 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Neural Networks generated by Low Discrepancy Sequences
Mar 05, 2021


Artificial neural networks can be represented by paths. Generated as random walks on a dense network graph, we find that the resulting sparse networks allow for deterministic initialization and even weights with fixed sign. Such networks can be trained sparse from scratch, avoiding the expensive procedure of training a dense network and compressing it afterwards. Although sparse, weights are accessed as contiguous blocks of memory. In addition, enumerating the paths using deterministic low discrepancy sequences, for example the Sobol' sequence, amounts to connecting the layers of neural units by progressive permutations, which naturally avoids bank conflicts in parallel computer hardware. We demonstrate that the artificial neural networks generated by low discrepancy sequences can achieve an accuracy within reach of their dense counterparts at a much lower computational complexity.
Resource aware design of a deep convolutional-recurrent neural network for speech recognition through audio-visual sensor fusion
Mar 13, 2018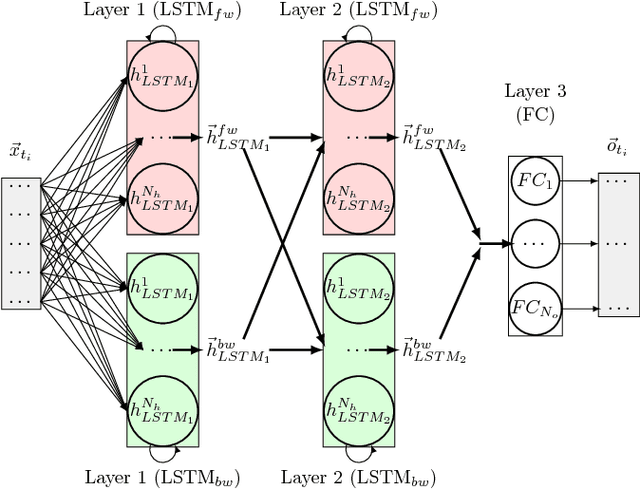
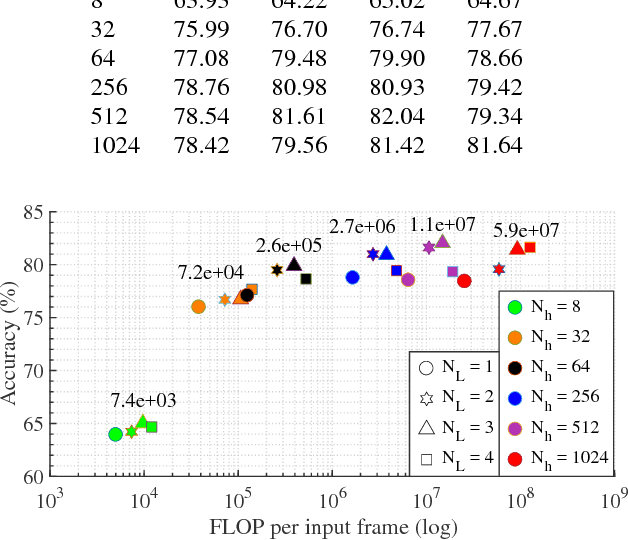
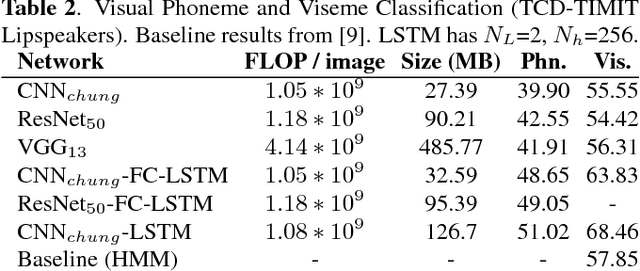
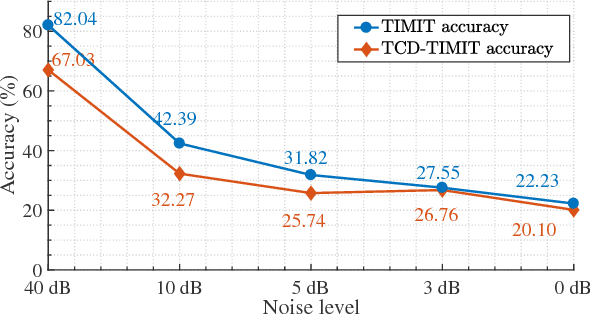
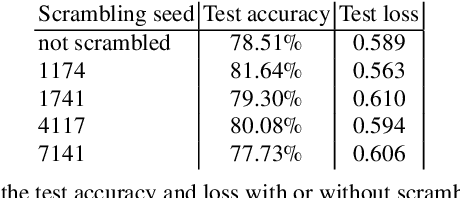
Today's Automatic Speech Recognition systems only rely on acoustic signals and often don't perform well under noisy conditions. Performing multi-modal speech recognition - processing acoustic speech signals and lip-reading video simultaneously - significantly enhances the performance of such systems, especially in noisy environments. This work presents the design of such an audio-visual system for Automated Speech Recognition, taking memory and computation requirements into account. First, a Long-Short-Term-Memory neural network for acoustic speech recognition is designed. Second, Convolutional Neural Networks are used to model lip-reading features. These are combined with an LSTM network to model temporal dependencies and perform automatic lip-reading on video. Finally, acoustic-speech and visual lip-reading networks are combined to process acoustic and visual features simultaneously. An attention mechanism ensures performance of the model in noisy environments. This system is evaluated on the TCD-TIMIT 'lipspeaker' dataset for audio-visual phoneme recognition with clean audio and with additive white noise at an SNR of 0dB. It achieves 75.70% and 58.55% phoneme accuracy respectively, over 14 percentage points better than the state-of-the-art for all noise levels.