 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource aware design of a deep convolutional-recurrent neural network for speech recognition through audio-visual sensor fusion
Paper and Code
Mar 13, 2018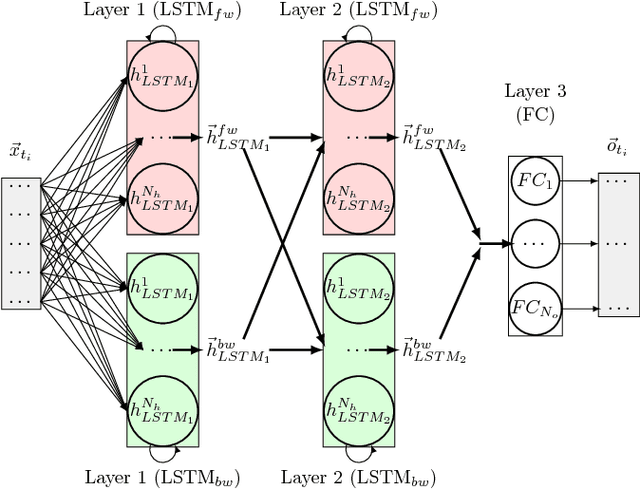
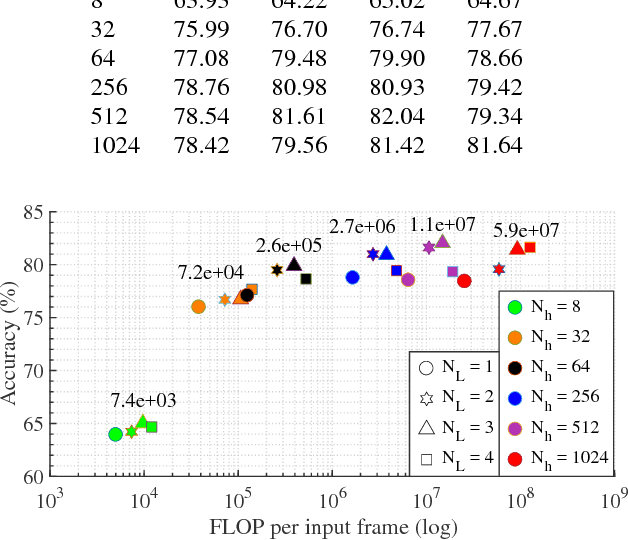
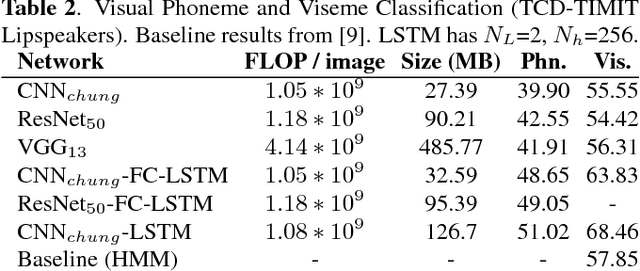
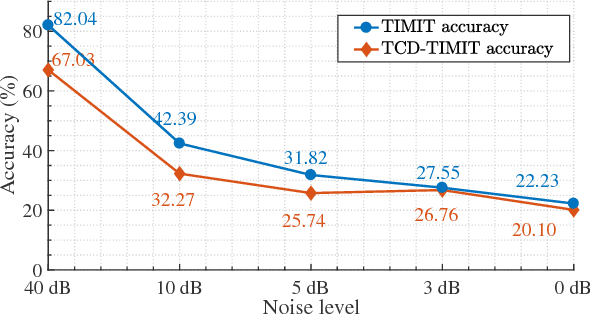
Today's Automatic Speech Recognition systems only rely on acoustic signals and often don't perform well under noisy conditions. Performing multi-modal speech recognition - processing acoustic speech signals and lip-reading video simultaneously - significantly enhances the performance of such systems, especially in noisy environments. This work presents the design of such an audio-visual system for Automated Speech Recognition, taking memory and computation requirements into account. First, a Long-Short-Term-Memory neural network for acoustic speech recognition is designed. Second, Convolutional Neural Networks are used to model lip-reading features. These are combined with an LSTM network to model temporal dependencies and perform automatic lip-reading on video. Finally, acoustic-speech and visual lip-reading networks are combined to process acoustic and visual features simultaneously. An attention mechanism ensures performance of the model in noisy environments. This system is evaluated on the TCD-TIMIT 'lipspeaker' dataset for audio-visual phoneme recognition with clean audio and with additive white noise at an SNR of 0dB. It achieves 75.70% and 58.55% phoneme accuracy respectively, over 14 percentage points better than the state-of-the-art for all noise levels.