass set-valued classification, where the classifiers guarantee user-defined levels of coverage or confidence (the probability that the true label is contained in the set) while minimizing the ambiguity (the expected size of the output). We first derive oracle classifiers assuming the true distribution to be known. We show that the oracle classifiers are obtained from level sets of the functions that define the conditional probability of each class. Then we develop estimators with good asymptotic and finite sample properties. The proposed classifiers build on and refine many existing single-label classifiers. The optimal classifier can sometimes output the empty set. We provide two solutions to fix this issue that are suitable for various practical needs.
Bayesian Estimation of Bipartite Matchings for Record Linkage
Jan 25, 2016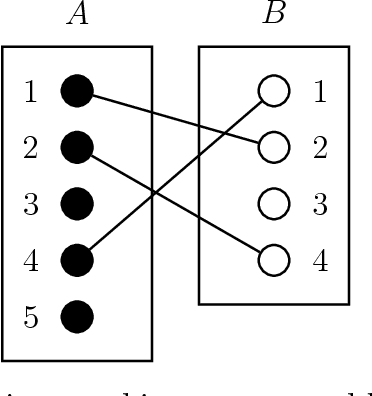


The bipartite record linkage task consists of merging two disparate datafiles containing information on two overlapping sets of entities. This is non-trivial in the absence of unique identifiers and it is important for a wide variety of applications given that it needs to be solved whenever we have to combine information from different sources. Most statistical techniques currently used for record linkage are derived from a seminal paper by Fellegi and Sunter (1969). These techniques usually assume independence in the matching statuses of record pairs to derive estimation procedures and optimal point estimators. We argue that this independence assumption is unreasonable and instead target a bipartite matching between the two datafiles as our parameter of interest. Bayesian implementations allow us to quantify uncertainty on the matching decisions and derive a variety of point estimators using different loss functions. We propose partial Bayes estimates that allow uncertain parts of the bipartite matching to be left unresolved. We evaluate our approach to record linkage using a variety of challenging scenarios and show that it outperforms the traditional methodology. We illustrate the advantages of our methods merging two datafiles on casualties from the civil war of El Salvador.
A Generalized Fellegi-Sunter Framework for Multiple Record Linkage With Application to Homicide Record Systems
Feb 06, 2013

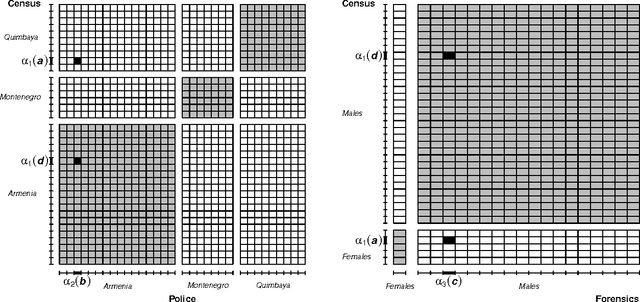
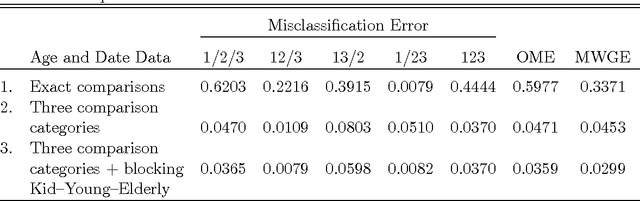
We present a probabilistic method for linking multiple datafiles. This task is not trivial in the absence of unique identifiers for the individuals recorded. This is a common scenario when linking census data to coverage measurement surveys for census coverage evaluation, and in general when multiple record-systems need to be integrated for posterior analysis. Our method generalizes the Fellegi-Sunter theory for linking records from two datafiles and its modern implementations. The multiple record linkage goal is to classify the record K-tuples coming from K datafiles according to the different matching patterns. Our method incorporates the transitivity of agreement in the computation of the data used to model matching probabilities. We use a mixture model to fit matching probabilities via maximum likelihood using the EM algorithm. We present a method to decide the record K-tuples membership to the subsets of matching patterns and we prove its optimality. We apply our method to the integration of three Colombian homicide record systems and we perform a simulation study in order to explore the performance of the method under measurement error and different scenarios. The proposed method works well and opens some directions for future research.