 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free policy gradient for discrete-time mean-field control
Jan 16, 2026We study model-free policy learning for discrete-time mean-field control (MFC) problems with finite state space and compact action space. In contrast to the extensive literature on value-based methods for MFC, policy-based approaches remain largely unexplored due to the intrinsic dependence of transition kernels and rewards on the evolving population state distribution, which prevents the direct use of likelihood-ratio estimators of policy gradients from classical single-agent reinforcement learning. We introduce a novel perturbation scheme on the state-distribution flow and prove that the gradient of the resulting perturbed value function converges to the true policy gradient as the perturbation magnitude vanishes. This construction yields a fully model-free estimator based solely on simulated trajectories and an auxiliary estimate of the sensitivity of the state distribution. Building on this framework, we develop MF-REINFORCE, a model-free policy gradient algorithm for MFC, and establish explicit quantitative bounds on its bias and mean-squared error. Numerical experiments on representative mean-field control tasks demonstrate the effectiveness of the proposed approach.
Weighted Conditional Flow Matching
Jul 29, 2025Conditional flow matching (CFM) has emerged as a powerful framework for training continuous normalizing flows due to its computational efficiency and effectiveness. However, standard CFM often produces paths that deviate significantly from straight-line interpolations between prior and target distributions, making generation slower and less accurate due to the need for fine discretization at inference. Recent methods enhance CFM performance by inducing shorter and straighter trajectories but typically rely on computationally expensive mini-batch optimal transport (OT). Drawing insights from entropic optimal transport (EOT), we propose Weighted Conditional Flow Matching (W-CFM), a novel approach that modifies the classical CFM loss by weighting each training pair $(x, y)$ with a Gibbs kernel. We show that this weighting recovers the entropic OT coupling up to some bias in the marginals, and we provide the conditions under which the marginals remain nearly unchanged. Moreover, we establish an equivalence between W-CFM and the minibatch OT method in the large-batch limit, showing how our method overcomes computational and performance bottlenecks linked to batch size. Empirically, we test our method on unconditional generation on various synthetic and real datasets, confirming that W-CFM achieves comparable or superior sample quality, fidelity, and diversity to other alternative baselines while maintaining the computational efficiency of vanilla CFM.
Efficient Learning for Entropy-regularized Markov Decision Processes via Multilevel Monte Carlo
Mar 27, 2025
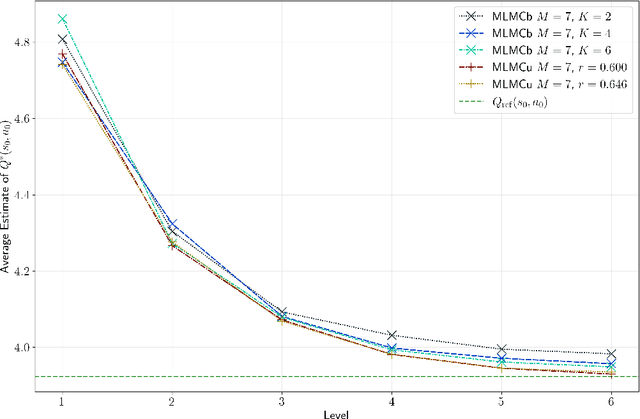
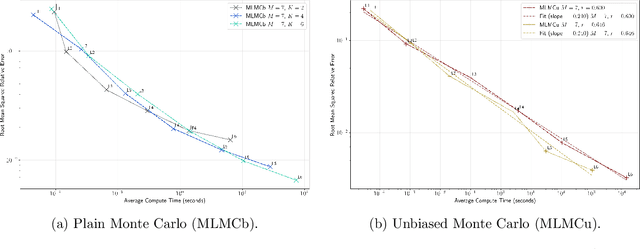
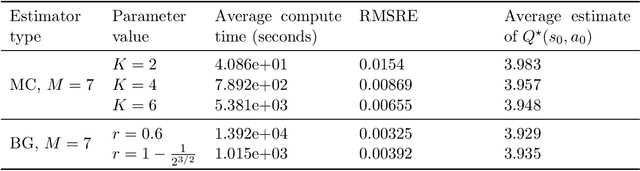
Designing efficient learning algorithms with complexity guarantees for Markov decision processes (MDPs) with large or continuous state and action spaces remains a fundamental challenge. We address this challenge for entropy-regularized MDPs with Polish state and action spaces, assuming access to a generative model of the environment. We propose a novel family of multilevel Monte Carlo (MLMC) algorithms that integrate fixed-point iteration with MLMC techniques and a generic stochastic approximation of the Bellman operator. We quantify the precise impact of the chosen approximate Bellman operator on the accuracy of the resulting MLMC estimator. Leveraging this error analysis, we show that using a biased plain MC estimate for the Bellman operator results in quasi-polynomial sample complexity, whereas an unbiased randomized multilevel approximation of the Bellman operator achieves polynomial sample complexity in expectation. Notably, these complexity bounds are independent of the dimensions or cardinalities of the state and action spaces, distinguishing our approach from existing algorithms whose complexities scale with the sizes of these spaces. We validate these theoretical performance guarantees through numerical experiments.
Partially Stochastic Infinitely Deep Bayesian Neural Networks
Feb 05, 2024



In this paper, we present Partially Stochastic Infinitely Deep Bayesian Neural Networks, a novel family of architectures that integrates partial stochasticity into the framework of infinitely deep neural networks. Our new class of architectures is designed to improve the limitations of existing architectures around computational efficiency at training and inference time. To do this, we leverage the advantages of partial stochasticity in the infinite-depth limit which include the benefits of full stochasticity e.g. robustness, uncertainty quantification, and memory efficiency, whilst improving their limitations around computational efficiency at training and inference time. We present a variety of architectural configurations, offering flexibility in network design including different methods for weight partition. We also provide mathematical guarantees on the expressivity of our models by establishing that our network family qualifies as Universal Conditional Distribution Approximators. Lastly, empirical evaluations across multiple tasks show that our proposed architectures achieve better downstream task performance and uncertainty quantification than their counterparts while being significantly more efficient.